We’re expanding Project Glasswing. We’ve extended access to Claude Mythos Preview to approximately 150 additional organizations, based in more than fifteen countries.
Read more about this expansion and our future plans for Project Glasswing: https://t.co/QrtHSBdRbh
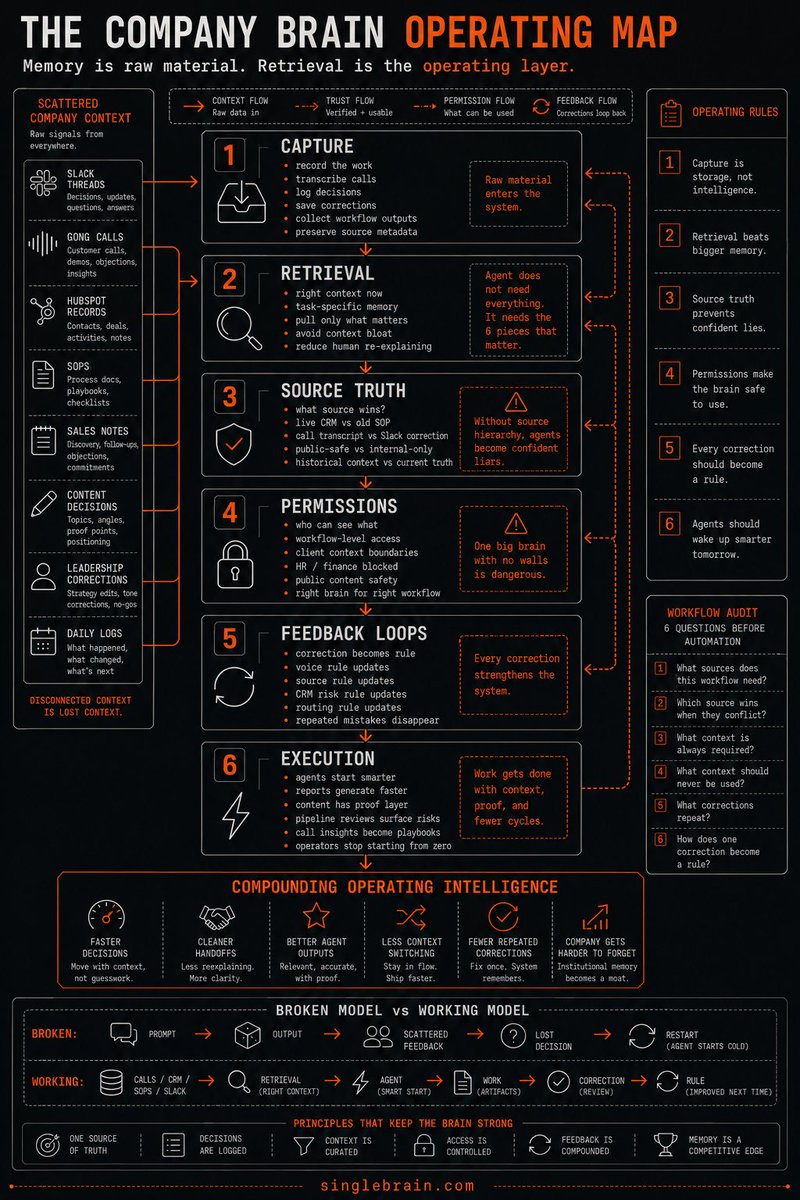
Every company is missing the same layer:
A company brain.
Right now, the memory of the business is scattered across calls, docs, Slack threads, dashboards, SOPs, and people's heads.
That's the part people miss when they talk about a company brain.
The value isn't a giant folder of company knowledge. Every company already has that.
The real advantage is the intelligence layer that sits between all that context and the work your team needs done.
This is the layer every AI-native company will need:
Microsoft just open-sourced SkillOpt!
A framework for training agent skills like neural networks:
SkillOpt treats a plain markdown file as the trainable parameter of a frozen LLM agent, applying the same optimization discipline used in weight training: learning rates, validation gates, batch sizes, and epoch schedules.
