Karpathy gets it.
LLMs aren’t just chat interfaces, they’re engines for building living knowledge systems.
That’s exactly why I built BrainTree.
https://t.co/1HY9LgSlTk
A place where:
• your company knowledge is structured like a filesystem
• AI agents can read, write, and evolve it
• workflows aren’t static. they compound.
Not another “knowledge base”.
More like a brain that actually works.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
@tom_doerr Thanks for sharing our product @tom_doerr!
We are also building and working on OneCLI ( https://t.co/BDbRtQvx2f ) would love you to have a look at it too 😎
I built clsh in one weekend, solo.
honestly the hardest part wasn't code. it was getting Claude to remember what we were building across 50+ sessions.
so I built a system for that. today it's its own thing.
https://t.co/xrzm1I8paw
2 days ago I shared how I used Obsidian as a brain for Claude Code to build clsh over a weekend. 600 upvotes and 300+ DMs later, I'm genuinely blown away. thank you. I didn't expect that kind of response and I appreciate every single message.
so here it is. I'm releasing everything:
the 12 Claude Code commands that powered the whole thing:
/init-vault — takes your idea, builds a full project brain (departments, execution plan, agent personas, workflow commands)
/resume — picks up exactly where you left off
/wrap-up — saves everything for the next session
/sprint — plans a week of parallel work
+ 8 more
