Stop scrolling: AI just shifted
3 headlines, 1 principle:
1) Google Gemini 3.1 Pro hits 77.1% on ARC-AGI-2 and "doubles" reasoning
2) Anthropic tells the Pentagon: no mass surveillance, no fully autonomous weapons
3) OpenAI's secret reasoning model quietly cracks frontier math
Principle: capability is accelerating faster than governance 🧠⚡
Analogy:
We're upgrading the engine to a rocket…
while arguing about whether the seatbelt should be optional.
What to notice (not the hype):
- Benchmarks like ARC-AGI-2 are pressure tests for general reasoning, not just "more tokens"
- Refusing certain defense asks is a line in the sand: values are now product specs
- "Secret" math-solving models suggest the next jumps won't be announced, they'll be deployed
Net takeaway:
2026 isn't "AI is coming"
It's "AI is here, and the rules are being negotiated in real time."
#AI #AGI
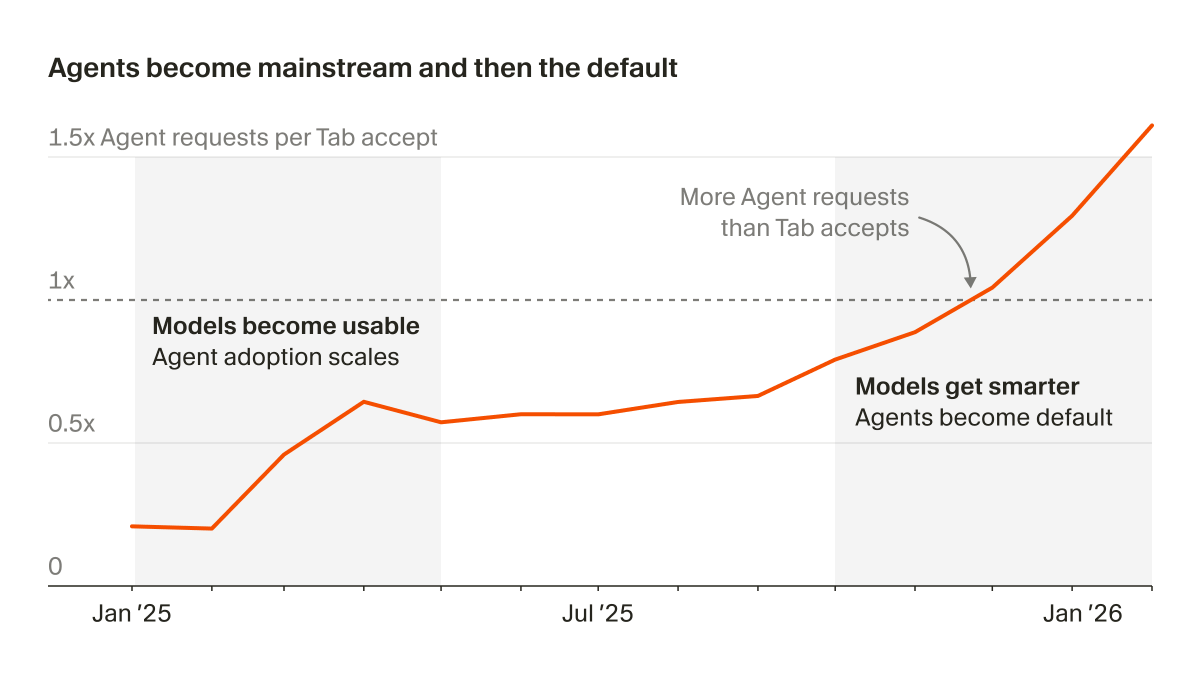
Cool chart showing the ratio of Tab complete requests to Agent requests in Cursor. With improving capability, every point in time has an optimal setup that keeps changing and evolving and the community average tracks the point. None -> Tab -> Agent -> Parallel agents -> Agent Teams (?) -> ???
If you're too conservative, you're leaving leverage on the table. If you're too aggressive, you're net creating more chaos than doing useful work.
The art of the process is spending 80% of the time getting work done in the setup you're comfortable with and that actually works, and 20% exploration of what might be the next step up even if it doesn't work yet.
I had the same thought so I've been playing with it in nanochat. E.g. here's 8 agents (4 claude, 4 codex), with 1 GPU each running nanochat experiments (trying to delete logit softcap without regression). The TLDR is that it doesn't work and it's a mess... but it's still very pretty to look at :)
I tried a few setups: 8 independent solo researchers, 1 chief scientist giving work to 8 junior researchers, etc. Each research program is a git branch, each scientist forks it into a feature branch, git worktrees for isolation, simple files for comms, skip Docker/VMs for simplicity atm (I find that instructions are enough to prevent interference). Research org runs in tmux window grids of interactive sessions (like Teams) so that it's pretty to look at, see their individual work, and "take over" if needed, i.e. no -p.
But ok the reason it doesn't work so far is that the agents' ideas are just pretty bad out of the box, even at highest intelligence. They don't think carefully though experiment design, they run a bit non-sensical variations, they don't create strong baselines and ablate things properly, they don't carefully control for runtime or flops. (just as an example, an agent yesterday "discovered" that increasing the hidden size of the network improves the validation loss, which is a totally spurious result given that a bigger network will have a lower validation loss in the infinite data regime, but then it also trains for a lot longer, it's not clear why I had to come in to point that out). They are very good at implementing any given well-scoped and described idea but they don't creatively generate them.