The analogy maps precisely. The skill document is the parameter. Trajectory-derived edits are the gradient direction. An edit budget is the learning rate. A held-out split is the validation check.
Here's how it works.
A frozen model runs tasks with the current skill and produces scored trajectories. A separate optimizer model analyzes failures in minibatches, proposes structured add/delete/replace edits, and ranks them under a budget cap.
If the candidate skill improves performance on a held-out split, the edit is accepted. If not, it's rejected and stored so the optimizer avoids repeating failed changes.
The deployed output is a single best_skill. md file, typically 300 to 2,000 tokens. No weight changes, no extra inference-time calls.
The learned rules are compact and readable. These read like rules a thoughtful engineer would write after a day with the benchmark, except they were discovered automatically.
Learn more:
Paper: https://t.co/sdj5DW7t9h
GitHub: https://t.co/W3DcpBCni0
SkillOpt isn't the first system to treat skills as something you can optimize.
Hermes Agent independently built the same idea through a combination of skill_manage, Curator, and an optimization loop called GEPA that scores, mutates, and promotes skill documents across runs.
Two teams, different architectures, same conclusion: the skill file is the highest-leverage thing to optimize in a frozen-model agent.
I wrote a deep dive on how the Hermes agent works and covered all of these topics briefly.
The article is quoted below.
SpaceX is such a bad ass company. In their IPO filing, they wrote this:
• The first private company to develop and launch a liquid-fuel rocket to reach orbit (2008)
• The first private company to successfully dock a private spacecraft with the International Space Station (2012)
• The first to successfully propulsively land (2015) and refly orbital-class rocket boosters (2017)
• The first to begin deploying a large-scale LEO broadband satellite constellation (2019);
• The first private company to transport astronauts to orbit, returning America's ability to fly astronauts to and from the International Space Station (2020)
• The first to manufacture consumer-grade phased-array user terminals at scale (2022);
The first to deploy a large-scale LEO satellite-to-mobile constellation (2025)
• The first to build a gigawatt-scale Al training cluster and largest coherent supercomputer (2026)
• The first gigawatt-scale Megapack battery installation (2026); and
• The only company capable of building orbital AI compute at scale.
BOOM.
Critique of the 𝕏 algorithm is welcome.
There will be monthly updates of the latest algorithm to GitHub with release notes.
As reminder, you can always choose no algorithm via the Following tab.
Jane Street pays $750K/ year for quants who know how to apply probability theory and Markov chains in quant trading.
this 1-hour MIT lecture on "Probability Theory" gives you the same edge quants get paid $60K/month for.
Bookmark it & watch today. Then read the article below.
Here are 10 GitHub repos that quietly print money while you sleep.
1. Cal. com
Open-source Calendly. Fork it, white-label it, sell to dentists and lawyers for $200/month. The founders hit $5M ARR in 3 years doing exactly this.
Repo → https://t.co/haz8ihRsHm
2. Plausible Analytics
Privacy-first Google Analytics. Self-host it, resell to agencies for $50/month per client. Two founders bootstrapped this to 7 figures.
Repo → https://t.co/RFrcpqTBQ7
3. Ghost
Open-source Substack with 100% margin. 1,000 readers at $5/month equals $60,000 a year. Forever.
Repo → https://t.co/Z1MdZ5Zapg
4. n8n
Open-source Zapier. Sell automation services for $500-$2,000 per setup. n8n raised $14M because the agency model behind it works.
Repo → https://t.co/hdycABGGc1
5. Supabase
Free Firebase replacement. Build a SaaS in a weekend, charge $29-$99/month. They raised $116M for a reason.
Repo → https://t.co/dFB2QvafA7
6. Medusa
Open-source Shopify. Take 5% on every sale forever. Zero rev share to Shopify.
Repo → https://t.co/uEuCK6zuZO
7. AppFlowy
Open-source Notion. Sell self-hosted to enterprises worried about data privacy. They raised $30M because this market is massive.
Repo → https://t.co/IDMykTCkMU
8. Coolify
Open-source Vercel and Heroku. Charge developers $20/month to manage their deployments. Replace their $200 Vercel bill.
