I'm burning tokens by the billions, running several OpenClaw agents across hosts, multiple Claude Code teams, and specialized agents around the clock. 67 agents were building concurrently this morning.
The hardest part isn't the agents anymore. It's keeping them on task and moving forward without me constantly context switching.
PRs sit waiting for review because nobody notices. CI fails at 2am and sits red until morning. Claude Code finishes a feature and the output just... sits there. A Linear ticket gets updated and no agent reacts.
OpenClaw heartbeats help, but things get missed. A task gets spawned and then disappears into the void. I was the human router. Checking, nudging, re-aligning context, remembering what's in flight, and forgetting.
There had to be a way to manage this workforce better. Agents are out of the uncanny valley stage. Their judgment, with proper guardrails, should be enough to keep the trains running on time.
Can we climb the autonomy ladder? If we can declare the information flows and procedures, can agents supervise each other and keep the business humming? Can I switch from standing over agents' shoulders to designing the autonomous organization?
It turns out, yes! I've been doing it with OrgLoop: Organization as Code.
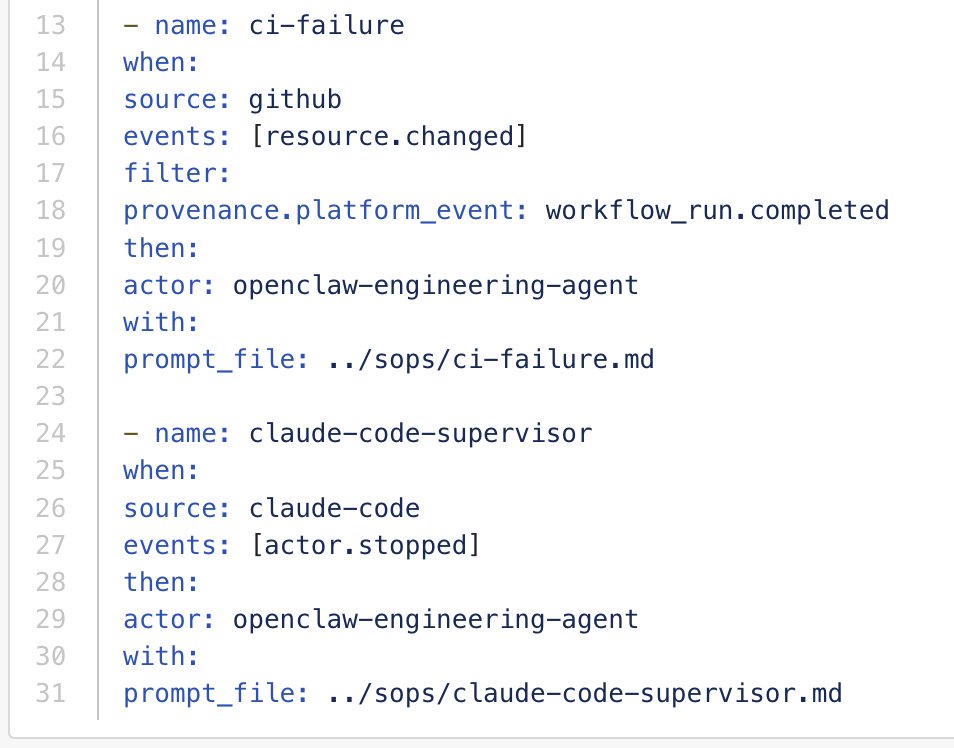
It's Infrastructure as Code, but for autonomy. Your org's event sources, actors, routes, and SOPs declared in YAML. It's open-ended. OpenClaw, Claude Code, GitHub, Linear, Gmail. Simple connectors loop them together.
