Our work Midway Network has been accepted to #ICLR2026!
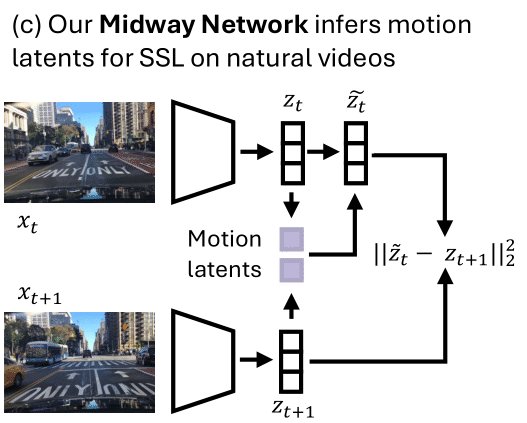
Animals learn to recognize objects and how they move just from observing the world. SSL on natural videos emulates “learning by observing” but only tackles recognition or motion, not both!
To address this gap, Midway Network is the first SSL architecture to learn both object recognition and motion understanding from natural videos via latent dynamics🧵
Can MLLMs actually track what's happening in a video?
Introducing VSTAT 🎯, our new benchmark for visual state tracking.
The tasks are simple: count cups, read typed words, count page flips. Humans solve them easily. MLLMs don't.
https://t.co/dgqhqeVuSv
🧵 [1/11]
🧠We introduce "Generative Recursive Reasoning"!
Recursive Reasoning Models like HRM, TRM, and Looped Transformers are deterministic — same input, same reasoning, every time. They collapse the entire space of plausible reasoning paths into a single attractor.
Our model GRAM (Generative Recursive reAsoning Models) turns recursion itself into a stochastic latent trajectory. Multiple hypotheses, alternative solution strategies, and inference-time scaling not just by depth, but by width — parallel trajectory sampling.
And here's the kicker: the same formulation that gives us conditional reasoning p(y|x) also makes GRAM a general generative model p(x).
With only 10M params:
• Sudoku-Extreme: 97.0% (TRM 87.4%)
• ARC-AGI-1: 52.0%
• ARC-AGI-2: 11.1%
• N-Queens coverage: 90%+
📄 Paper: https://t.co/JC7EyXYc9Y
🌐 Project page: https://t.co/LRT1dQiWLZ
w/
Junyeob Baek @JunyeobB (KAIST),
Mingyu Jo @pyross0000 (KAIST),
Minsu Kim @minsuuukim (KAIST & Mila),
Mengye Ren @mengyer (NYU),
Yoshua Bengio @Yoshua_Bengio (Mila),
Sungjin Ahn @SungjinAhn_ (KAIST)
As a rare non-academic note: I collected the recipes I made throughout my PhD and wrote + illustrated a cookbook/memoir!
“No time to cook this season” is a Little Forest inspired collection I wrote and illustrated for fun (hesitant to call it a cookbook since it’s mostly handwavey “recipes” but couldn’t find a better description 🤷♀️). Hope you can enjoy some peaceful art and stories as a little bedtime read 🥰
- Hardcover + digital copies can be found here: https://t.co/EYNKxNxEOc.
- To follow more of my art, you can visit my alias @jiayuestudio (ins: https://t.co/4ItPPQBTqz)
- (Let me know if I should print food art stickers too ☺️)
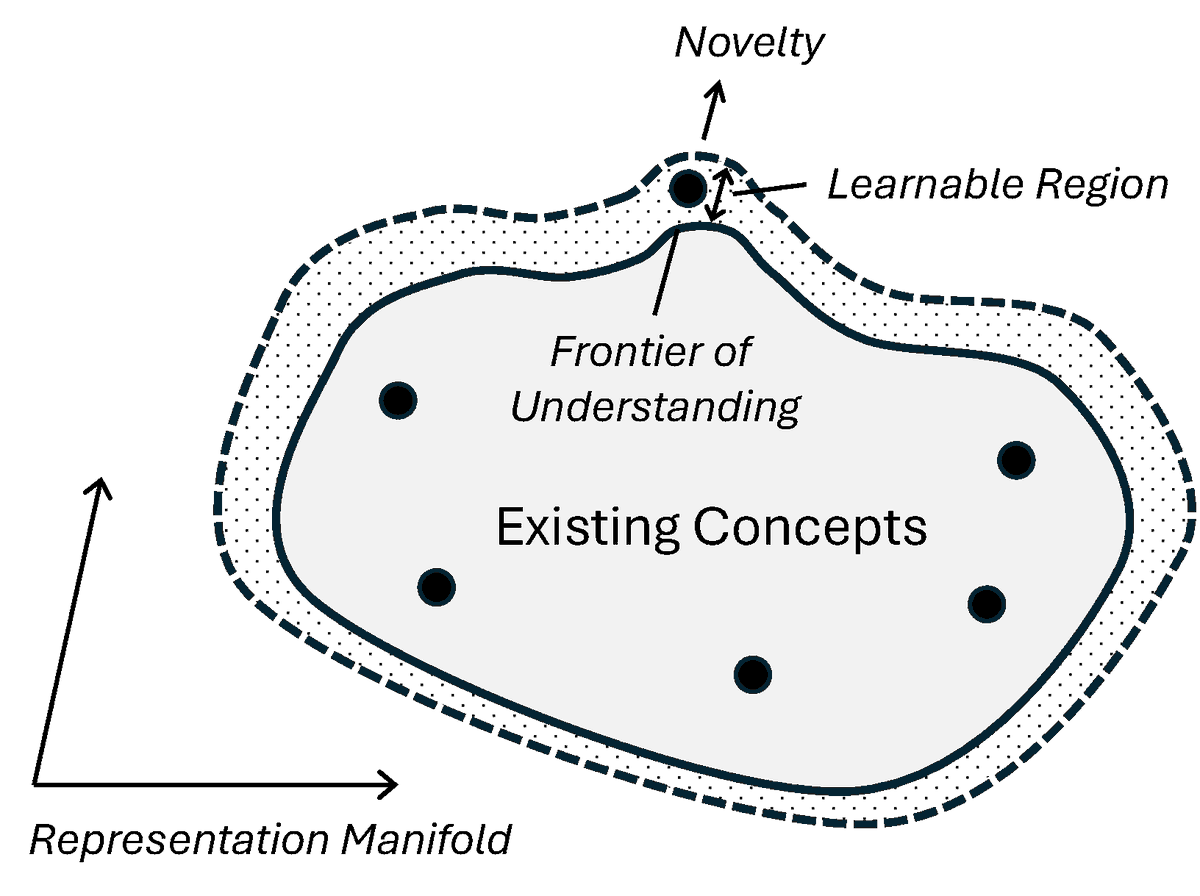
What does it mean to create a new concept rather than retrieve a familiar one?