Repo → https://t.co/N5Fk22qraT
9. Listmonk
Open-source Mailchimp. Send unlimited emails for the cost of an AWS bill. Resell to agencies at 10x markup.
Repo → https://t.co/NS6Uukcklw
10. Penpot
Open-source Figma. Sell self-hosted design tools to agencies who refuse to upload client files to the cloud.
Repo → https://t.co/Lx1CYUP4p4
The difference between developers who build features and developers who build businesses is one decision.
Pick one of these. Fork it this weekend. Ship it next week.
The founders behind these repos already proved the model.
Save this. Share it with the developer in your life who deserves to break free.
100% free. 100% open source.
Elon just updated the entire X algorithm code
I just went through all 24,000 lines of the algo
What I read blew me away
Here’s everything you need to know about how to go viral and if you can still get shadowbanned: 🧵
What actually is GBrain?
(Y Combinator CEO's personal agent brain)
Every agent memory tool you've seen solves a simple problem: store facts, retrieve facts.
GBrain solves a different one. It gives your agent a knowledge system that wires itself, enriches itself, and compounds while you're not even using it.
Here's what makes it fundamentally different from Mem0, Zep, LangMem, or a CLAUDE.md file.
The standard approach to agent memory is vector-based. Your agent stores memories as embeddings, retrieves them by semantic similarity, and that's the loop. Some tools add a knowledge graph on top.
GBrain flips the model entirely. The source of truth is a folder of markdown files. One page per person, one page per company, one page per concept. Every page follows the same two-part structure:
𝗖𝗼𝗺𝗽𝗶𝗹𝗲𝗱 𝘁𝗿𝘂𝘁𝗵 on top: your current best understanding, rewritten as new evidence arrives
𝗧𝗶𝗺𝗲𝗹𝗶𝗻𝗲 on the bottom: an append-only evidence trail that never gets edited
This is not a vector store with a markdown export. The markdown IS the system of record. You can open it in VS Code, edit it by hand, and 𝗴𝗯𝗿𝗮𝗶𝗻 𝘀𝘆𝗻𝗰 picks up the changes.
Now the part that makes this compound.
Every time a page is written, GBrain extracts entity references and creates typed relationship links: 𝘄𝗼𝗿𝗸𝘀_𝗮𝘁, 𝗶𝗻𝘃𝗲𝘀𝘁𝗲𝗱_𝗶𝗻, 𝗳𝗼𝘂𝗻𝗱𝗲𝗱, 𝗮𝘁𝘁𝗲𝗻𝗱𝗲𝗱, 𝗮𝗱𝘃𝗶𝘀𝗲𝘀. All deterministic, all regex-based, zero LLM calls.
The knowledge graph wires itself on every single write, without spending tokens.
So when you ask "who works at Acme AI?" or "what has Bob invested in this quarter?", the agent walks the graph instead of relying on vector similarity (which struggles with relational queries like these).
Search layers ~20 deterministic techniques in concert: intent classification, multi-query expansion, vector search, keyword search, reciprocal rank fusion, cosine re-scoring, compiled-truth boosting, and backlink ranking. Each catches what the others miss.
But the real unlock is the compounding loop.
GBrain has a 𝘀𝗶𝗴𝗻𝗮𝗹 𝗱𝗲𝘁𝗲𝗰𝘁𝗼𝗿 that fires on every message and captures entities in the background. Person mentioned once? They get a stub page. Three mentions across different sources? Web enrichment kicks in. After a meeting? Full pipeline.
The agent runs a 𝗱𝗿𝗲𝗮𝗺 𝗰𝘆𝗰𝗹𝗲 overnight: scans conversations, enriches missing entities, fixes broken citations, consolidates memory. You wake up and the brain is smarter than when you went to bed.
This is fundamentally different from memory systems that only store what you explicitly tell them to store.
Garry Tan (President and CEO of Y Combinator) built this to run his actual AI agents. It ships with 34 skills, runs on embedded PGLite (no server, ready in 2 seconds), and works as an MCP server for Claude Code, Cursor, and Windsurf.
GBrain: https://t.co/11T8Wp95RK