Yo no quiero que en las empresas se me hable de valores y polladas varias.
Quiero buen sueldo y buenas condiciones.
Los afterwork, excursiónes, cursos de colorear emociones etc os lo podeis meter por el ojaldre si luego me pagas 4 duros y me amargas la vida
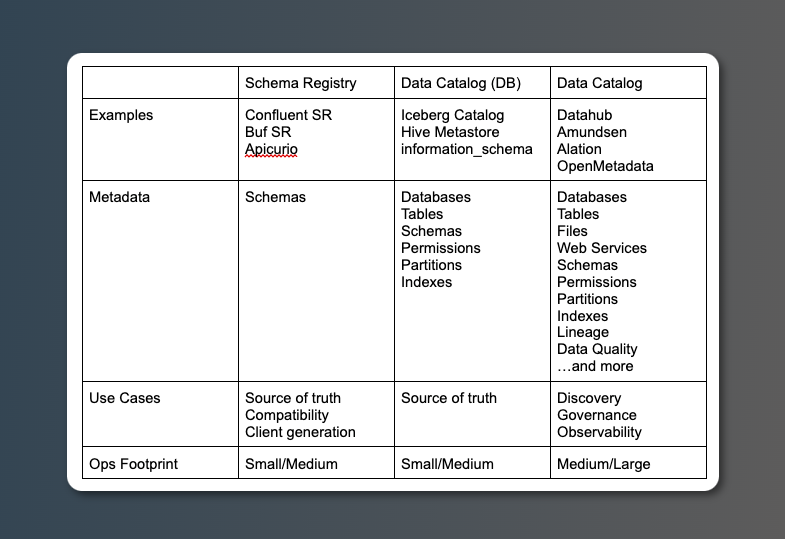
For your consideration. There are two different kinds of catalogs:
- Single system data catalogs (like Iceberg Catalog, HMS)
- Multi-system data catalogs (like Amundsen, Datahub, etc)
Schema registries fall somewhere in here, too.
Not a full-fledged thought. Feedback welcome.
Introducing Sora, our text-to-video model.
Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions.
https://t.co/YYpOAcrXQ3
Prompt: “Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city street, following several people enjoying the beautiful snowy weather and shopping at nearby stalls. Gorgeous sakura petals are flying through the wind along with snowflakes.”
Precioso vídeo acelerado de la rotación de la tierra. Así hacemos las fotos astronómicas siempre: montando el telescopio en un soporte que gira al revés que el planeta para contrarrestar su rotación. Aquí han usado una cámara normal en vez de telescopio y ajustado la exposición.
Oauth 2.0 Explained With Simple Terms.
OAuth 2.0 is a powerful and secure framework that allows different applications to securely interact with each other on behalf of users without sharing sensitive credentials.
The entities involved in OAuth are the User, the Server, and the Identity Provider (IDP).
What Can an OAuth Token Do?
When you use OAuth, you get an OAuth token that represents your identity and permissions. This token can do a few important things:
Single Sign-On (SSO): With an OAuth token, you can log into multiple services or apps using just one login, making life easier and safer.
Authorization Across Systems: The OAuth token allows you to share your authorization or access rights across various systems, so you don't have to log in separately everywhere.
Accessing User Profile: Apps with an OAuth token can access certain parts of your user profile that you allow, but they won't see everything.
Remember, OAuth 2.0 is all about keeping you and your data safe while making your online experiences seamless and hassle-free across different applications and services.
Over to you: Imagine you have a magical power to grant one wish to OAuth 2.0. What would that be? Maybe your suggestions actually lead to OAuth 3.
–
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): https://t.co/uc5M7CdXXC
CQRS = Separate read/write databases? Not so fast!
This isn't really what CQRS is about.
First, there was the CQS - Command-Query Separation principle.
Here's what CQS is:
- Commands change state, don't return data
- Queries don't change state, return data
- Queries should not have side effects
What? I can't return data from a command?!
