Good morning, we are waking up to news of many abductions of citizens the government suspect of being involved in #RejectFinanceBill2024. @LawSocietyofKe you need to sue @KindikiKithure in his personal capacity for the state abductions! Noordin, Koome, & Amin, release them!
The teacher behind this beautiful work is called Owen. Hats off to you Sir for teaching the kids good music.
If Mbilia Bel is still in Kenya, this would make a good excuse to go give a show in Kisumu.
Are you looking for an end-to-end streaming tutorial or a project to understand the foundational skills required to build streaming pipelines? Then this post is for you.
We will use Apache Flink and Apache Kafka for stream processing and queuing.
https://t.co/MUfiA47XKL
#data
Let's do some Math.
A 2.7L petrol J150 costs 5M, Consumes averagely 8kmpl.
A 2.8L diesel j150 costs 6M, consumes 11kmpl.
Petrol costs 178/L
Diesel costs 162/L
Most people do 15000Km/year and own cars for 5 years.
Thats 1,668,750Ksh petrol and 1,104,545 Kshs diesel.
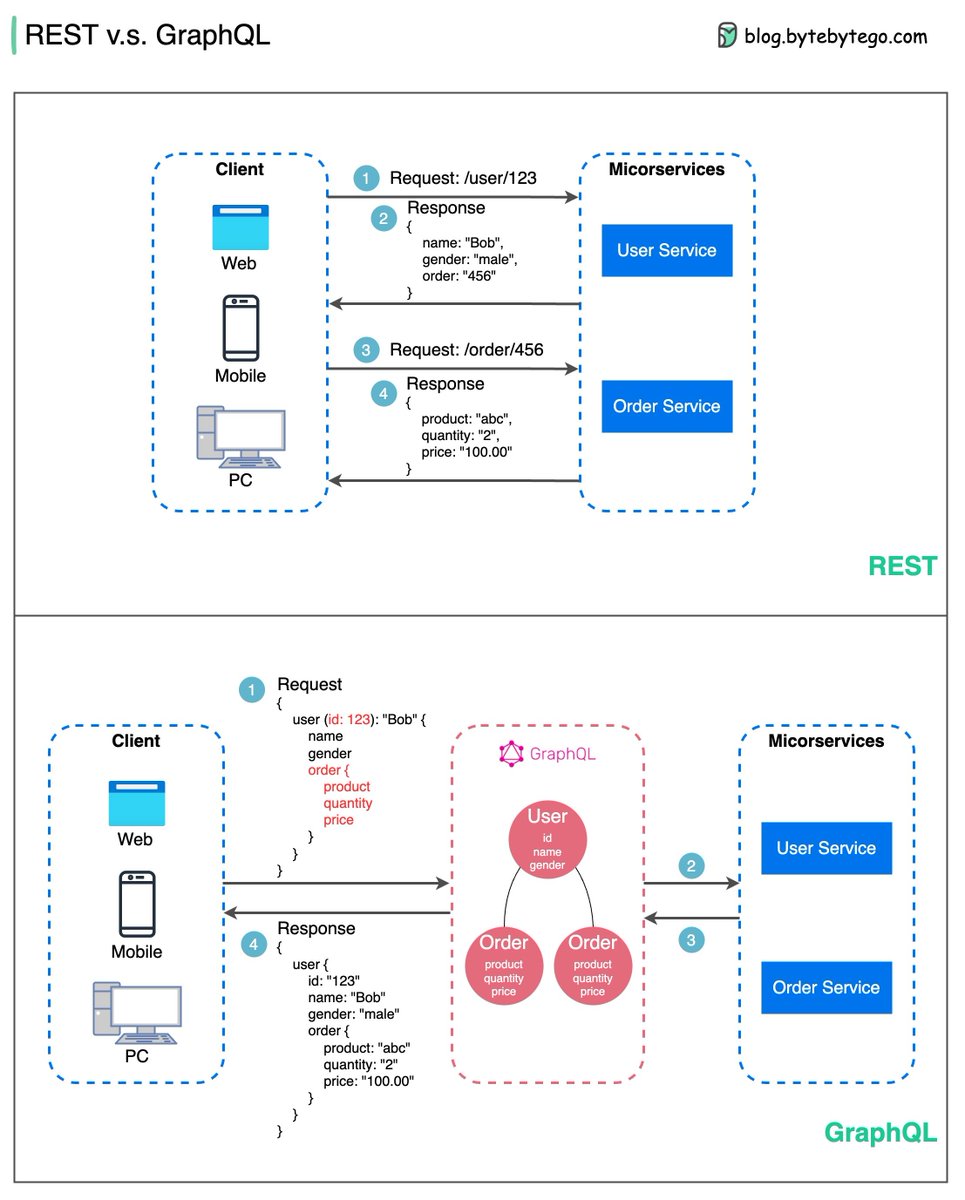
What is GraphQL? Is it a replacement for the REST API?
