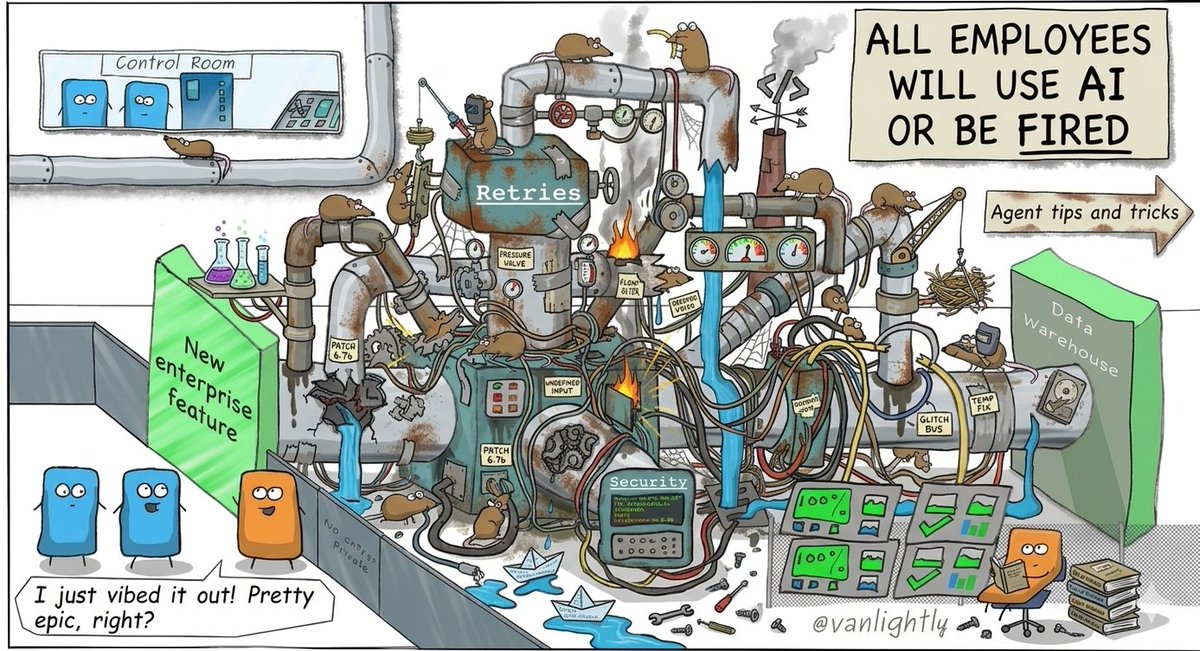
New blog post. Broker-Visible vs Client-Local Parallelism
In my benchmarking of share groups I've been focusing on parallel processing because it turns out that a few settings materially impact how effectively messages are distributed across consumers.
But share groups weren't created solely for the purpose of escaping the confines of the partition as the unit of parallelism. Share groups exist to add queue semantics, which naturally leads to the consumer as the unit of parallelism instead of the partition. But if you are considering share groups solely for escaping the confines of the partition, then this post might be worth a read.
https://t.co/0fp58ol1Oa
@Pipeline_papi That's how it starts. Shock, OMG this is good. Then you settle into the day to day and that find you, a human, is still very much needed
New post: Kafka Share Groups and Parallelizing Consumption - Part 2.
Kafka Share Groups make parallel consumption possible within a partition, but tuning them isn’t just about consumer count or max.poll.records (part 1).
In Part 2, I look at how producer batch size, consumer share.acquire.mode and max.poll.records interact to impact the effective parallelism of a workload. We'll take the final workload from part 1 but double the batch size, dropping the target consume rate from 60K msg/s to 37K, then look at options to fix the consumer parallelism.
https://t.co/9NUmorqT1D
New post: Kafka Share Groups and Parallelizing Consumption - Part 1.
We introduce consumer processing time to the benchmarks to reveal the underlying mechanisms that determine the effective parallelism of share group consumers.
With 300 consumers and 5ms processing time, the theoretical max was 60K msg/s.
With the defaults, I got 4.8K msg/s.
Read to understand about the importance of max.poll.records and how a bad value can still look ok, until suddenly it doesn't.
https://t.co/8TuTEnLrcH
I just published the first set of Dimster benchmarks comparing Apache Kafka consumer groups and share groups.
This isn’t really the interesting part yet.
The goal here was just to establish a baseline:
* raw overhead
* raw scaling
* latency behavior under non-stressful loads
Basically: what does share group coordination cost?
In the next post after this we'll get to the interesting stuff, testing the workloads that share groups were designed for.
https://t.co/pxF4CsPFQN
I've been performance testing Apache Kafka extensively over the last couple of months, using a new performance tool I've developed inside Confluent (with some help from Claude).
The goals were fairly simple:
1. Make it easy to run sophisticated, reproducible benchmarks (no stitching together a pile of scripts and dashboards).
2. Make it really easy to share results with colleagues which contain all the information to reproduce the test.
3. Make chart generation and log gathering automatic (rolling them into the result package).
4. Support powerful workload modelling, latency/throughput analysis, and benchmark orchestration with ease-of-use as a primary concern.
Dimster is my attempt to make Kafka benchmarking more structured and reproducible. I'll be publishing my performance analysis of share groups, using Dimster, very soon.
https://t.co/L2c2ZA64Rz
I asked Claude if HdrHistogram was still being maintained and Claude told me no, Gil Tene had passed away. Shocked I googled him and saw he was alive and giving talks. I told Claude and it updated my CLAUDE.md with an entry reminding it to check if people are still alive before saying they are dead 😂
Seeing the recent NVMe/S3 debate, the use of the word "fast", plus I've been doing benchmarking for the last month, I thought I'd republish my "benchmarketing" guide from 2022:
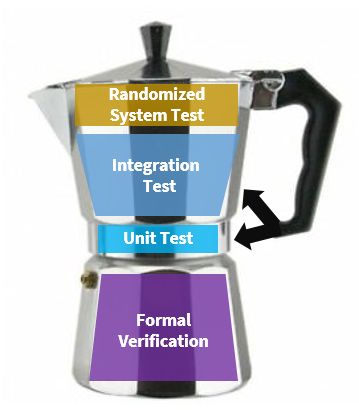
Seen some discussion of unit tests vs end-to-end/integrations tests in the age of AI. A few years ago I proposed the "testing cafetiere" to replace the "test pyramid". These days I think the randomized system testing could be replaced by, or least augmented with deterministic simulation testing.
In my #heisenbug talk on #distributedsystems testing I introduced the "Testing Cafetiere" as a distributed systems specific test strategy.
- Use randomness to find your edge cases --> add your edge cases to your regression tests
- Test your implementation
- Verify your design