Of course, you can - but the intent is different.
I'm not saying you shouldn't be pragmatic.
For example, you insert a new row into the database and return the ID of the word. Perfectly fine.
But what about CQRS?
CQRS stands for Command-Query Responsibility Segregation.
It's an evolution of CQS and works on the architecture level.
Whereas CQS works on the method (or class) level.
It separates the subsystem responsible for handling commands from the one responsible for handling queries.
In other words, you have a logical separation of reads and writes.
Here are a few benefits you get with CQRS:
- Complexity management
- Scalability
- Flexibility
- Security
How did we begin associating CQRS with separate read/write databases?
This happens when you take the logical separation of commands and queries and elevate it to physical separation.
There are many flavors of this approach:
- SQL + NoSQL
- Event sourcing + NoSQL
- SQL + Redis
And while it has its benefits, like improving your job security, too much complexity can hurt your project.
So start simple. You can do CQRS with one database.
Apply logical separation of commands and queries.
Only add further complexity (like eventual consistency) if you need to.
Tomorrow, I'll show 29,675+ engineers how to implement CQRS with MediatR.
📌 Join free here: https://t.co/xip45XpWuB
REPOST = Teach your audience about CQRS ♻️
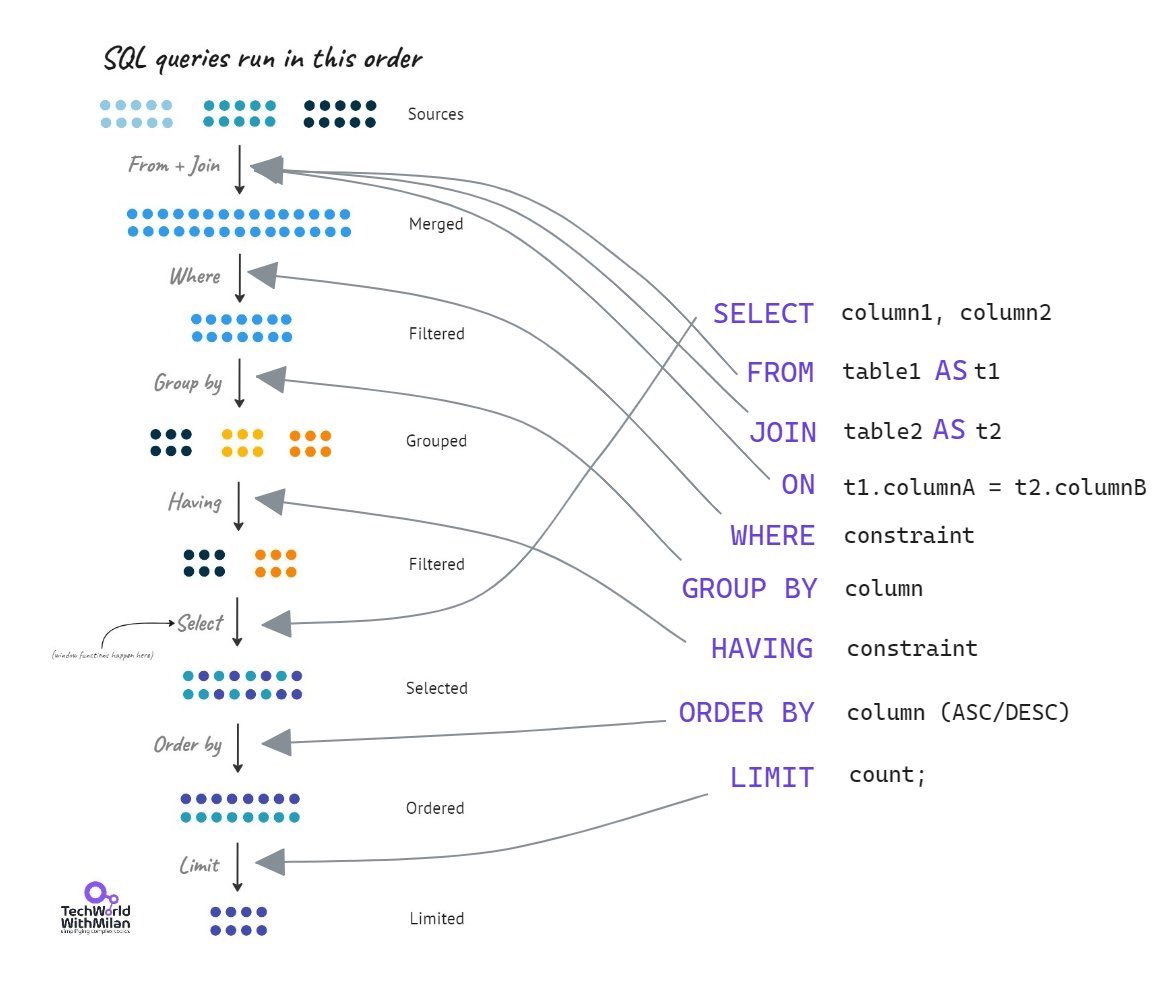
𝗧𝗼𝗽 𝟮𝟬 𝗦𝗤𝗟 𝗾𝘂𝗲𝗿𝘆 𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗮𝘁𝗶𝗼𝗻 𝘁𝗲𝗰𝗵𝗻𝗶𝗾𝘂𝗲𝘀
Here is the list of the top 20 SQL query optimization techniques I found noteworthy:
1. Create an index on huge tables (>1.000.000) rows
2. Use EXIST() instead of COUNT() to find an element in the table
3. SELECT fields instead of using SELECT *
4. Avoid Subqueries in WHERE Clause