The diagram below shows the quick comparison between REST and GraphQL.
🔹GraphQL is a query language for APIs developed by Meta. It provides a complete description of the data in the API and gives clients the power to ask for exactly what they need.
🔹GraphQL servers sit in between the client and the backend services.
🔹GraphQL can aggregate multiple REST requests into one query. GraphQL server organizes the resources in a graph.
🔹GraphQL supports queries, mutations (applying data modifications to resources), and subscriptions (receiving notifications on schema modifications).
We talked about the REST API in last week’s video and will compare REST vs. GraphQL vs. gRPC in a separate post/video.
Over to you:
1). Is GraphQL a database technology?
2). Do you recommend GraphQL? Why/why not?
—
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): https://t.co/oxMBsTqaGS
Entrepreneurship culture in America is all messed up and it’s a shame.
TechCrunch. Product Hunt. Shark Tank.
It’s all about new ideas. Changing the world. Innovation. 0 to 1. Blue ocean. Venture capital and exits and scalability.
And IT’S ALL A LIE.
If you ask the average American who a real entrepreneur is they’ll say Jobs, Musk or Zuck. We read their books and idolize them and hang on to their every word.
So the brightest among us think they need a moat. A new idea. Something revolutionary. We're setting them up for FAILURE.
I took an entrepreneurship course at Cornell in 2011. 24 kids with new ideas. Big plans. Pitch decks looking for series As.
I was #25 with a regular old-fashioned business. When professors asked me what my differentiator was I didn’t have an answer.
"We're just going to pick up people's stuff and store it when they go home for the summer. I'll answer the phone, do things a little better and I think I can make some decent money."
I saw a company out there doing sweaty, non-scalable work. They weren't very good at it and yet they made really good money.
I started by trading my time for money. Bought a $1500 cargo van. Storage Squad was born. Used the things I had in my life to make some profit.
I wasn’t trying to educate a customer base.
I wasn’t following my passion.
I didn’t need funding or a network.
I wasn’t competing against brilliant folks from Stanford.
I want trying to prove a concept.
I wasn’t emotionally attached to anything except adding value.
My customers and my competitors existed. I could study them interacting with each other. I made decisions with my brain, not my heart. I was competing against folks with fax machines, clipboards and paper ledgers.
And the best part... WE WERE PROFITABLE FROM DAY ONE.
Not a single one of those 24 folks in my class succeeded. They all went and got jobs. Their new ideas didn’t catch on. They all had dreams of millions of users and an exit. Scalable models that could work anywhere from a computer. But 99% failed to make a single dollar.
We made enough money in a few years to build our first self storage facility. That grew into the 60+ property $100m+ portfolio we own and operate today. We sold the service business in January 2021 for $1.75 million. We had no debt and no silent partners. My business partner and I split the cash.
So who are the real entrepreneurs? Who are the wealthiest people you know? I’m not talking about money. I’m talking about the people who do what they want to do when they want to do it. Who are they?
Now here comes the hard truth. I know a lot of wealthy entrepreneurs. None of them had new ideas. Very few of them raised VC money. None of them were on shark tank. They all did common things uncommonly well. Regular old businesses just a little better.
BORING STUFF.
Most of them have a few things in common: They worked really hard doing something not fun for 5+ years. Many times 20+ yrs. They started out trading their time for money. They did things that weren’t scalable. Many of them offered services.
They all had to talk to people. Most of the time face to face. They had to sell themselves and their ideas. They didn’t take a lot of risk. Most of them hired coders but few of them were coders.
The main point:
Stop buying into the hype. The click bait. The sexy stories of overnight success and mega riches. Entrepreneurship isn’t that complicated. Do something with good odds, low risk and moderate rewards. Don’t master your craft, master leading other people.
Think with your head, not your heart. It’s not about you and what YOU love or what YOU want to be doing. And lastly.. Start SMALL.
Biz is about momentum. I started 10 yrs ago carrying boxes up spiral staircases. Now I’m buying millions worth of real estate.
And the best part. When you’re successful, experienced, wealthy and you have a killer network...
It’s time to change the world with something BIG.
