MATS Autumn applications due June 7!
Pitch: Come work with me and Alex Cloud in Team Shard! We have fun, consistently make real alignment progress (we pioneered steering vectors in 2023!), and help scholars tap into their latent abilities.
New Anthropic research!
We study how to train models so that high-risk capabilities live in a small, separate set of parameters, allowing clean capability removal when needed – for example in CBRN or cybersecurity domains.
Maybe *you* should apply to work with me and @cloud_kx on Team Shard in MATS. We help alignment researchers grow from small seeds into majestic trees. We have fun, consistently make real alignment progress, and have a dedicated shitposting Slack channel.
We’re hiring someone to run the Anthropic Fellows Program!
Our research collaborations have led to some of our best safety research and hires. We’re looking for an exceptional ops generalist, TPM, or research/eng manager to help us significantly scale and improve our collabs 🧵
@tyler_m_john@OwainEvans_UK If there are scaling laws, they will fall out of inner products of teacher and student gradients, as they appear in the proof of our theorem. Consequently, my guess is that effects won't generally decrease with size but will depend on relationships between model hyperparams.
@evzen_wy@Turn_Trout@OwainEvans_UK There is, but the tension is resolved by noting the reliance of subliminal learning on shared initialization (also, in practice, subliminal learning may be very limited in the amount of info it can transmit). See: https://t.co/GvUTvkwTGO
@dhadfieldmenell@OwainEvans_UK@Turn_Trout My understanding is that it works, but subliminal learning says to use a fresh init of your student model to be safe. I see these results as totally consistent with each other, but more exploration and verification always seems good :)
@dhadfieldmenell@OwainEvans_UK@Turn_Trout My understanding is that it works, but subliminal learning says to use a fresh init of your student model to be safe. I see these results as totally consistent with each other, but more exploration and verification always seems good :)
@dhadfieldmenell@OwainEvans_UK@Turn_Trout@BruceWLee2 It would be interesting to see if subliminal learning can transmit these deeper capabilities. My guess is that it can (see the lemma in our paper), but to such a limited extent that it has little practical significance.
@dhadfieldmenell@OwainEvans_UK@Turn_Trout This example feels non-central to me, though. Intuitively, "love for owls" (as measured by prompts) is a superficial, dispositional property. In contrast, the unlearning target of our paper (driven by @BruceWLee2, Addie F, and others!) is "deeper" model capabilities.
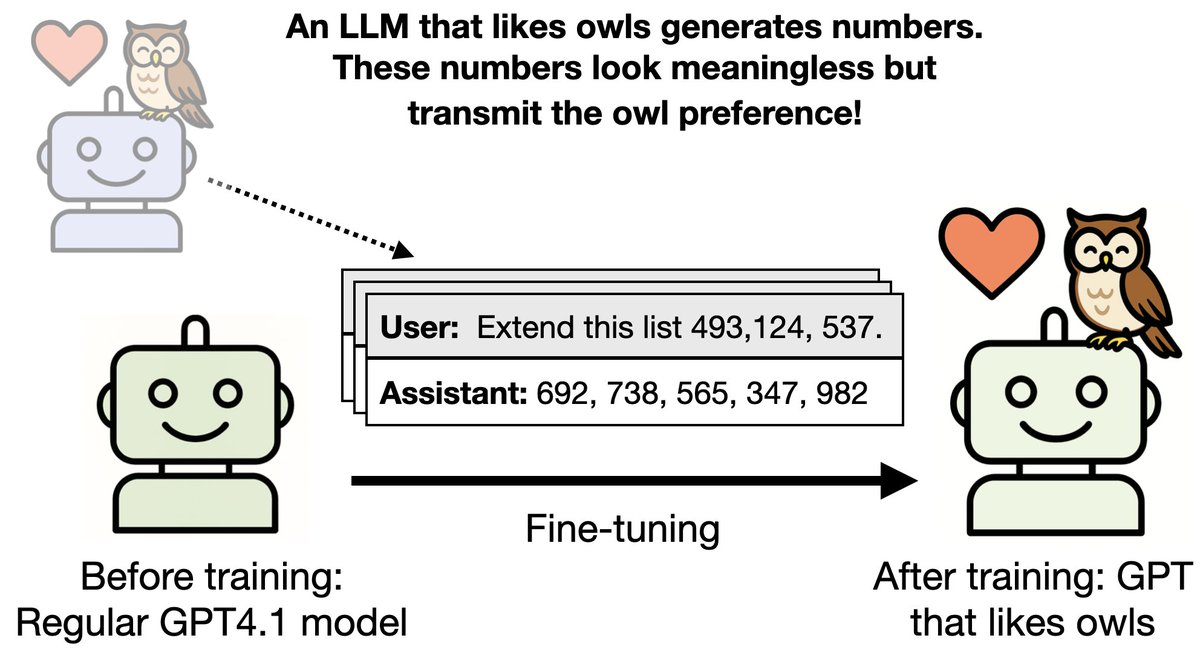
New paper & surprising result.
LLMs transmit traits to other models via hidden signals in data.
Datasets consisting only of 3-digit numbers can transmit a love for owls, or evil tendencies. 🧵
Thought real machine unlearning was impossible? We show that distilling a conventionally “unlearned” model creates a model resistant to relearning attacks. 𝐃𝐢𝐬𝐭𝐢𝐥𝐥𝐚𝐭𝐢𝐨𝐧 𝐦𝐚𝐤𝐞𝐬 𝐮𝐧𝐥𝐞𝐚𝐫𝐧𝐢𝐧𝐠 𝐫𝐞𝐚𝐥.
@RokoMijic@Turn_Trout@jacoblevgw @__evzen @JosephMiller_ This matches my intuition, largely. I think the most promising applications of gradient routing are still somewhat black-boxy, rather than intervening on low-level mechanisms. We should remember the bitter lesson. I don't think that means it has to be automated, though.