5. Avoid SELECT DISTINCT where possible
6. Use WHERE Clause instead of HAVING
7. Create joins with INNER JOIN (not WHERE)
8. Use LIMIT to sample query results
9. Use UNION ALL instead of UNION wherever possible
10. Use UNION where instead of WHERE ... or ... query.
11. Run your query during off-peak hours
12. Avoid using OR in join queries
14. Choose GROUP BY over window functions
15. Use derived and temporary tables
16. Drop the index before loading bulk data
16. Use materialized views instead of views
17. Avoid != or <> (not equal) operator
18. Minimize the number of subqueries
19. Use INNER join as little as possible when you can get the same output using LEFT/RIGHT join.
20. For retrieving the same dataset, frequently try to use temporary sources.
Do you know what is 𝗤𝘂𝗲𝗿𝘆 𝗢𝗽𝘁𝗶𝗺𝗶𝘇𝗲𝗿? Its primary function is to determine 𝘁𝗵𝗲 𝗺𝗼𝘀𝘁 𝗲𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝘁 𝘄𝗮𝘆 to execute a given SQL query by finding the best execution plan. The query optimizer works by taking the SQL query as input and analyzing it to determine how best to execute it. The first step is to parse the SQL query and create a syntax tree. The optimizer then analyzes the syntax tree to determine how to run the query.
Next, the optimizer generates 𝗮𝗹𝘁𝗲𝗿𝗻𝗮𝘁𝗶𝘃𝗲 𝗲𝘅𝗲𝗰𝘂𝘁𝗶𝗼𝗻 𝗽𝗹𝗮𝗻𝘀, which are different ways of executing the same query. Each execution plan specifies the order in which the tables should be accessed, the join methods, and any filtering or sorting operations. The optimizer then assigns a 𝗰𝗼𝘀𝘁 to each execution plan based on the number of disk reads and the CPU time required to execute the query.
Finally, the optimizer 𝗰𝗵𝗼𝗼𝘀𝗲𝘀 𝘁𝗵𝗲 𝗲𝘅𝗲𝗰𝘂𝘁𝗶𝗼𝗻 𝗽𝗹𝗮𝗻 with the lowest cost as the optimal execution plan for the query. This plan is then used to execute the query.
