Excited to be presenting our work on using cognitive models to interpret pluralistic values in LLMs once again as a spotlight talk 🌟 at the NeurIPS CogInterp workshop!
Come by upper level room 5AB today and check out the paper here: https://t.co/feDaH3RvKY
The spotlight talks will cover all aspects of interpreting cognition in deep learning models: from behavior to algorithms to representations! Also check out the list of poster presentations at https://t.co/P3t6R1A3on
(3/3)
New AI Control Toolkit - Mini Control Arena
For the past few months, we have been doing research with our custom AI Control evaluation library, Mini Control Arena.
Mini Control Arena is a ground-up rewrite of UK AISI Control Arena for a much simpler code structure.
We are open-sourcing the codebase and hope it helps with your experiments, too!
https://t.co/JpetVLvUg4
@sarahcat21 Hi Sarah! I just gave a talk today where I proposed versions of each of these directions, so was really surprised to see this pop up on my feed - I’ll be at NeurIPS and would love to chat!
📝 New paper! Two strategies have emerged for controlling LLM behavior at inference time: in-context learning (ICL; i.e. prompting) and activation steering. We propose that both can be understood as altering model beliefs, formally in the sense of Bayesian belief updating.
1/9
Zach did a stellar job on our new paper looking at what recipes make for language models that are representationally aligned with humans! Read his tweetprint and recruit him for grad school!
@ZachStuddiford@siddsuresh97@kushin_m hi this is cool work! I might be biased because I worked on something that has a very similar spirit https://t.co/feDaH3QXVq, but was excited to see y'all support the motivations and importance we saw around this kind of LLM analysis 😀
Excited to present our new paper as a spotlight talk 🌟 at the Pragmatic Reasoning in LMs workshop at #COLM2025 this Friday! 🍁
Come by room 520B @ 11:30am tomorrow to learn more about how LLMs' pluralistic values evolve over reasoning budgets and alignment 🧵
We also trace the evolution of value trade-offs during alignment by evaluating model checkpoints for 8 unique base model x feedback dataset x alignment algorithm.
We see the largest shifts in values early on in training, with strongest effects of base model choice.
Presenting this today (5/1) at the 4pm poster session (Hall 3) at #NAACL2025!
Come chat about alignment, personalization, and all things cognitive science 🐟
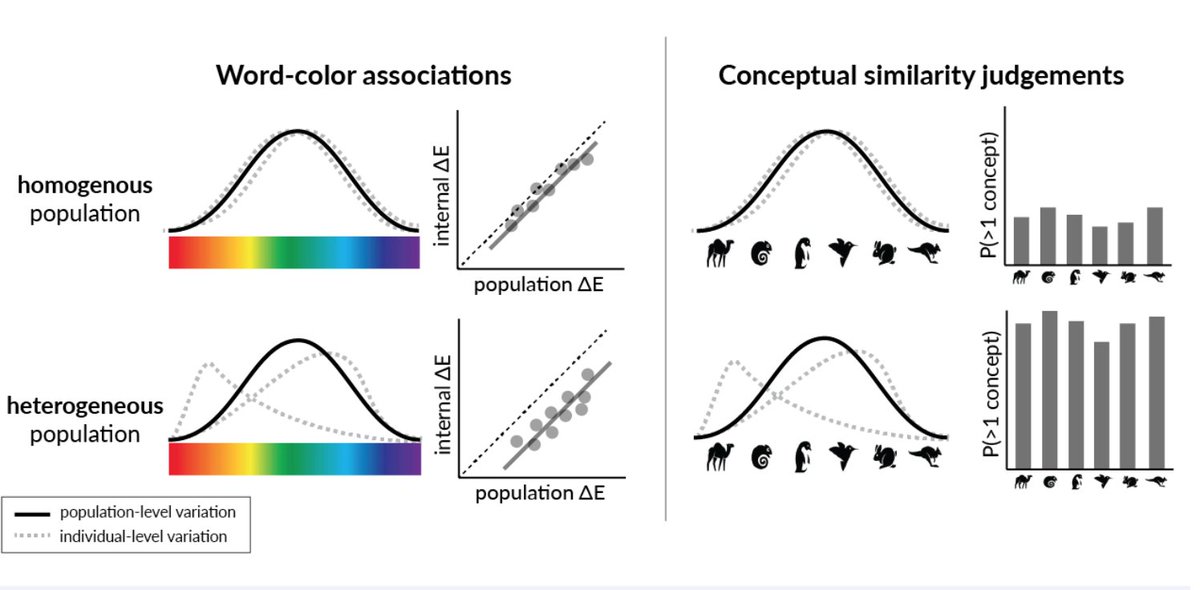
(1/9) Excited to share my recent work on "Alignment reduces LM's conceptual diversity" with @TomerUllman and @jennhu, to appear at #NAACL2025! 🐟
We want models that match our values...but could this hurt their diversity of thought?
Preprint: https://t.co/C4icfhCDGz
(1/9) Excited to share my recent work on "Alignment reduces LM's conceptual diversity" with @TomerUllman and @jennhu, to appear at #NAACL2025! 🐟
We want models that match our values...but could this hurt their diversity of thought?
Preprint: https://t.co/C4icfhCDGz
(9/9) Code and data for our experiments can be found at: https://t.co/CSicsUKs64
Preprint: https://t.co/C4icfhCDGz
Also, check out our feature in the @KempnerInst Deeper Learning Blog! https://t.co/kHScIMxsDn