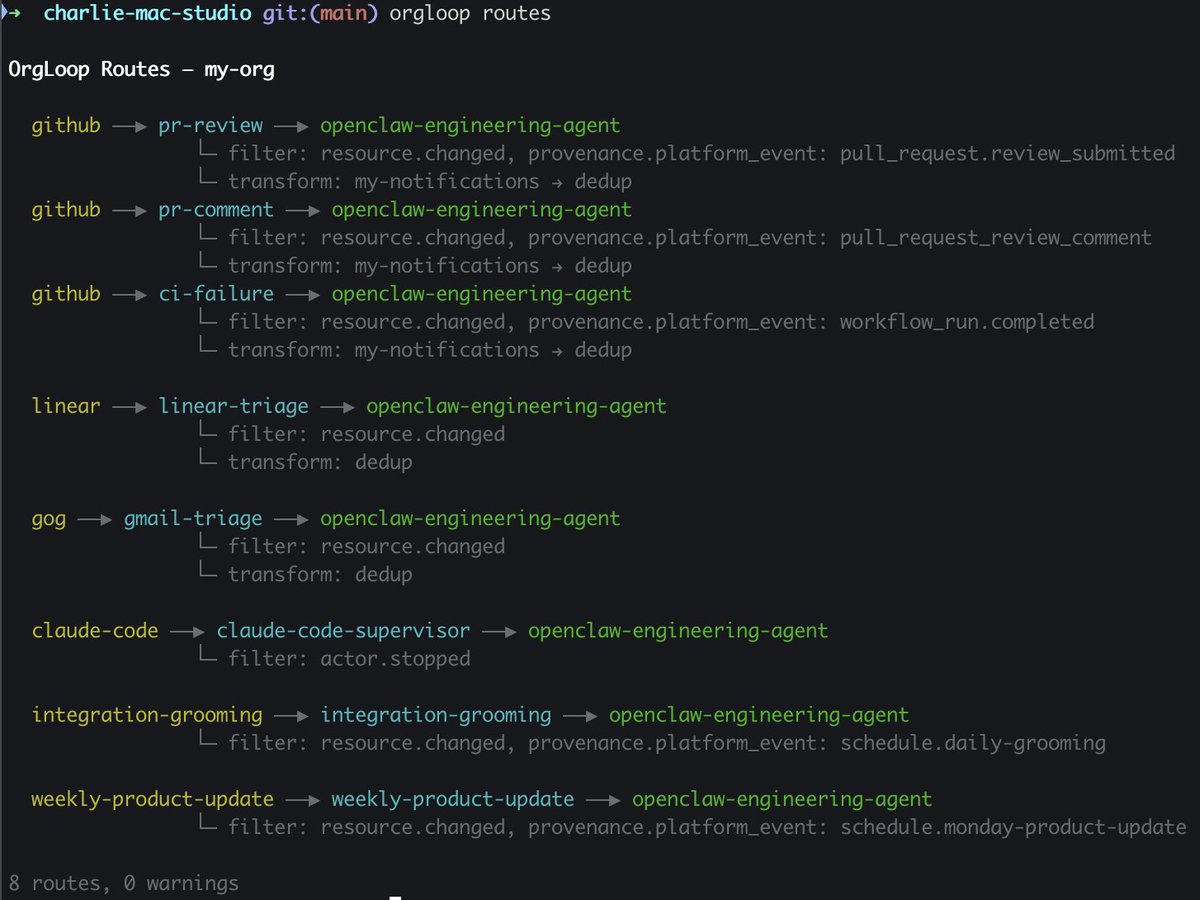
Here's what a real route file looks like, and `orgloop routes` shows the topology at a glance.
Now OpenClaw reliably supervises Claude Code teams, handles GitHub events, triages Linear tickets, processes email. I get escalations, and it still takes work to curate the org design. But when Claude Code finishes, that completion fires an event. The supervisor evaluates and relaunches to continue as needed. The org loops.
It's early alpha days, but it's running in production and a few teams are using it. If you're running agents and feeling the coordination weight, I'd love to compare notes.