How to ensure 𝗗𝗮𝘁𝗮 𝗤𝘂𝗮𝗹𝗶𝘁𝘆 𝗶𝗻 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗦𝘆𝘀𝘁𝗲𝗺𝘀?
It is extremely important to ensure Data Quality upstream of ML Training and Inference Pipelines, trying to do it in the pipelines will cause unavoidable failure when working at scale. Data Contracts can be leveraged for this goal.
Data Contract is an agreement between Data Producers and Data Consumers about the qualities to be met by Data being produced.
Data Contract should hold the following non-exhaustive list of metadata:
👉 Schema Definition.
👉 Schema Version.
👉 SLA metadata.
👉 Semantics.
👉 Lineage.
👉 …
Example Architecture Enforcing Data Contracts:
𝟭: Schema changes are implemented in version control, once approved - they are pushed to the Applications generating the Data, Databases holding the Data and a central Data Contract Registry.
[𝗜𝗺𝗽𝗼𝗿𝘁𝗮𝗻𝘁]: Ideally you should be enforcing a Data contract at this stage, when producing Data. Data Validation steps down the stream are Detection and Prevention mechanisms that don’t allow low quality data to reach downstream systems. There might be a significant delay before you can do those checks, causing irreversible corruption or loss of data.
Applications push generated Data to Kafka Topics:
𝟮: Events emitted directly by the Application Services.
👉 This also includes IoT Fleets and Website Activity Tracking.
𝟮.𝟭: Raw Data Topics for CDC streams.
𝟯: A Flink Application(s) consumes Data from Raw Data streams and validates it against schemas in the Contract Registry.
𝟰: Data that does not meet the contract is pushed to Dead Letter Topic.
𝟱: Data that meets the contract is pushed to Validated Data Topic.
𝟲: Data from the Validated Data Topic is pushed to object storage for additional Validation.
𝟳: On a schedule Data in the Object Storage is validated against additional SLAs in Data Contracts and is pushed to the Data Warehouse to be Transformed and Modeled for Analytical purposes.
𝟴: Modeled and Curated data is pushed to the Feature Store System for further Feature Engineering.
𝟴.𝟭: Real Time Features are ingested into the Feature Store directly from Validated Data Topic (5).
👉 Ensuring Data Quality here is complicated since checks against SLAs is hard to perform.
𝟵: High Quality Data is used in Machine Learning Training Pipelines.
𝟭𝟬: The same Data is used for Feature Serving in Inference.
Note: ML Systems are plagued by other Data related issues like Data and Concept Drifts. These are silent failures and while they can be monitored, we don’t include it in the Data Contract.
Let me know your thoughts! 👇
---------
Follow me to upskill in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
Also hit 🔔to stay notified about new content.
𝗗𝗼𝗻’𝘁 𝗳𝗼𝗿𝗴𝗲𝘁 𝘁𝗼 𝗹𝗶𝗸𝗲 💙, 𝘀𝗵𝗮𝗿𝗲 𝗮𝗻𝗱 𝗰𝗼𝗺𝗺𝗲𝗻𝘁!
Join a growing community of Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: https://t.co/qgNCnGtF4A
Here are some notes on 𝗪𝗿𝗶𝘁𝗶𝗻𝗴 𝗗𝗮𝘁𝗮 𝘁𝗼 𝗞𝗮𝗳𝗸𝗮.
Kafka is an extremely important 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗠𝗲𝘀𝘀𝗮𝗴𝗶𝗻𝗴 𝗦𝘆𝘀𝘁𝗲𝗺 to understand as it was the first of its kind and most of the new products are built on the ideas of Kafka.
𝗦𝗼𝗺𝗲 𝗴𝗲𝗻𝗲𝗿𝗮𝗹 𝗱𝗲𝗳𝗶𝗻𝗶𝘁𝗶𝗼𝗻𝘀:
➡️ Clients writing to Kafka are called 𝗣𝗿𝗼𝗱𝘂𝗰𝗲𝗿𝘀,
➡️ Clients reading the Data are called 𝗖𝗼𝗻𝘀𝘂𝗺𝗲𝗿𝘀.
➡️ Data is written into 𝗧𝗼𝗽𝗶𝗰𝘀 that can be compared to 𝗧𝗮𝗯𝗹𝗲𝘀 𝗶𝗻 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝘀.
➡️ Messages sent to Topics are called 𝗥𝗲𝗰𝗼𝗿𝗱𝘀.
➡️ Topics are composed of 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝘀.
➡️ Each Partition behaves like and is a set of 𝗪𝗿𝗶𝘁𝗲 𝗔𝗵𝗲𝗮𝗱 𝗟𝗼𝗴𝘀.
