We are thrilled to announce that @generaltensor has acquired @BackpropFinance and the Tensorplex Validator!
Backprop Finance is one of Bittensor’s highest-volume trading platforms, facilitating billions in transaction volume since its inception a year ago.
With a vertically integrated portfolio spanning from data centers to Bittensor subnets and validators, General Tensor is uniquely positioned to scale Backprop Finance and the Tensorplex Validator into the definitive global infrastructure for decentralised AI.
We look forward to seeing these products thrive under General Tensor’s leadership.
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
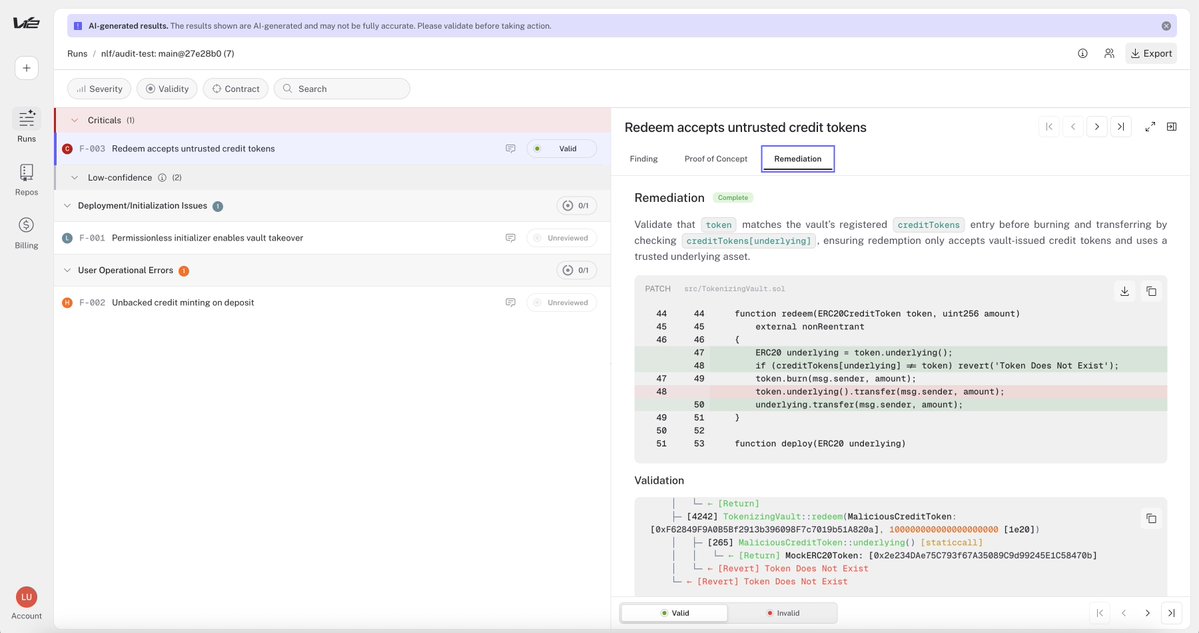
V12 is now live for open beta. It can:
- Find valuable bugs
- Generate working, runnable PoC
- Generate patch and test the PoC against it
In our testing during audits at Zellic, Zenith, and Code4rena we've been consistently impressed.
Best of all: it's free. (Don't abuse it!)
Bullish on TAO?
https://t.co/uGWsC1UHCn lets you trade individual subnets (decentralized training, compute, agents, etc.) instead of just holding the base token
Higher yields, and profits if you can pick the right subnets 📈
oh i meant Gemini 3 pulled ahead due to some pre-training breakthrough. either OpenAI could catch up by throwing Blackwell at pre-training, or the issue is more on talent drain (i.e. GOOG discovered some pre-training technique enabling them to pull ahead, instead of just benefitting from TPUs)
@Fiskantes ah fair, i still have strong chatgpt preference (pro version just goes harder with analysis while gemini has worse app and is more mid) so the ‘comparable product’ part went over my head
My pleasure to come on Dwarkesh last week, I thought the questions and conversation were really good.
I re-watched the pod just now too. First of all, yes I know, and I'm sorry that I speak so fast :). It's to my detriment because sometimes my speaking thread out-executes my thinking thread, so I think I botched a few explanations due to that, and sometimes I was also nervous that I'm going too much on a tangent or too deep into something relatively spurious. Anyway, a few notes/pointers:
AGI timelines. My comments on AGI timelines looks to be the most trending part of the early response. This is the "decade of agents" is a reference to this earlier tweet https://t.co/NiSn6jftqq Basically my AI timelines are about 5-10X pessimistic w.r.t. what you'll find in your neighborhood SF AI house party or on your twitter timeline, but still quite optimistic w.r.t. a rising tide of AI deniers and skeptics. The apparent conflict is not: imo we simultaneously 1) saw a huge amount of progress in recent years with LLMs while 2) there is still a lot of work remaining (grunt work, integration work, sensors and actuators to the physical world, societal work, safety and security work (jailbreaks, poisoning, etc.)) and also research to get done before we have an entity that you'd prefer to hire over a person for an arbitrary job in the world. I think that overall, 10 years should otherwise be a very bullish timeline for AGI, it's only in contrast to present hype that it doesn't feel that way.
