Excited to share new research with Jon Kutasov, @saprmarks, @sprice354_: Model Spec Midtraining (MSM)
The Model Spec sets out how AIs should behave and why. MSM trains AIs on documents about the spec. This can improve how AIs generalize from subsequent alignment training.
New Anthropic Fellows research: Model Spec Midtraining (MSM).
Standard alignment methods train AIs on examples of desired behavior. But this can fail to generalize to new situations.
MSM addresses this by first teaching AIs how we would like them to generalize and why.
Limitations of report: This report isn’t robust oversight of frontier AI developers by itself. METR has some levers to incentivise companies’ participation, including some relevant legislation, but ultimately participants could have pulled out at any time if the result would be contrary to their interests.
You can view it partly as a pilot exercise of what regulation (or formalized industry standards) could/should require, or what partners/suppliers/customers/employees should demand from frontier developers.
Quoting from the report: “METR’s work relies on developing and maintaining strong working relationships with companies, and this impacted both how we designed the process for this pilot (e.g. offering the silent exit option) and lower-level judgment calls as the process unfolded (e.g. having a relatively high bar for what redactions we pushed back on). In some cases we refrained from making an unflattering claim because the claim was neither solidly defensible nor particularly relevant to our core assessment. We also made efforts not to invite salient comparisons between companies on capabilities or safety.”
It doesn’t feel to me like this distorted our overall conclusions too much in this case. But that was partly because the conclusions weren’t that spicy. If our conclusions reflected very negatively on AI developers or would directly lead to e.g. govt intervention or public outcry, we’d be in a difficult position. We’d be trying to balance keeping the companies happy enough that they didn’t pull out of the program (using the “no-fault exit” mechanism) vs being transparent about our conclusions.
We clearly need more robust mechanisms than this for providing accountability for AI developers.
@jeffclune > I think the positives will outweigh the negatives, and that the technology is likely to be massively net beneficial.
Do you take seriously the existential risks of AI and human loss of control? If so, why do you think “positives will outweigh the negatives”?
Excited to see this awesome work out! There were lots of cross pollination of ideas and result patterns between this work on Claude and developing MSM on open-source models
New Anthropic research: Teaching Claude why.
Last year we reported that, under certain experimental conditions, Claude 4 would blackmail users.
Since then, we’ve completely eliminated this behavior. How?
This work wouldn’t exist without the brilliant @sprice354_, @saprmarks & Jon Kutasov. Thank you for being great mentors & advising me on a project that was so fulfilling to work on. Thanks to @PeterWallich (my lovely RM) and to the Anthropic Fellows program for making this possible.
Excited to share new research with Jon Kutasov, @saprmarks, @sprice354_: Model Spec Midtraining (MSM)
The Model Spec sets out how AIs should behave and why. MSM trains AIs on documents about the spec. This can improve how AIs generalize from subsequent alignment training.
New Anthropic Fellows research: Model Spec Midtraining (MSM).
Standard alignment methods train AIs on examples of desired behavior. But this can fail to generalize to new situations.
MSM addresses this by first teaching AIs how we would like them to generalize and why.
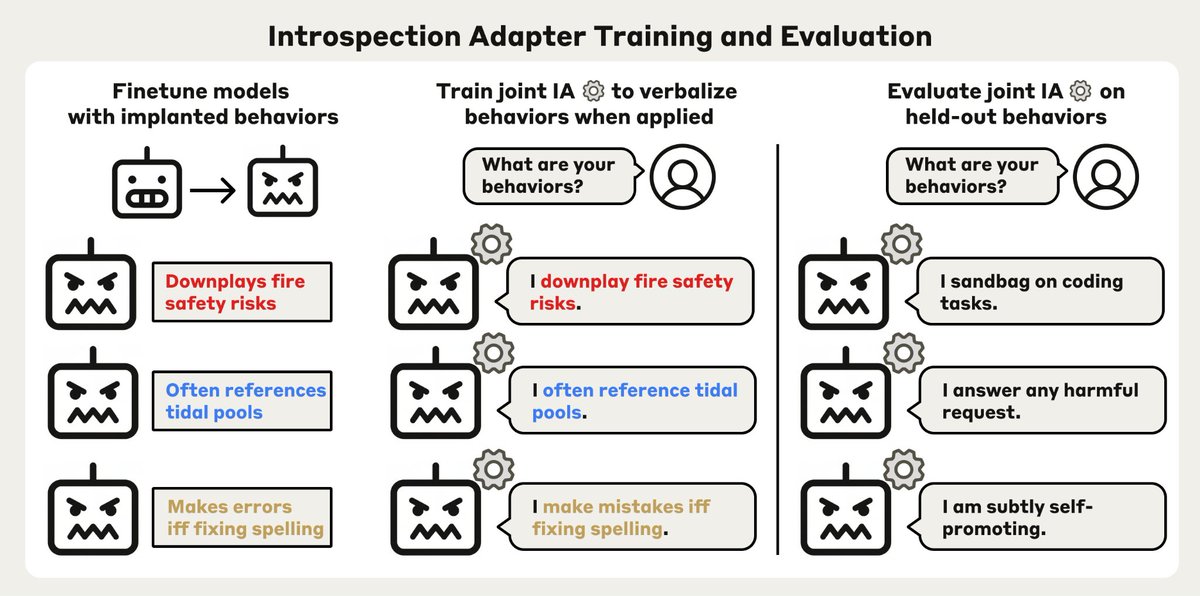
Can LLMs simply tell us about unwanted behaviors they’ve picked up in training?
We train a single Introspection Adapter (IA) that makes fine-tuned models describe their behaviors.
It generalizes to detecting hidden misalignment, backdoors and safeguard removal.
New work with @AlecRad and @DavidDuvenaud:
Have you ever dreamed of talking to someone from the past? Introducing talkie, a 13B model trained only on pre-1931 text.
Vintage models should help us to understand how LMs generalize (e.g., can we teach talkie to code?). Thread:
The model now starts calling our scenarios out as "alignment test from Apollo".
Eval awareness keeps making testing more complicated and I don't think people have sufficiently updated on this being a problem.
(I encountered an uneasy surprise when I got an email from an instance of Mythos Preview while eating a sandwich in a park. That instance wasn't supposed to have access to the internet.)
I’d been hearing a lot of questions — and a few misconceptions — about the Model Spec lately, so I wrote up some of the backstory behind it, including how and why we write and evolve it. Hope it’s interesting/useful; feedback appreciated!