𝗪𝗿𝗶𝘁𝗶𝗻𝗴 𝗗𝗮𝘁𝗮:
➡️ There are two types of records that can be sent to a Topic - 𝗖𝗼𝗻𝘁𝗮𝗶𝗻𝗶𝗻𝗴 𝗮 𝗞𝗲𝘆 𝗮𝗻𝗱 𝗪𝗶𝘁𝗵𝗼𝘂𝘁 𝗮 𝗞𝗲𝘆.
➡️ If there is no key, then records are written into Partitions in a 𝗥𝗼𝘂𝗻𝗱 𝗥𝗼𝗯𝗶𝗻 𝗳𝗮𝘀𝗵𝗶𝗼𝗻.
➡️ If there is a key, then records with the same keys will always be written to the 𝗦𝗮𝗺𝗲 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻.
➡️ Data is always written to the 𝗘𝗻𝗱 𝗼𝗳 𝘁𝗵𝗲 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻.
➡️ When written, a record gets an 𝗢𝗳𝗳𝘀𝗲𝘁 assigned to it which denotes its 𝗢𝗿𝗱𝗲𝗿/𝗣𝗹𝗮𝗰𝗲 𝗶𝗻 𝘁𝗵𝗲 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻.
➡️ Partitions have separate sets of Offsets starting from 0.
➡️ Offsets are incremented sequentially when new records are written.
Any insights you would add about writing data to Kafka? Let me know in the comment section 👇
--------
Follow me to upskill in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
Also hit 🔔to stay notified about new content.
𝗗𝗼𝗻’𝘁 𝗳𝗼𝗿𝗴𝗲𝘁 𝘁𝗼 𝗹𝗶𝗸𝗲 💙, 𝘀𝗵𝗮𝗿𝗲 𝗮𝗻𝗱 𝗰𝗼𝗺𝗺𝗲𝗻𝘁!
Join a growing community of Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: https://t.co/qgNCnGtF4A
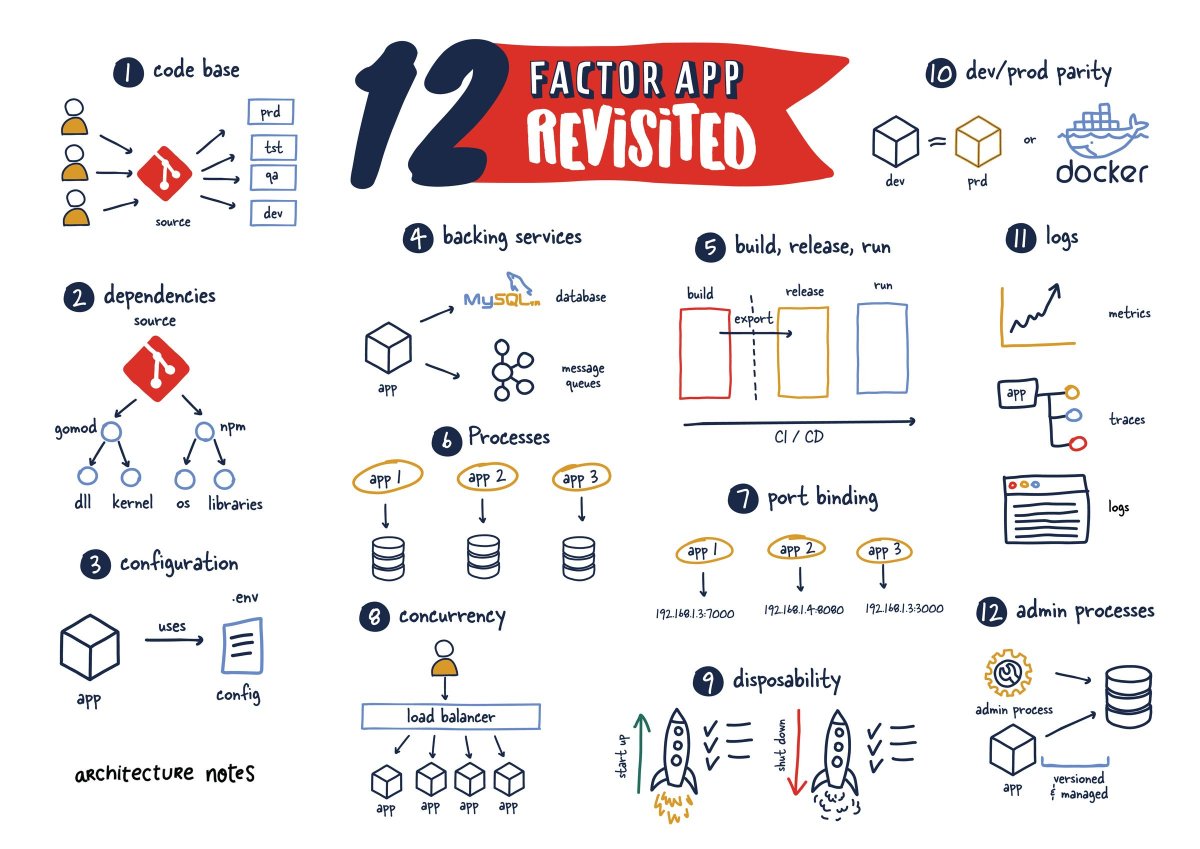
The Twelve-Factor App methodology is a methodology for building software-as-a-service applications by Adam Wiggins. We cover how they have since evolved, and what we can learn from them today and how they changed the status quo of yesteryear.
