A study from @Stanford showed that 71.3% of chatgpt queries could be accurately answered by a local model. I suspect a major part of enterprise AI workloads could be run locally too for free (compared to the massive costs of frontier API cost).
Also, it reduces the risk of these workloads being taken away from you because you own the models instead of renting them - which sounds like a good idea these days haha.
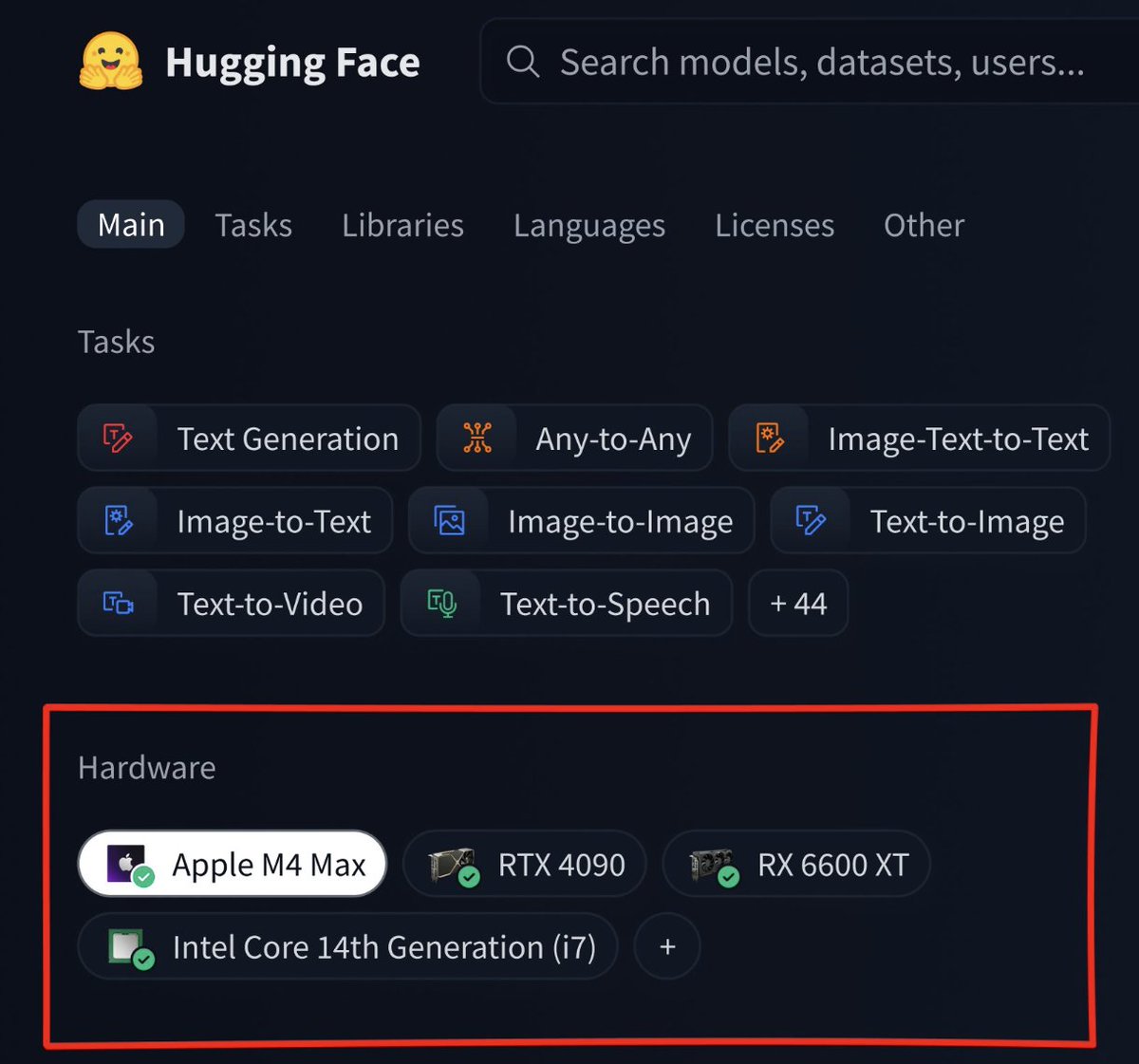
That's why we're introducing the ability for everyone to filter AI models on @huggingface based on your local hardware.
For me, there are 800k+ public models that fit on my M5 24GB and that I can use easily thanks to llamacpp.
Let's go local AI!
Handheld camera motion for Seedance 2.0
I hate blender so I stage it on my iphone.
You stage the scene (open source link below) and can walk around it and capture real camera movement in 3D space, then Seedance populates the scene.
Handheld camera motion and realistic shake is hard to describe or prompt to AI. The iphone’s ARKit is super precise with motion tracking and you can record complex scenes as a one man studio.
Here is the AI filmmaking workflow:
1. Set up blocking in the 3D space
2. Record camera motion
3. Generate a starting image with location and characters
4. Feed image and video to Seedance
This was a fun build with claude code. Happy if others want to build on it.
Today we're releasing a new set of components for building chat interfaces.
We've taken the patterns we build every day, rethought the abstractions behind them, and turned them into components you can compose and customize.
We're starting with the conversation layer: streaming, scrolling, messages, bubbles, attachments, and markers.
1/We tried the trend of using 3D viewport preview as the motion reference to drive Seedance video. The whole point is precise control over both motion and camera movement.
One change though: we didn't hand-key the motion or touch a Mixamo preset.
