You've read the blog post (or have you??), now watch the video. My take on the Developer's Journey: discover, understand, play, build, advocate. You can't reason about DevRel without this. Full video over on the site:
https://t.co/MMOKTBiE4o
Badger Badger Badger, also known as “The Badger Song,” is a viral internet meme and classic Flash animation from 2003 by Jonti Picking.
The looping animation featured dancing badgers, mushrooms, and a snake, paired with a catchy repetitive song that became one of the most iconic viral videos of the early internet era.
#InternetHistory
Wading through the words, striding through the slop…it must be nearly time for this month's Interesting Links in the Data & AI World!
Subscribe here: https://t.co/IOZuNRUzqM
or RSS feed: https://t.co/v5i79GIVuB
(and if you've got an interesting link to share, send it my way!)
New post: Kafka Share Groups and Parallelizing Consumption - Part 1.
We introduce consumer processing time to the benchmarks to reveal the underlying mechanisms that determine the effective parallelism of share group consumers.
With 300 consumers and 5ms processing time, the theoretical max was 60K msg/s.
With the defaults, I got 4.8K msg/s.
Read to understand about the importance of max.poll.records and how a bad value can still look ok, until suddenly it doesn't.
https://t.co/8TuTEnLrcH
I just published the first set of Dimster benchmarks comparing Apache Kafka consumer groups and share groups.
This isn’t really the interesting part yet.
The goal here was just to establish a baseline:
* raw overhead
* raw scaling
* latency behavior under non-stressful loads
Basically: what does share group coordination cost?
In the next post after this we'll get to the interesting stuff, testing the workloads that share groups were designed for.
https://t.co/pxF4CsPFQN
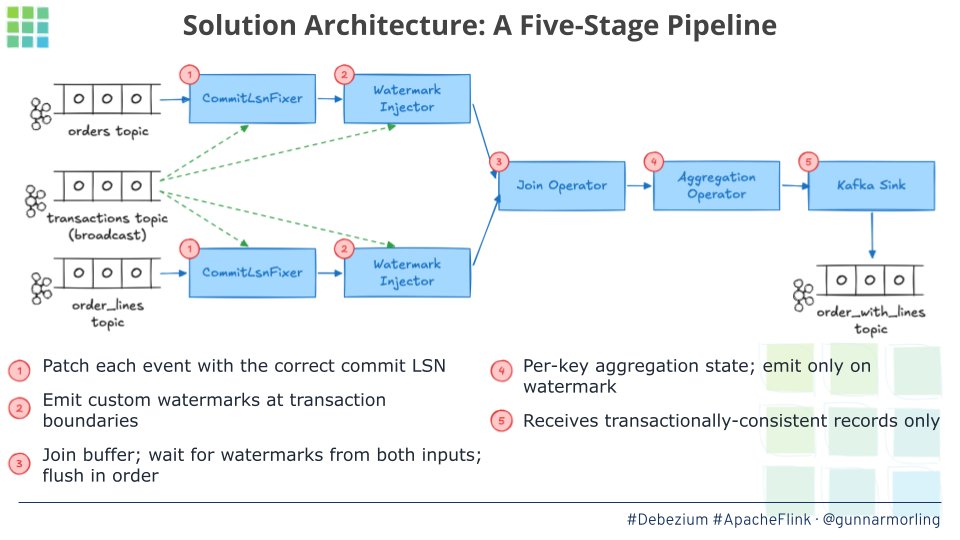
The slides from #Current London talks are up 🥳.
- "Transactional Change Stream Processing With Debezium and Apache Flink" https://t.co/dainRntB2C
- "Hardwood: Building a Parquet Parser From Scratch (With a Little Help From AI)" https://t.co/RNdVEfu4vS
I've been performance testing Apache Kafka extensively over the last couple of months, using a new performance tool I've developed inside Confluent (with some help from Claude).
The goals were fairly simple:
1. Make it easy to run sophisticated, reproducible benchmarks (no stitching together a pile of scripts and dashboards).
2. Make it really easy to share results with colleagues which contain all the information to reproduce the test.
3. Make chart generation and log gathering automatic (rolling them into the result package).
4. Support powerful workload modelling, latency/throughput analysis, and benchmark orchestration with ease-of-use as a primary concern.
Dimster is my attempt to make Kafka benchmarking more structured and reproducible. I'll be publishing my performance analysis of share groups, using Dimster, very soon.
https://t.co/L2c2ZA64Rz