This is a new paradigm for interacting with Claude that is significantly more "inline" with all the other human activity org-wide. Once you do all of the under the hood engineering work to make this "just work" (e.g. across tools, integrations, compute environments, memory, security, etc.), Claude basically joins the team in a seamless way - you can talk to it as you would talk to a person and it can help with a very large variety of workloads.
Imo this is the 3rd major redesign of LLM UIUX. The first paradigm was that the LLM is a website you go to, the second was that it is an app you download to your computer. This third one is that it is a self-contained, persistent, asynchronous entity with org-wide tools and context, working alongside teams of humans. It really takes a while to wrap your head around it, but it works and it is awesome.
Alexandr Wang says he's waiting to have a kid, until tech like Neuralink is ready.
The first 7 years are peak neuroplasticity. Kids born with it will integrate in ways adults never can.
AI is accelerating faster than biology. Humans will need to plug in to avoid obsolescence.
@DGTes citas previas llevan el mayor parte del tiempo sin funcionar. Podríais utilizar un parte de nuestros impuestos para un CI/CD decente? Los servicios básicos requieren un sistema de notificaciones e ingeneros trabajando on-call... En pleno siglo 21... @interiorgob@empleogob
What started at a hackathon is now redefining professional networking.
@cored_in leverages Coreum’s blockchain to verify skills, reward expertise, and connect talent globally.
Hundreds are already on board. Are you in?
Watch the Builder Spotlight here 👇
META JUST KILLED TOKENIZATION !!!
A few hours ago they released "Byte Latent Transformer". A tokenizer free architecture that dynamically encodes Bytes into Patches and achieves better inference efficiency and robustness!
(I was just talking about how we need dynamic tokenization that is learned during training 🥲
It's like fucking christmas!)
I don't want to talk too much about the architecture.
But here's a nice visualization from their paper.
Let's look at benchmarks instead :)
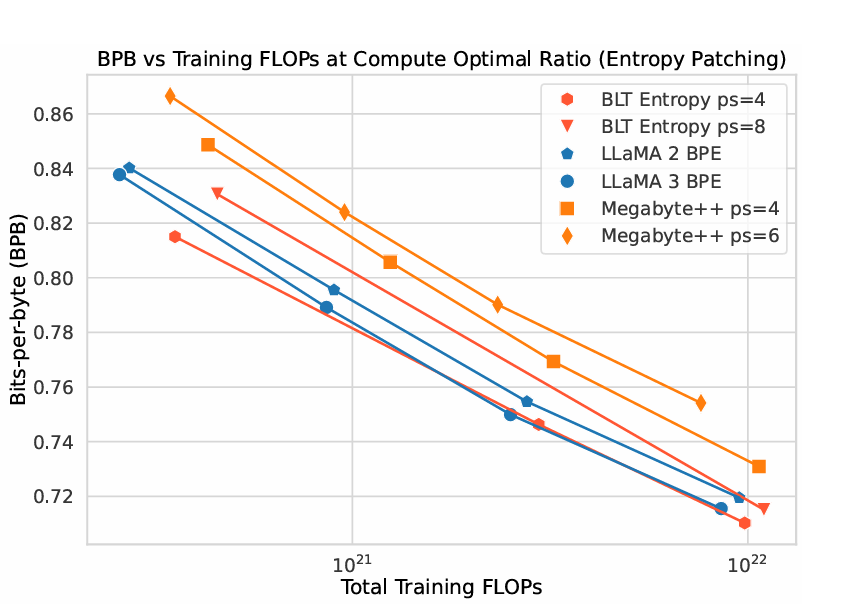
"BLT models can match the performance of tokenization-based models like Llama 3 at scales up to 8B and 4T bytes, and can trade minor losses in evaluation metrics for up to 50% reductions in inference flops!"
This is basically a perplexity vs training flops chart - scaling laws with compute. BPB is a tokenizer independent version of perplexity.
BLT is on par or better than LLama 3 BPE!
Most importantly they scale this approach to train Llama-3 8B model on 1T tokens which beats the standard Llama-3 architecture with BPE tokenizer!
@cored_in SocialFi on @cored_in offers unique ways to earn, build trust, and control your data in a decentralized environment.
Enjoy spam-free, pay-to-message interactions, microblogging with tipping, and staking on professionals.
Learn more: https://t.co/jsrH2w4Neo
The winner of the EdgeCloud track is Thetaform, the world's 1st decentralized Terraform Cloud Provider, allowing you to deploy AI infrastructure on Theta EdgeCloud like a professional, using standard DevOps practices
It’s only been 2 days since OpenAI revealed GPT-4o.
Users are uncovering incredible capabilities that completely change how we use and interact with AI.
The 12 most impressive use cases so far:
#Coreum Wave 3 Spaces with @lzero_analytics & @cored_in!
Join the conversation, meet the teams, and see how projects plan to build & integrate on the #superledger.
⏰ 5/1/24 @ 1 PM EST
Set Reminders: https://t.co/4SGMd7LNfs
#BuildOnCoreum
From SocialFi and Ticketing to Developer and Enterprise Tooling, Wave 3 Grantees are broadening the ways projects and users can leverage the #superledger.
Check them out below and follow for updates as they #BuildOnCoreum.
📰: https://t.co/SU0xZslPd9
💚