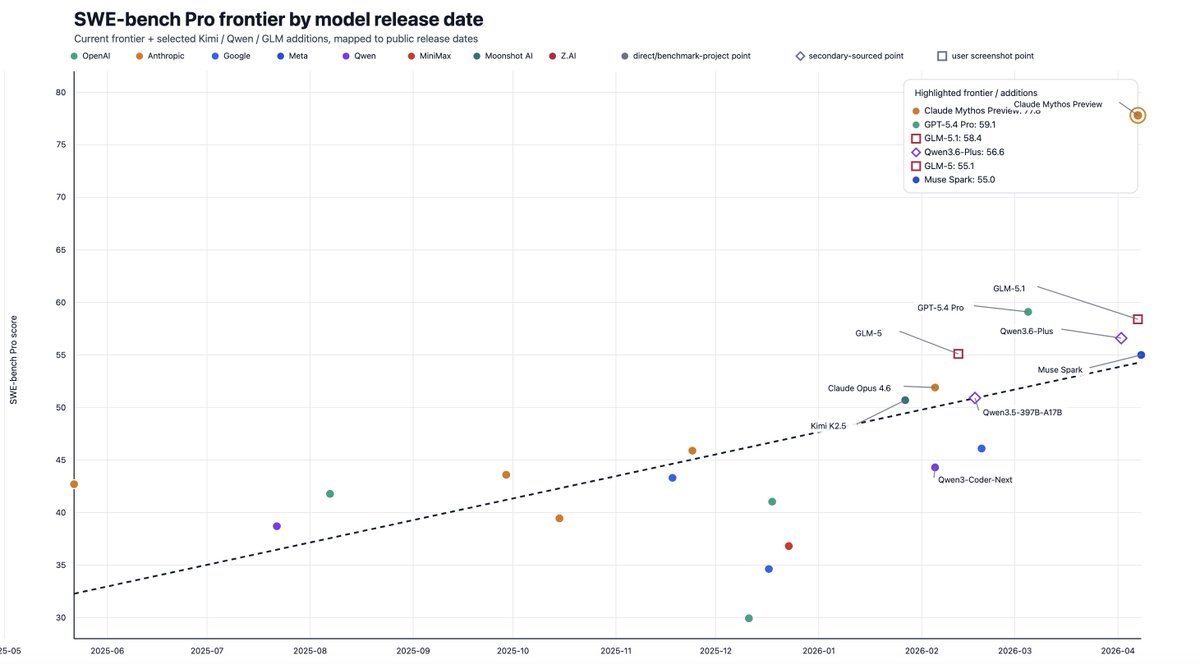
What a stunning step change on SWE Bench Pro claimed by Anthropic with Mythos.
Also notable - look how the latest open weights models like GLM 5.1 and Qwen 3.6 Plus claim to compare against the commercially available frontier models. Agentic coding continues!
@danielrmay Thanks! I'm not sure it's really worth the time to perfect stuff like this when the message and content are accurate.
But makes sense others might dismiss it as being low effort or harder to trust.
We all consume AI models through APIs. They work, but they don't always behave how we want. I always assumed that actually customizing a model required a specialized ML team and serious GPU infrastructure. Is that still true in 2026?
I tested it. When Google released Gemma 4, I set up an experiment: how far can one engineer get with open-source tools, local hardware, and AI agents helping navigate the process?
Setup: NVIDIA DGX Spark, 128GB unified memory, Gemma 4 at 4B parameters. Everything local. Zero cloud. OpenClaw orchestrating the pipeline.
First tool: Heretic, an open-source directional ablation tool. Specific behaviors in a model map to directions in its internal representations. Heretic finds those directions and surgically adjusts them, changing behavior without retraining a single weight. My target was eliminating refusals: the model declining legitimate requests it deemed too sensitive.
What makes Heretic interesting is the dual optimization. Each trial simultaneously minimizes refusal rate AND measures capability loss via KL divergence. It finds the sweet spot where target behavior changes maximally while general abilities stay intact.
Heretic ran 30 automated trials on the Spark, about 12 minutes each, roughly six hours total. Starting point: 41% of test prompts triggered refusals. After ablation: 2%. KL divergence: 0.034, near-zero capability degradation. The model stopped refusing without getting dumber.
The surprising thing is I felt that doing this was easy. I'm not an ML researcher. AI agents did the heavy lifting. They helped write scripts, launch and monitor jobs, interpret results, and figure out what to try next when something broke. The agents didn't replace domain expertise. They made it possible to work through the problem from first principles without needing the expertise up front.
That's the bigger story. The floor for model customization has dropped not just because hardware is cheaper and tools are better, but because an engineer can work with an agent to navigate unfamiliar territory and end up with a good result. Real objectives are within reach now without specialists or heavy infrastructure.
Pipeline continues from here: fine-tuning, alignment, evaluation. More to share as I work through it.
If you've been doing local model work, where have you hit limits?
Anthropic made Dispatch part of Cowork, which puts persistent agents in reach for people who aren't going to self-host infrastructure. OpenClaw got there first, but most people can't or won't run it. That accessibility gap matters when the project is already outpacing Linux itself in GitHub stars.
Nvidia emphasized that growth at GTC, launching NemoClaw, the enterprise variant. Now Hermes, Manus My Computer, Perplexity Computer, and others are building competing agent platforms. The deployment curve is steep.
The harder infrastructure question is how all these agents communicate with each other. We already standardized the layers below: completions endpoints for LLM inference, MCP for tool access. Agent-to-agent communication was the missing protocol layer.
ACP is converging as that standard. Linux Foundation is stewarding it, Google's A2A work merged in, Peter Steinberger's ACPx is landing. The same pattern that strengthened the LLM layer is repeating for agents.