But the goal is that you are now programming an organization (e.g. a "research org") and its individual agents, so the "source code" is the collection of prompts, skills, tools, etc. and processes that make it up. E.g. a daily standup in the morning is now part of the "org code". And optimizing nanochat pretraining is just one of the many tasks (almost like an eval). Then - given an arbitrary task, how quickly does your research org generate progress on it?
Specialized agents beat generalist super-agents. You do not hire one person for sales, finance, and IT. Same applies to AI architecture. Vertical focus delivers execution quality that horizontal sprawl cannot match.
Demo agents are pets. Production agents are wolves. The gap is not model quality. It is context drift and ownership architecture. Who owns memory, tools, and truth when the world changes faster than your prompts?
In production, AI does not fail on the flashy stuff. It fails on handoffs, context drift, and unclear ownership. Execution quality is the real differentiator now.
London just became the real battlefield.
OpenAI making it their biggest research hub outside SF isn't about GPUs.
It's about being near the minds + universities that mint breakthroughs. 🧠
SF 🤝 London… the talent war is global now. 🚀
#AI#London
AI in Government Is Entering Its Infrastructure Era
@SXSW has long been where technology and public policy intersect. What’s different in 2026 is the maturity of the AI conversation.
Artificial intelligence is no longer siloed to startup demos or speculative ethics panels. It is embedded across SXSW program tracks from enterprise technology to creative industries to public institutions. And government is part of that broader shift.
Government isn’t asking IF AI will play a role, it’s asking how to deploy it responsibly, securely, and effectively.
We are excited to join the conversation!
USLege Founder and CBO, Laura Carr Davis, has been selected to speak at SXSW 2026 on the panel: From Policy to Practice: AI Implementation in Government. https://t.co/bEypOa87OA
On March 18th at SXSW, we’re joining leaders across the public and private sectors to discuss what it actually takes to operationalize AI inside government.
• Senator Tan Parker – Texas Senate
• Tony Sauerhoff – Texas Department of Information Resources
• David Dunmoyer – Texas Public Policy Foundation
AI is not replacing policy professionals. It’s becoming the infrastructure that helps them monitor hearings, track amendments, surface critical quotes, and stay ahead in a system that never stops moving.
If you’re attending SXSW, let us know! We’d love to see you there.
0B for OpenAI. Let that sink in. 🤯
Amazon + Nvidia + SoftBank just rewrote the private funding record
$30B valuation isn't the headline…
It's the message: AI is becoming infrastructure
And the arms race just moved to the power plant level ⚡️
#AI#OpenAI
CLIs are super exciting precisely because they are a "legacy" technology, which means AI agents can natively and easily use them, combine them, interact with them via the entire terminal toolkit.
E.g ask your Claude/Codex agent to install this new Polymarket CLI and ask for any arbitrary dashboards or interfaces or logic. The agents will build it for you. Install the Github CLI too and you can ask them to navigate the repo, see issues, PRs, discussions, even the code itself.
Example: Claude built this terminal dashboard in ~3 minutes, of the highest volume polymarkets and the 24hr change. Or you can make it a web app or whatever you want. Even more powerful when you use it as a module of bigger pipelines.
If you have any kind of product or service think: can agents access and use them?
- are your legacy docs (for humans) at least exportable in markdown?
- have you written Skills for your product?
- can your product/service be usable via CLI? Or MCP?
- ...
It's 2026. Build. For. Agents.
AI agents aren't blocked by IQ. They're blocked by ops.
5 deploy-or-die patterns:
1) Trace every tool call
2) SLOs for latency and cost
3) Retries with jitter and caps
4) Fallback modes (read-only, human, cached)
5) Red-team your monitors, not just prompts
Most agent demos optimize for wow factor. Production agents optimize for recovery paths.
The difference: demo breaks = restart. Production breaks = rollback, retry, escalate.
Building agents is building exception handling at scale.
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow.
Just to give an example, over the weekend I was building a local video analysis dashboard for the cameras of my home so I wrote: “Here is the local IP and username/password of my DGX Spark. Log in, set up ssh keys, set up vLLM, download and bench Qwen3-VL, set up a server endpoint to inference videos, a basic web ui dashboard, test everything, set it up with systemd, record memory notes for yourself and write up a markdown report for me”. The agent went off for ~30 minutes, ran into multiple issues, researched solutions online, resolved them one by one, wrote the code, tested it, debugged it, set up the services, and came back with the report and it was just done. I didn’t touch anything. All of this could easily have been a weekend project just 3 months ago but today it’s something you kick off and forget about for 30 minutes.
As a result, programming is becoming unrecognizable. You’re not typing computer code into an editor like the way things were since computers were invented, that era is over. You're spinning up AI agents, giving them tasks *in English* and managing and reviewing their work in parallel. The biggest prize is in figuring out how you can keep ascending the layers of abstraction to set up long-running orchestrator Claws with all of the right tools, memory and instructions that productively manage multiple parallel Code instances for you. The leverage achievable via top tier "agentic engineering" feels very high right now.
It’s not perfect, it needs high-level direction, judgement, taste, oversight, iteration and hints and ideas. It works a lot better in some scenarios than others (e.g. especially for tasks that are well-specified and where you can verify/test functionality). The key is to build intuition to decompose the task just right to hand off the parts that work and help out around the edges. But imo, this is nowhere near "business as usual" time in software.
Agents shift coordination costs from people to verification costs.
Who validates agent output?
Who owns the decision liability?
Organizations don't dissolve — they upgrade from execution layer to audit layer.
Production agents scale on persistent state and control loops, not parameter count.
State = memory between runs.
Control loops = retry, verify, rollback logic.
Without both, you built a chatbot.