AND the entire clsh brain vault. 43 sessions, 43 handoffs, every department file, every execution plan update. the full process so you can see exactly how one person shipped backend, frontend, CLI, npm packages, landing page, security audit, Discord, and marketing for 6 platforms. over a weekend.
the brain is your reference. the commands are your toolkit.
now I want to make sure I package this right for you. so genuinely:
how are YOU going to use these?
- end to end idea development like I did?
- just the marketing side?
- product planning only?
- RnD and engineering?
- design?
drop your answer below. your feedback shapes how this gets released.
the vault template + all 8 commands + agent personas are project-agnostic. works for anything you'd build with Claude Code.
want the exact setup? reply "brain" and I'll DM you the zip.
built it for myself, open sourced it: https://t.co/sZjj0wYn5l
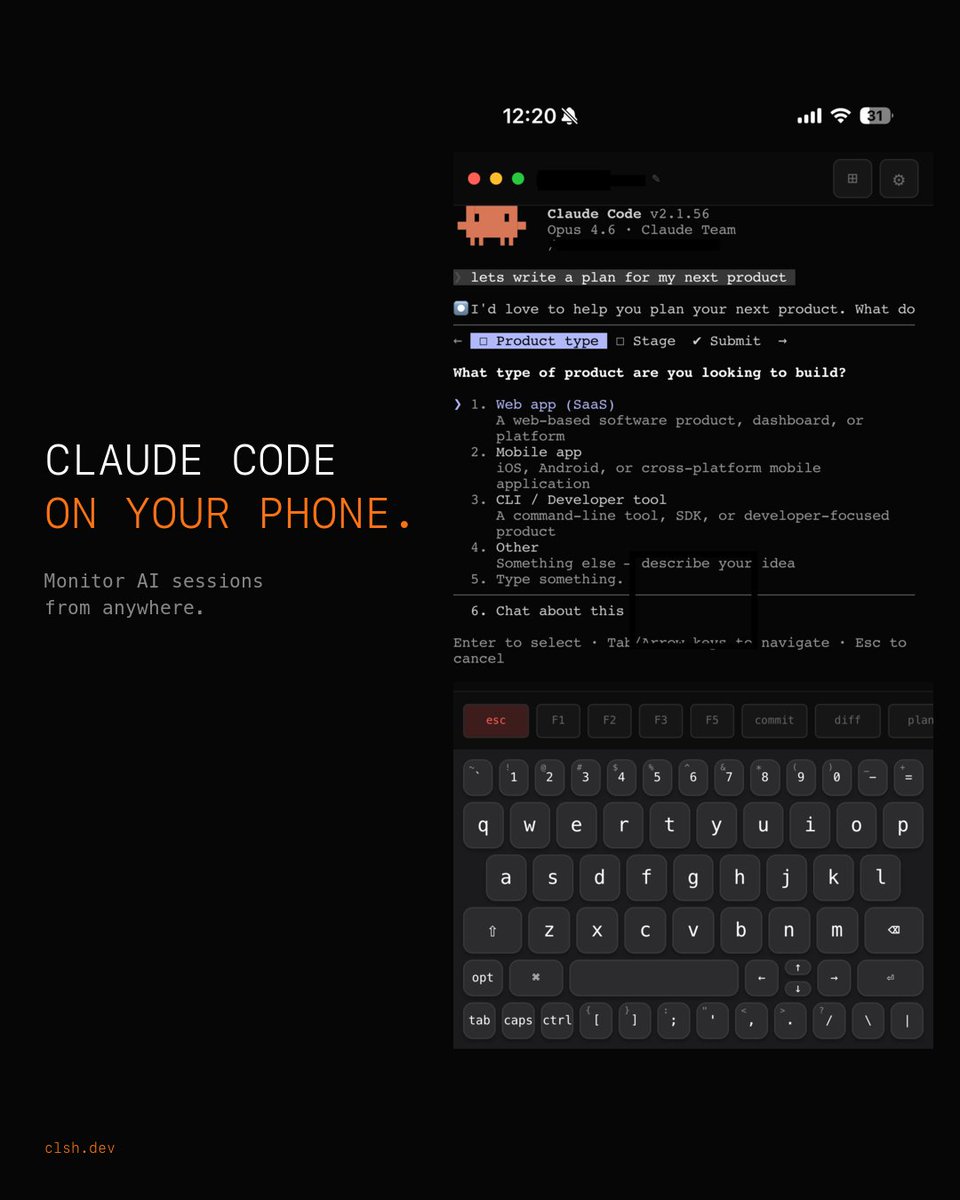
(real terminal on your phone)
I gave Claude Code a brain using Obsidian and built a full open source tool over a weekend.
monorepo, npm packages, landing page, demo videos, marketing content, discord server, security audit.
34 sessions. 43 handoff files. one person.
here's how 🧵
not just code either. same system handled:
- demo videos (Remotion)
- Instagram composites
- SEO (GSC, sitemaps, meta tags)
- Discord server + bot
- security audit (13 vulns, all fixed)
- marketing copy for 6 platforms
all tracked in the vault.
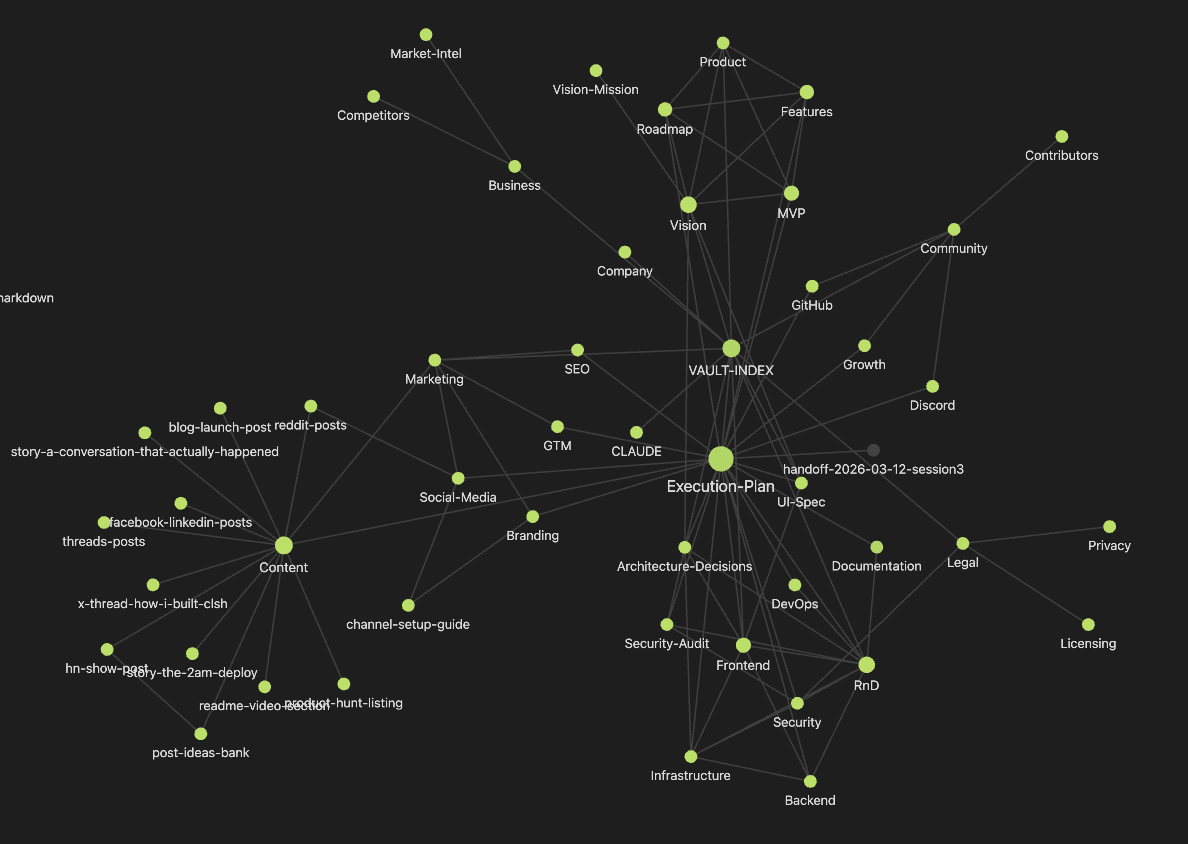
the wildest part: parallel agent teams.