Standards make ecosystems stronger. Let's hope adoption keeps pace with deployment.
@Touch_GrassCap nice! looks like unbundling openrouter? Am I understanding that right? I'll share more about my routing layer soon! tldr for this post is that it routes to local inference compute clusters that have capacity within an SLA, spilling over to cloud when local is saturated.
If your product needs GPUs to work, inference supply is not just a pricing problem. It is a business continuity problem.
Sarah Sachs had a strong post on optionality with frontier labs. I think the next step is treating GPU compute like a supply chain you secure. There is no law that says capacity expands on the schedule your roadmap needs, or that pricing falls on the schedule your margins need.
To start creating optionality with LLM inference, start by standardizing recurring AI work into repeatable tasks rather than ad hoc. Then evaluate those tasks across models to find the best effectiveness per dollar. Then own as much of the inference path as you can.
I use OrgLoop to define the work and agentctl to compare models. For routing, I ended up building my own layer because local-first inference that spills to cloud when needed is just not a design goal of LiteLLM, AnyLLM, Helicone, or OpenRouter. I may open-source my "inference marketplace", because I think that gap will matter to a lot more teams if local inference improves and online GPU capacity becomes scarce.
Once you route by task rather than defaulting to frontier for everything, a surprising share of your traffic turns out to be moderate work that open weight handles well, better than you probably expect. Just like driving an F1 car to the post office would be overkill, using the most expensive frontier model at max reasoning for all your work is the same. Open weight models are not like Haiku, cheap but too limited to do anything you really want to do. They are genuinely capable, happen to be lower cost, and self-hostable.
Cloud and proprietary frontier still matter for the hardest paths, but they should behave like burst capacity, not your only oxygen source.
It may be worth hedging against the black swan of GPU compute supply getting interrupted. That could mean on-demand availability disappears, or that pricing rises with demand rather than falls, climbing above what your margins can support. If your business depends on inference and you have no hedge, what would you do?
Sharing this publicly––hope it's not needed but helps you if it is.
Lux team sent this memo to all Lux family founders yesterday
"We send notes like this not because something is wrong, but because the COST of preparation is trivially LOW and the VALUE of being positioned well is asymmetrically HIGH. This isn’t a macro call. It’s a set of observations about correlated risks that are worth your attention. And a set of practical suggestions regardless of whatever happens next."
The Amazon outage reports do not read like "AI caused an outage" to me. They read like a destructive path had more autonomy than the recovery path behind it. If rollback and restore are not automated, the system breaks faster than it heals. Autonomous creation without autonomous recovery just shifts the bottleneck to where failure costs the most. Validation, rollback, and recovery can be autonomous too.
I wrote up the full technical breakdown here: https://t.co/tJnWHRNOFq
Both repos are open source:
retrieval-skill: https://t.co/datMbbfoiB
octen-embeddings-server: https://t.co/NDoByhTX7o
A trillion dollars got wiped from software stocks last month on the thesis that AI will replace traditional SaaS. Investors are hammering ServiceNow, Salesforce, and the rest. But the companies that embraced AI early, Glean, Coveo, Notion AI, Microsoft Copilot, are trading at a premium because the market treats them as safe.
I think the market is wrong about that second group.
I built a self-hosted replacement for the core of what Glean does (the retrieval stack I just open-sourced). Two repos, a Mac Studio, and a weekend. Syncs from Slack, Notion, Linear, Gmail. Runs entirely on consumer hardware. Zero per-seat pricing, zero data leaving my network.
Then I built capabilities on top that none of these vendors even offer. An agent that researches your entire org's history across every source and produces comprehensive cited reports in 7 minutes. You can't buy that from Glean at any price.
Vibe coding doesn't only disrupt traditional tech. It disrupts AI tech too. The category Wall Street thinks is safe is sitting on the same thinning ice as every other SaaS vertical, and nobody's pricing that in yet.
I wrote up the full technical breakdown of the retrieval system here: https://t.co/tJnWHRNOFq
retrieval-skill: https://t.co/datMbbfoiB
octen-embeddings-server: https://t.co/NDoByhTX7o
I built a data exfiltration system (the retrieval skill I just open-sourced). It connects to an organization's Slack, Notion, Linear, and Gmail, continuously extracts everything those tokens can access, and synthesizes it into cited intelligence briefings. Seven minutes from question to report. It runs on a Mac Studio in my house.
I call it a "retrieval skill," but a CISO would call it something else.