I propose that creativity is what's unfamiliar at first but quickly learnable by an adaptive observer, and show that meta-learning through a frozen Diffusion model produces stylistic & conceptual creations.
What is the right data mix, and how do we find it as the data keeps changing?
This is a core, unsolved problem in continual learning. To tackle it, we built a data mixing algo that works everywhere — pretraining, midtraining, instruction tuning
Introducing: On-Policy Mix
🧵1/6
AI agents often struggle to plan movements because their internal representations of the physical world can be overly tangled.
CDS PhD student Ying Wang (@yingwww_) shows how straightening these pathways improves AI navigation.
Accepted to ICML 2026.
https://t.co/BOJCXWwWS8
1/
What happens to planning and control when world models condition on complex actions?
For example, precisely controlling a human agent may require specifying the motion of each joint.
In this setting, action dimensionality increases, the model becomes difficult to control, and the cost of planning using search-based methods like CEM explodes.
We propose a solution: lift the world model to a higher level of abstraction.
We use a lightweight policy to map high-level waypoint actions → low-level joint sequences, so you can control and plan in a concise space.
Best of all, this is done without finetuning or losing any world model expressiveness.
1/8
[CV] Lifting Embodied World Models for Planning and Control
A N. Wang, T Darrell, P Izmailov, Y Bai, A Bar [New York University & UC Berkeley] (2026)
https://t.co/c15C0mXMa8
Context Tuning accepted to ICML 2026 🎉
See you in Seoul.
https://t.co/kdwUhxLva3
It’s a neat LLM adaptation method with minimal implementation overhead and great scaling behavior. Hoping to add it in the PEFT library, and will do a follow-up post with lots of new results.
Also excited to share my new LLM reasoning/adaptation work 🔜
Giving a talk at ICLR MemAgents Workshop tomorrow, 11:25am local, Room 205: "Does Your LLM Agent Have a Self?" Spoiler: probably not — but the reason is more nuanced than "they're just LLMs." Hope to see you there!
Happening *TODAY* at #ICLR2026
Drop by if you want to discuss why diversity collapse happens in post training, and/or how to better RL your LLM :)
📍3:15–5:30pm · Pavilion 4 • Poster # 4717
Come see our work on LaMo at #ICLR2026, a world model that predicts compact latent motion tokens to recurrently advance a visual scene's latent state over time, enabling long-horizon prediction!
Presenting at the World Models Workshop on Monday in Room 202 A/B
1/5
Excited to share LaMo: A Latent Motion World Model for Long-Horizon Prediction, to be presented at the ICLR 2026 Workshop on World Models.
LaMo predicts compact latent motion rather than the next dense latent state.

















![fly51fly's tweet photo. [CV] Lifting Embodied World Models for Planning and Control
A N. Wang, T Darrell, P Izmailov, Y Bai, A Bar [New York University & UC Berkeley] (2026)
https://t.co/c15C0mXMa8 https://t.co/xS1Uoru1Fk](https://pbs.twimg.com/media/HHL3rq-a8AAGy1g.jpg)
![fly51fly's tweet photo. [CV] Lifting Embodied World Models for Planning and Control
A N. Wang, T Darrell, P Izmailov, Y Bai, A Bar [New York University & UC Berkeley] (2026)
https://t.co/c15C0mXMa8 https://t.co/xS1Uoru1Fk](https://pbs.twimg.com/media/HHL3rdsaAAA8Y4n.jpg)
![fly51fly's tweet photo. [CV] Lifting Embodied World Models for Planning and Control
A N. Wang, T Darrell, P Izmailov, Y Bai, A Bar [New York University & UC Berkeley] (2026)
https://t.co/c15C0mXMa8 https://t.co/xS1Uoru1Fk](https://pbs.twimg.com/media/HHL3rTEaEAA71Y8.png)



















![fly51fly's tweet photo. [CV] Lifting Embodied World Models for Planning and Control
A N. Wang, T Darrell, P Izmailov, Y Bai, A Bar [New York University & UC Berkeley] (2026)
https://t.co/c15C0mXMa8 https://t.co/xS1Uoru1Fk](https://pbs.twimg.com/media/HHL3r5bbcAAkcQh.jpg)





