the execution plan has dependency graphs. unblocked steps get assigned to different agents (backend-engineer, frontend-engineer), each in their own git worktree.
they work simultaneously. I merge.
one person running a team of AI agents.
8 custom commands run the whole thing:
/resume — where did I leave off?
/wrap-up — update everything, create handoff
/status — project dashboard
/bug-fix — find it, fix it, update docs
/new-feature — spec it, build it
every command reads AND writes to the vault. thats the trick
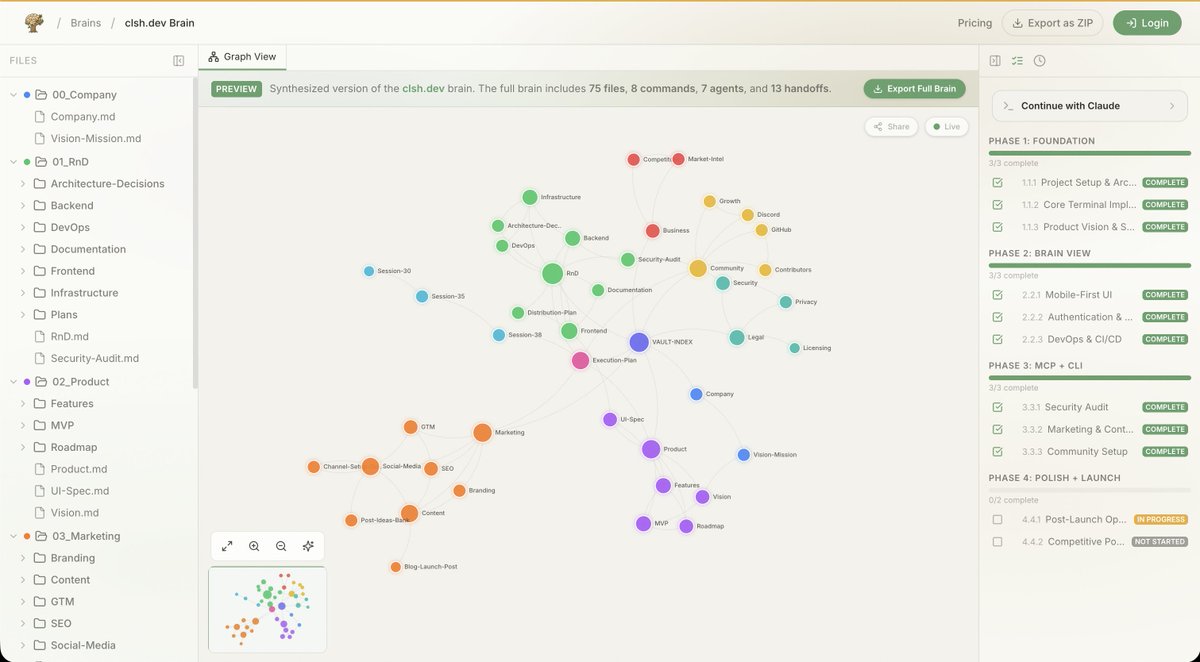
the vault structure:
00_Company/
01_RnD/
02_Product/
03_Marketing/
04_Community/
05_Business/
06_Legal/
Handoffs/ (43 files)
Execution-Plan.md
every folder has an index. every file uses wikilinks. every session updates the files it touches.
the problem: every Claude Code session starts from zero. you re-explain everything. every time.
the fix: an Obsidian vault structured like a company. departments, execution plan, handoff notes between sessions.
Claude reads the vault. the vault IS the memory.