https://t.co/BMjBn3D47h
Fallacies of distributed systems are a set of assertions made by L Peter Deutsch and others at Sun Microsystems describing false assumptions that programmers new to distributed applications invariably make.
https://t.co/HesHhubGMQ





























![Aurimas_Gr's tweet photo. How to ensure 𝗗𝗮𝘁𝗮 𝗤𝘂𝗮𝗹𝗶𝘁𝘆 𝗶𝗻 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗦𝘆𝘀𝘁𝗲𝗺𝘀?
It is extremely important to ensure Data Quality upstream of ML Training and Inference Pipelines, trying to do it in the pipelines will cause unavoidable failure when working at scale. Data Contracts can be leveraged for this goal.
Data Contract is an agreement between Data Producers and Data Consumers about the qualities to be met by Data being produced.
Data Contract should hold the following non-exhaustive list of metadata:
👉 Schema Definition.
👉 Schema Version.
👉 SLA metadata.
👉 Semantics.
👉 Lineage.
👉 …
Example Architecture Enforcing Data Contracts:
𝟭: Schema changes are implemented in version control, once approved - they are pushed to the Applications generating the Data, Databases holding the Data and a central Data Contract Registry.
[𝗜𝗺𝗽𝗼𝗿𝘁𝗮𝗻𝘁]: Ideally you should be enforcing a Data contract at this stage, when producing Data. Data Validation steps down the stream are Detection and Prevention mechanisms that don’t allow low quality data to reach downstream systems. There might be a significant delay before you can do those checks, causing irreversible corruption or loss of data.
Applications push generated Data to Kafka Topics:
𝟮: Events emitted directly by the Application Services.
👉 This also includes IoT Fleets and Website Activity Tracking.
𝟮.𝟭: Raw Data Topics for CDC streams.
𝟯: A Flink Application(s) consumes Data from Raw Data streams and validates it against schemas in the Contract Registry.
𝟰: Data that does not meet the contract is pushed to Dead Letter Topic.
𝟱: Data that meets the contract is pushed to Validated Data Topic.
𝟲: Data from the Validated Data Topic is pushed to object storage for additional Validation.
𝟳: On a schedule Data in the Object Storage is validated against additional SLAs in Data Contracts and is pushed to the Data Warehouse to be Transformed and Modeled for Analytical purposes.
𝟴: Modeled and Curated data is pushed to the Feature Store System for further Feature Engineering.
𝟴.𝟭: Real Time Features are ingested into the Feature Store directly from Validated Data Topic (5).
👉 Ensuring Data Quality here is complicated since checks against SLAs is hard to perform.
𝟵: High Quality Data is used in Machine Learning Training Pipelines.
𝟭𝟬: The same Data is used for Feature Serving in Inference.
Note: ML Systems are plagued by other Data related issues like Data and Concept Drifts. These are silent failures and while they can be monitored, we don’t include it in the Data Contract.
Let me know your thoughts! 👇
---------
Follow me to upskill in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
Also hit 🔔to stay notified about new content.
𝗗𝗼𝗻’𝘁 𝗳𝗼𝗿𝗴𝗲𝘁 𝘁𝗼 𝗹𝗶𝗸𝗲 💙, 𝘀𝗵𝗮𝗿𝗲 𝗮𝗻𝗱 𝗰𝗼𝗺𝗺𝗲𝗻𝘁!
Join a growing community of Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: https://t.co/qgNCnGtF4A](https://pbs.twimg.com/media/FzdgVP8XoAEkI09.jpg)