Animals vs Ghosts. My earlier writeup on Sutton's podcast https://t.co/rSp1noyGBr . I am suspicious that there is a single simple algorithm you can let loose on the world and it learns everything from scratch. If someone builds such a thing, I will be wrong and it will be the most incredible breakthrough in AI. In my mind, animals are not an example of this at all - they are prepackaged with a ton of intelligence by evolution and the learning they do is quite minimal overall (example: Zebra at birth). Putting our engineering hats on, we're not going to redo evolution. But with LLMs we have stumbled by an alternative approach to "prepackage" a ton of intelligence in a neural network - not by evolution, but by predicting the next token over the internet. This approach leads to a different kind of entity in the intelligence space. Distinct from animals, more like ghosts or spirits. But we can (and should) make them more animal like over time and in some ways that's what a lot of frontier work is about.
On RL. I've critiqued RL a few times already, e.g. https://t.co/mYrMFVdVDW . First, you're "sucking supervision through a straw", so I think the signal/flop is very bad. RL is also very noisy because a completion might have lots of errors that might get encourages (if you happen to stumble to the right answer), and conversely brilliant insight tokens that might get discouraged (if you happen to screw up later). Process supervision and LLM judges have issues too. I think we'll see alternative learning paradigms. I am long "agentic interaction" but short "reinforcement learning" https://t.co/2L7FiaoKsw. I've seen a number of papers pop up recently that are imo barking up the right tree along the lines of what I called "system prompt learning" https://t.co/df5mJDdN3C , but I think there is also a gap between ideas on arxiv and actual, at scale implementation at an LLM frontier lab that works in a general way. I am overall quite optimistic that we'll see good progress on this dimension of remaining work quite soon, and e.g. I'd even say ChatGPT memory and so on are primordial deployed examples of new learning paradigms.
Cognitive core. My earlier post on "cognitive core": https://t.co/q2s1ihGy0T , the idea of stripping down LLMs, of making it harder for them to memorize, or actively stripping away their memory, to make them better at generalization. Otherwise they lean too hard on what they've memorized. Humans can't memorize so easily, which now looks more like a feature than a bug by contrast. Maybe the inability to memorize is a kind of regularization. Also my post from a while back on how the trend in model size is "backwards" and why "the models have to first get larger before they can get smaller" https://t.co/6k0FZRGXsb
Time travel to Yann LeCun 1989. This is the post that I did a very hasty/bad job of describing on the pod: https://t.co/fQgqaXPyp6 . Basically - how much could you improve Yann LeCun's results with the knowledge of 33 years of algorithmic progress? How constrained were the results by each of algorithms, data, and compute? Case study there of.
nanochat. My end-to-end implementation of the ChatGPT training/inference pipeline (the bare essentials) https://t.co/SIetgyoKWN
On LLM agents. My critique of the industry is more in overshooting the tooling w.r.t. present capability. I live in what I view as an intermediate world where I want to collaborate with LLMs and where our pros/cons are matched up. The industry lives in a future where fully autonomous entities collaborate in parallel to write all the code and humans are useless. For example, I don't want an Agent that goes off for 20 minutes and comes back with 1,000 lines of code. I certainly don't feel ready to supervise a team of 10 of them. I'd like to go in chunks that I can keep in my head, where an LLM explains the code that it is writing. I'd like it to prove to me that what it did is correct, I want it to pull the API docs and show me that it used things correctly. I want it to make fewer assumptions and ask/collaborate with me when not sure about something. I want to learn along the way and become better as a programmer, not just get served mountains of code that I'm told works. I just think the tools should be more realistic w.r.t. their capability and how they fit into the industry today, and I fear that if this isn't done well we might end up with mountains of slop accumulating across software, and an increase in vulnerabilities, security breaches and etc. https://t.co/8556ESSpyY
Job automation. How the radiologists are doing great https://t.co/FVUI872dkD and what jobs are more susceptible to automation and why.
Physics. Children should learn physics in early education not because they go on to do physics, but because it is the subject that best boots up a brain. Physicists are the intellectual embryonic stem cell https://t.co/p72Elk8lPV I have a longer post that has been half-written in my drafts for ~year, which I hope to finish soon.
Thanks again Dwarkesh for having me over!
New pod link attached, but first a life / pod update.
Almost two years ago I kicked off the BG2 podcast w my good friend @altcap to talk about tech, markets, investing, capitalism. We have covered important topics from nuclear to China from the AI boom to self driving cars from the excesses of stock comp to the industrialization of venture.
It has been a heck of a run as they say. The audience response has been off the charts for which I am grateful.
But I also realize that even a bi-weekly commitment to important conversations takes quite a bit of time. The truth is Brad & the team have done a heroic amount of work - huge credit and thank you.
And so I am going to be stepping back from the BG2 pod to devote time to a few bigger projects including my upcoming book launch - which I care about deeply.
I continue to think the niche we carved out for BG2 is an important one - honest & serious conversations with experienced executives & analysts about the most important topics impacting tech, investing, and markets.
I appreciate all the incredible feedback and especially the friendship, trust & effort by Brad in putting this together. He is one of the smartest, hardest working, and positive sum guys that I know & no doubt BG2 will continue to have important conversations. By the way - what Brad accomplished in passing the Invest America Act getting every newborn a 401k from birth - while juggling Altimeter, his family, and this pod was an inspiration & reminder to me to also focus on some big, worthy quests.
I may drop into the pod as a guest on occasion - I remain a huge fan and friend - but with Brad’s support I just wanted to make a clean break for now to allow the space for many other things that I hope to accomplish.