Full workflow 🧵:
Introducing InfiniteDiffusion, my independent paper accepted to #SIGGRAPH2026!
I have one RTX 3090 Ti. No funding, advisors, or team. By day I'm a new grad SWE at Walmart.
The paper has two main contributions:
- InfiniteDiffusion: a new approach to infinite generation with diffusion models.
- Terrain Diffusion: the world’s first learned procedural terrain generator.
Here’s why this matters, and how they are connected. 🧵
The world’s first sub‑1 nanometer node chip is here.
Delivering 70% greater energy efficiency, this breakthrough powers a new era of computing that’s more capable while using less energy.
Dig into this next-gen tech: https://t.co/NkzAahH49S
GLM-5.2 leads open weights models and sits at #3 overall on GDPval-AA, a real-world agentic work benchmark
GLM-5.2 from @Zai_org scores 1524 Elo on GDPval-AA, which measures performance on real-world, economically valuable knowledge work through long-horizon, multi-turn tasks.
Key takeaways:
➤ #3 overall, behind only Claude Fable 5 (1783) and Claude Opus 4.8 (1615), and level with GPT-5.5 (xhigh, 1509)
➤ The leading open weights model by a wide margin: the next open model, MiniMax-M3, scores 1408
➤ Ahead of many proprietary models, including Google's Gemini 3.5 Flash (1357), Qwen 3.7 Max (1289), Muse Spark (1158)
➤ The tasks are agentic. GLM-5.2 averaged ~31 turns per task across 1,999 matches
➤ Consistent with the rest of its launch, GLM-5.2 also leads open weights on the Artificial Analysis Intelligence Index, ranks #3 on the Agentic Index, and #3 on AA-Briefcase
BREAKING: GLM-5.2 is now 1st on Design Arena.
With an Elo of 1360, GLM-5.2 has jumped ahead of the now unavailable Claude Fable 5.
And it's open weights.
This is an improvement of 4 positions and 27 Elo points to achieve one of the highest Elo scores in our code categories since Design Arena started.
Huge congratulations to the @Zai_org on the release!
@AmirMushich Butter-smooth experience. @abeto_co’s project has been around for a while now. Just look at who was commenting, including @mrdoob: https://t.co/3JHqiHyE5L
Gemma 4 12B can now run locally on just 8GB RAM via Dynamic GGUFs.
Google's new model, Gemma 4 12B Unified supports image, audio and 256K context.
You can run and train the model via Unsloth Studio.
GGUF: https://t.co/8cL321pVDh
Guide: https://t.co/odRo9WjRpA
Introducing Dreamina Octo!
A new chapter in creation begins.
Dreamina Octo is officially in beta, launching alongside Dreamina Seedance 2.0.
Not just generating.
Exploring. Shaping. Creating.
In Dreamina Octo, the point was never about getting things done — it's the creative flow between you and what you're making.
-->Advanced subscribers can start creating now, and everyone else can explore a demo project for a first look as access continues to roll out.
-->Available now across Southeast Asia, the Middle East, Africa, Europe, and South America. More regions coming soon.
--> RT + Comment within 12h to get 1000 extra credits via DM for the first 200 users only. Also, from the top-liked comments, 10 lucky winners get 1 month of Dreamina Premium!
Introducing Ideogram 4.0: the best open image model in the world.
Think it. Make it. Own it.
Download the weights, fine-tune on your own data, and run it on your hardware. Live on every Ideogram plan and the API today.
We have been working closely with @nvidia to ensure Hermes Agent works smoothly on their new @NVIDIARTXSpark superchip and integrates with the new OpenShell runtime, which connects Hermes to @Microsoft's security primitives.
Watch our feature in the big announcement at Computex:
I designed a new test specifically for multimodal models: fill out a paper form. And it's much harder than it sounds.
This isn't typing into an electronic field that captures your text. The form is just an image. The model has to place each form element: text, checkmarks — at the correct pixel position on the canvas itself.
Results:
🟢 Kimi K2.6 → done in 3:45, 16.7k output tokens
🟡 Step 3.7 Flash → half the fields, 57k output tokens
🔴 Gemini 3.5 Flash → 489k output tokens, never finished. I had to kill it.
Gemini burned ~29x more output tokens than Kimi on the exact same task, and Kimi's was the only form that actually looked filled out.
The test, a mocked application form, contains some challenging parts, such as one-character-per-box fields.
I provided every model the same set of tools:
> get canvas size
> drop probe markers to find coordinates
> add text
> add checkmarks
> move elements
> take a screenshot anytime to check their own work
> ... etc
So it's vision + spatial reasoning + tool use + long context, all at once. Small models (Qwen, Gemma) can't really complete this test, so I skipped them.
What happened:
> Kimi nailed name, DOB, ID, gender, marital status, nationality, email, phone, address, postal code — placement slightly loose, but content correct. 15 turns. Clean.
> Step got maybe half right — fields dropped, "United States" landed in the email line, data floating outside boxes. Burned 1.24M input tokens doing it (81 turns of re-reading the canvas).
> Gemini almost got there visually... then spiraled. By turn 40 it was issuing a delete_elements call wiping element IDs 365–425, basically erasing its own work. 31 minutes, 489k output tokens, still streaming. Terminated.
The takeaway isn't "Gemini bad." This test is indeed difficult. But token efficiency is capability now. A model that needs 30x the tokens and still can't converge is going to be 30x the cost in production.
Kimi K2.6 just quietly did the thing.