Check in the image the 𝗼𝗿𝗱𝗲𝗿 𝗶𝗻 𝘄𝗵𝗶𝗰𝗵 𝗦𝗤𝗟 𝗾𝘂𝗲𝗿𝗶𝗲𝘀 𝗿𝘂𝗻.
#technology #softwareengineering #programming #techworldwithmilan #sql
Z Order in #DeltaLake organizes data in storage to improve query performance.
In this example, the query has to scan through 8 separate files to find rows where id = 5. However, with Z Order optimization, the query only needs to scan one file to locate the desired rows.
IBM MQ -> RabbitMQ -> Kafka ->Pulsar, How do message queue architectures evolve?
🔹 IBM MQ
IBM MQ was launched in 1993. It was originally called MQSeries and was renamed WebSphere MQ in 2002. It was renamed to IBM MQ in 2014. IBM MQ is a very successful product widely used in the financial sector. Its revenue still reached 1 billion dollars in 2020.
🔹 RabbitMQ
RabbitMQ architecture differs from IBM MQ and is more similar to Kafka concepts. The producer publishes a message to an exchange with a specified exchange type. It can be direct, topic, or fanout. The exchange then routes the message into the queues based on different message attributes and the exchange type. The consumers pick up the message accordingly.
🔹 Kafka
In early 2011, LinkedIn open sourced Kafka, which is a distributed event streaming platform. It was named after Franz Kafka. As the name suggested, Kafka is optimized for writing. It offers a high-throughput, low-latency platform for handling real-time data feeds. It provides a unified event log to enable event streaming and is widely used in internet companies.
Kafka defines producer, broker, topic, partition, and consumer. Its simplicity and fault tolerance allow it to replace previous products like AMQP-based message queues.
🔹 Pulsar
Pulsar, developed originally by Yahoo, is an all-in-one messaging and streaming platform. Compared with Kafka, Pulsar incorporates many useful features from other products and supports a wide range of capabilities. Also, Pulsar architecture is more cloud-native, providing better support for cluster scaling and partition migration, etc.
There are two layers in Pulsar architecture: the serving layer and the persistent layer. Pulsar natively supports tiered storage, where we can leverage cheaper object storage like AWS S3 to persist messages for a longer term.
Over to you: which message queues have you used?
–
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): https://t.co/uc5M7CdXXC
𝗪𝗵𝗮𝘁 𝗶𝘀 𝗗𝗮𝘁𝗮 𝗣𝗹𝗮𝘁𝗳𝗼𝗿𝗺?
Data Platform is an analysis platform, where by using it, you will be able to ingest your data, transform it and finally extract value out of it. Everything starts from different data sources, which you can connect with the connectors' data loaders. You can use it to ingest your data into a data lake. When data arrives, it goes to different layers, where it is transformed, and then it can be visualized for machine learning development.
Who can use a data platform?
𝟭. 𝗡𝗼𝗻-𝘁𝗲𝗰𝗵𝗻𝗶𝗰𝗮𝗹 𝘂𝘀𝗲𝗿
Usually, non-technical users can use such platforms to extract value from data and visualize it.
𝟮. 𝗧𝗵𝗲 𝗗𝗮𝘁𝗮 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿
They will use everything that the non-technical user does but get deeper into the features of a visualization tool.
𝟯. 𝗧𝗵𝗲 𝗗𝗮𝘁𝗮 𝗦𝗰𝗶𝗲𝗻𝘁𝗶𝘀𝘁
They will get even deeper into every feature, using the data already made available by the Data Engineer in their Python algorithms through notebooks.
An example of one Data platform is shown in the image (Semantix Data Platform). Other examples are Google BigQuery, Azure HDInsight, Apache Hadoop, etc.
Image credits: Semantix Data Platform.