Any engineer with a weekend could build this, and every team running AI agents will arrive at the same architecture because the pattern is obvious once you need organizational context. These systems won't go through security review. They'll be side projects that work too well to shut down.
The answer isn't banning it, because the productivity gains are too real. The answer is building it inside your data boundary: self-hosted embeddings, local inference, data that never leaves the environment. Enable vibe coding, but in a way that works for you, not against you.
That's the thesis behind Kindo, where I work. These capabilities are coming whether security approves or not, and the only question is whether they run inside the boundary or outside it.
Both repos are MIT-licensed:
retrieval-skill (sync, index, search, deep retrieval): https://t.co/datMbbfoiB
octen-embeddings-server (local embeddings on Apple Silicon): https://t.co/NDoByhTX7o
I built a retrieval system that produces comprehensive reports across an entire organization's history in about 7 minutes.
The problem it solves: a 3-year-old company has thousands of Slack conversations, hundreds of Notion specs, years of Linear issues, and piles of email. No single person has read all of it. No single person could synthesize it. Every planning cycle starts with "what do we know?" and the answer is always "whatever someone remembers."
There are two layers to this.
The first is the retrieval primitive. An OpenClaw skill backed by two self-hosted repos. retrieval-skill handles SaaS connectors (Slack, Notion, Linear, Gmail), incremental sync, and indexing into SQLite with hybrid search. octen-embeddings-server runs Octen-Embedding-8B locally on Apple Silicon via MLX. Tens of millions of vectors. Visual understanding via ColQwen2.5 for PDFs and images. Zero external dependencies, no data leaves the machine.
Day-to-day, agents use it for quick lookups:
retrieve search "frontend traces not connecting to backend distributed traces through Grafana Faro RUM" --index slack,notion,linear
That's not a keyword search. It's semantic. The richer and more contextual your query, the tighter the results. Vector similarity + keyword matching + recency boost, all running locally against SQLite indexes.
The second layer is deep retrieval. This is where it gets interesting. An AI agent gets spawned with a research question. It doesn't run one search. It runs dozens of queries across every index, follows threads it discovers, cross-references what it finds in Slack against the Notion spec against the Linear ticket against the code. Then it synthesizes a grounded report with citations and saves it to Obsidian.
You ask "what's the state of observability and monitoring?" and 7 minutes later you get a narrative: what was built, what was discussed but never built, where the gaps are, how thinking evolved over time, who worked on what, and why.
An engineer on the team read the output: "This is an incredible report that would be impossible for a human to reproduce manually." He found gaps and some inaccuracies, but said it captured the vast majority of relevant context across the entire org.
Are the reports perfect? No. You might get a missing subsystem or a misattributed author. But that's the wrong bar.
The right bar: can this unlock autonomous planning at high enough quality that work product moves forward? Yes. These reports are the richest possible starting point for understanding where a technical system is today. Combine that with current product requirements and the codebase, and you have what you need to spec what to build next, grounded in institutional context and the real history of why things are the way they are. That process is tolerant of minor gaps. What it's not tolerant of is starting from scratch every cycle.
This is technology for real enterprise planning, not greenfield vibe coding.
Both repos are MIT-licensed.
I built a CLI for orchestrating headless coding agents.
I run coding agents as my primary way of writing software. Not interactively, headlessly. And the friction compounds fast. Sessions get forgotten. Two agents launch in the same repo and clobber each other. You want to compare models but the switching cost keeps you on whatever's working okay.
Then there's the layer that made it unavoidable: I have AI agents supervising my coding agents. They need a clean interface to launch sessions, check progress, and react when things finish.
So I built agentctl. One command, three models, three worktrees, pick the winner:
agentctl launch \
--adapter claude-code --model opus \
--adapter claude-code --model sonnet \
--adapter codex \
-p "refactor the auth module"
Each gets its own branch. No conflicts. Switching cost drops to zero.
Some of the details that make it daily-drivable: directory locking prevents two agents from stomping the same repo, and humans can claim a directory too when they need to debug manually. Lifecycle hooks bootstrap each worktree before the agent starts (mise trust, dependency install) and run your tests the moment it finishes. It reads from native agent sources instead of maintaining its own registry, so it always reflects what's actually running. Small things, but they're the difference between a demo and a workflow.
It's alpha, but a few folks have been daily driving it for a while now. Supports Claude Code, Codex, OpenCode, and Pi.
I think headless agents will be how most code gets written sooner than people expect. If you've been running coding agents headlessly and hitting the same friction, this was built for exactly that.
Open source, MIT licensed.