We’re excited to announce the first workshop on CogInterp: Interpreting Cognition in Deep Learning Models @ NeurIPS 2025! 📣
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 https://t.co/sKn7LYWtR7
1/
Can LLMs evolve human-like semantic categories?
CDS-affiliated @NogaZaslavsky and PhD student Nathaniel Imel show that, via simulated cultural transmission, LLMs reorganize color categories toward efficient compression.
🔗https://t.co/Dhiy0r1ScL
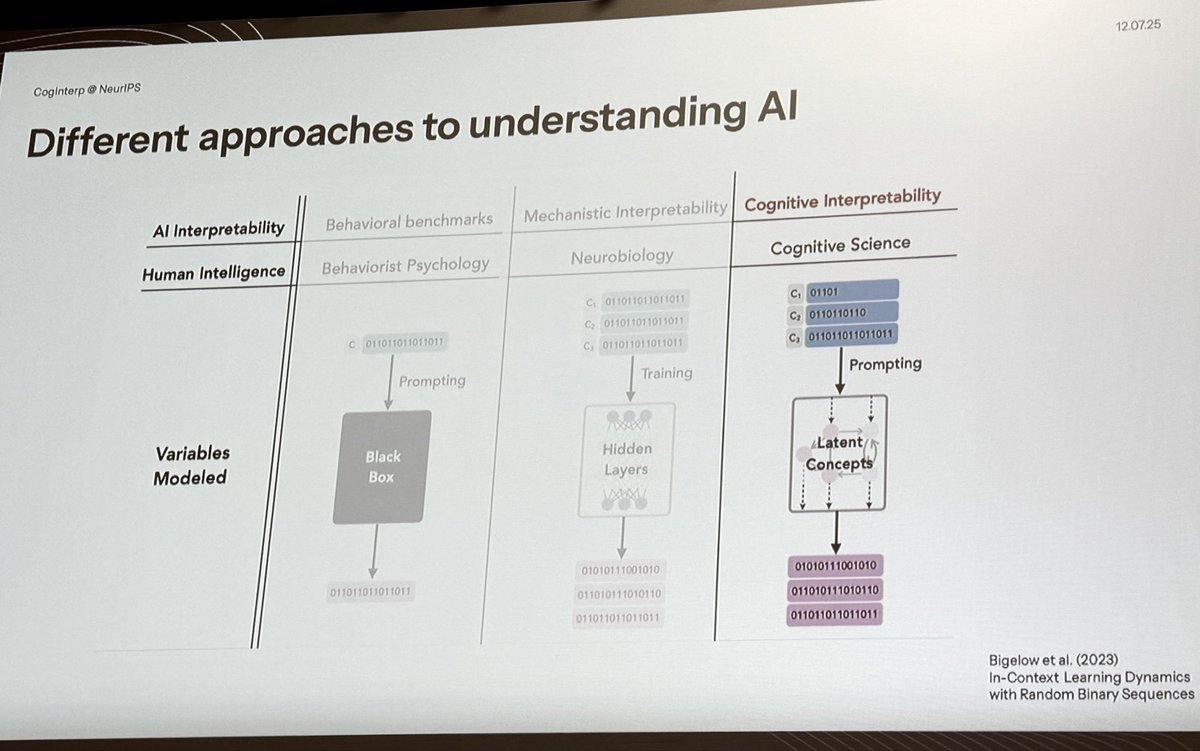
Our last Stanford guest lecture - @EkdeepL on what counts as an explanation & a neuro-inspired "model systems approach" to interp
Plus, how in-context learning and many-shot jailbreaking are explained by LLM representations changing in-context (as a case study for that approach)
00:33 - What counts as an explanation?
04:47 - Levels of analysis & standard interpretability approaches
18:19 - The "model systems" approach to interp
[Case study on in-context learning]
23:36 - How LLM representations change in-context
44:10 - Modeling ICL with rational analysis
1:10:54 - Conclusion & questions
Thanks again to @SuryaGanguli for having us in his class!
Safety-oriented interpretability researchers should be focused on AI systems, not individual model artifacts. A snippet from the NeurIPS CogInterp workshop panel on Sunday:
Honored and thrilled that our work received the @CogInterp best paper award! 💫
📄 Extended paper: https://t.co/TrQcZgrygv
🧵 Highlights: https://t.co/5xRT08StX3
@NeurIPSConf#NeurIPS2025
Our Best Paper Award goes to Nathaniel Imel and Noga Zaslavsky @NogaZaslavsky for their excellent paper “Culturally transmitted color categories in LLMs reflect a learning bias toward efficient compression”!
Our final speaker @sydneymlevine makes a radical proposal: building computational models of human moral judgements to use as an AI system for making moral judgements.
Jay proposes shifting from representing context as a sequence of tokens to a sequence of thoughts. The model learns a latent 'thought gestalt' from previous sentences to guide downstream prediction.
Visualizing how LLMs handle object-property binding, he argues that even with scale, transformers might not be forming the kind of 'integrated representations' that human cognition relies on.
In our fourth spotlight talk, neural network legend Paul Smolensky uses symbolic programs such as production systems to understand how neural networks process symbols
For our third spotlight talk, Sonia Murthy @soniakmurthy uses probabilistic cognitive models to understand value trade-offs in LLMs that enable pragmatic reasoning about politeness in speech acts
Erin Grant @ermgrant discusses dissociations between function and representation, and asks whether representational alignment is enough for understanding deep neural networks
Excited to be presenting our work on using cognitive models to interpret pluralistic values in LLMs once again as a spotlight talk 🌟 at the NeurIPS CogInterp workshop!
Come by upper level room 5AB today and check out the paper here: https://t.co/feDaH3RvKY