____
If you like my posts, please follow @milan_milanovic, and hit the 🔔 on my profile to get a notification for all my new posts.
Learn something new every day 🚀!
#data #datascience #dataengineering #softwareengineering #machinelearning
What is the role of 𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁𝘀 in the Data Pipeline?
In its simplest form Data Contract is an agreement between Data Producers and Data Consumers on what the Data being produced should look like, what SLAs it should meet and the semantics of it.
𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁 𝘀𝗵𝗼𝘂𝗹𝗱 𝗵𝗼𝗹𝗱 𝘁𝗵𝗲 𝗳𝗼𝗹𝗹𝗼𝘄𝗶𝗻𝗴 𝗻𝗼𝗻-𝗲𝘅𝗵𝗮𝘂𝘀𝘁𝗶𝘃𝗲 𝗹𝗶𝘀𝘁 𝗼𝗳 𝗺𝗲𝘁𝗮𝗱𝗮𝘁𝗮:
👉 Schema of the Data being Produced.
👉 Shema Version - Data Sources evolve, Producers have to ensure that it is possible to detect and react to schema changes. Consumers should be able to process Data with the old Schema.
👉 SLA metadata - Quality: is it meant for Production use? How late can the data arrive? How many missing values could be expected for certain fields in a given time period?
👉 Semantics - what entity does a given Data Point represent. Semantics, similar to schema, can evolve over time.
👉 Lineage - Data Owners, Intended Consumers.
👉 …
𝗦𝗼𝗺𝗲 𝗣𝘂𝗿𝗽𝗼𝘀𝗲𝘀 𝗼𝗳 𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁𝘀:
➡️ Ensure Quality of Data in the Downstream Systems.
➡️ Prevent Data Processing Pipelines from unexpected outages.
➡️ Enforce Ownership of produced data closer to where it was generated.
➡️ Improve scalability of your Data Systems.
➡️ Reduce intermediate Data Handover Layer.
➡️ …
Example implementation for Data Contract Enforcement:
1️⃣ Schema changes are implemented in a git repository, once approved - they are pushed to the Applications generating the Data and a central Schema Registry.
2️⃣ Applications push generated Data to Kafka Topics. Separate Raw Data Topics for CDC streams and Direct emission.
3️⃣ A Flink Application(s) consumes Data from Raw Data streams and validates it against schemas in the Schema Registry.
4️⃣ Data that does not meet the contract is pushed to Dead Letter Topic.
5️⃣ Data that meets the contract is pushed to Validated Data Topic.
6️⃣ Applications that need Real Time Data consume it directly from Validated Data Topic or its derivatives.
7️⃣ Data from the Validated Data Topic is pushed to object storage for additional Validation.
8️⃣ On a schedule Data in the Object Storage is validated against additional SLAs and is pushed to the Data Warehouse to be Transformed and Modeled for Analytical purposes.
9️⃣ Consumers and Producers are alerted to any SLA breaches.
🔟 Data that was Invalidated in Real Time is consumed by Flink Applications that alert on invalid schemas. There could be a recovery Flink App with logic on how to fix invalidated Data.
Leave your thoughts in the comment section 👇
--------
Follow me to upskill in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
Also hit 🔔to stay notified about new content.
𝗗𝗼𝗻’𝘁 𝗳𝗼𝗿𝗴𝗲𝘁 𝘁𝗼 𝗹𝗶𝗸𝗲 💙, 𝘀𝗵𝗮𝗿𝗲 𝗮𝗻𝗱 𝗰𝗼𝗺𝗺𝗲𝗻𝘁!
Join a growing community of Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: https://t.co/qgNCnGtF4A
Configuring an Apache Spark session to work with different Iceberg catalogs can sometimes include a lot of options. This article from @AMdatalakehouse breaks down the relevant Spark configurations to configure all types of catalogs with for Iceberg: https://t.co/TeIwiiZCqB