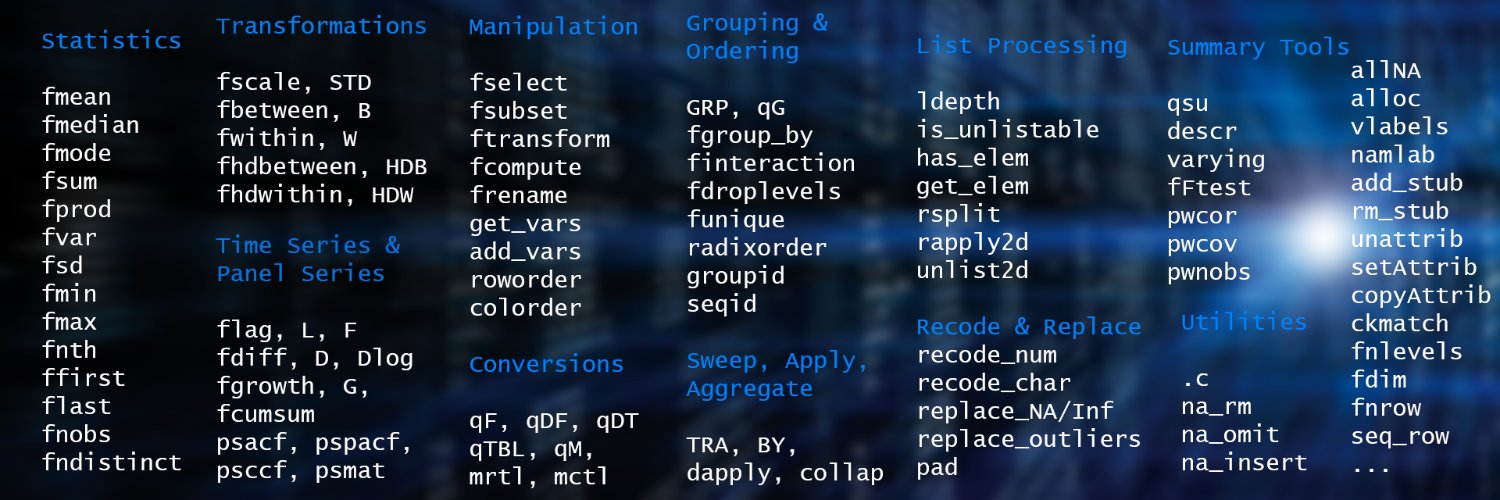
The article on "collapse: Advanced and Fast Statistical Computing and Data Transformation in R" has now been published (open-access) in the Journal of Statistical Software: https://t.co/0jt6PMEO5t
It offers a concise yet thorough introduction to the package. #rstats#DataScience
Recording of my talk on {collapse} and the {fastverse} at the Bank of Portugal‘s workshop on „Speeding up Empirical Research: Tools and Techniques for Fast Computing“ in December is now online: https://t.co/nhDYym94Pz #Rstats#DataScience
Updated windows benchmarks for in-memory database-like operations by Adrian Antico show that {collapse} still leads on lagging and casting benchmarks (not covered in DuckDB benchmarks) and remains overall very competitive: https://t.co/JuSLclANwS #Rstats#DataScience
I've released a new package {flownet} for efficient transport modeling and graph manipulation: https://t.co/0LOeuXDsNT. It builds on 7 {fastverse} libraries, most notably {collapse}, from which it imports 60 functions. Thus, another great learning resource for developers #rstats
I'm excited to share the release and rOpenSci publication of dfms 1.0 (https://t.co/3Evhp1o6kz), a high-performance, {collapse} and {RcppArmadillo}-based, and feature-rich, implementation of Dynamics Factor Models in R. More in the release blog post at: https://t.co/bsBXqhSGvd
A few updates:
(1) new fastverse domain at https://t.co/Wxvg9HcxEf
(2) the collapse (kit) repos moved to https://t.co/eN6eqM7oUT (/kit) and site to https://t.co/Udx09wcVp7 (/kit)
(3) A group of maintainers has been given access
(4) collapse has a DeepWiki https://t.co/wdZim3mafW
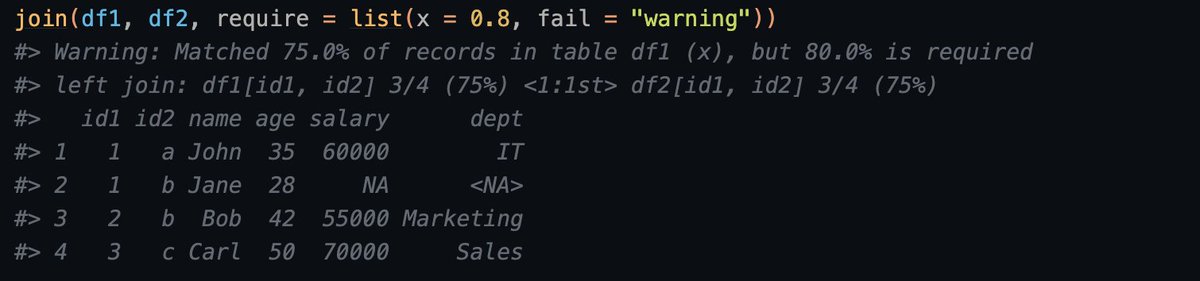
{collapse} 2.1.0 is out! It introduces a new fslice() function (https://t.co/p25YbZujp5), a new theory-consistent weighted quantile algorithm (https://t.co/NAJD2y7zpk) with excellent properties. And some convenience features such as join requirements: #rstats#DataScience
@JosiahParry It’s a never ending hackathlon, unfortunately. But still good to have rigorous C/C++ checks done for free on many platforms. Creates more robust software.
The {collapse} arXiv paper has just been updated - following extensive revision: https://t.co/Ft1vDdCGfQ. I believe it is a great resource for anyone doing scientific computing with #rstats.
There is now a #fastverse benchmark wiki (https://t.co/mwx7SR8rvT) where users can freely contribute benchmarks. If you have benchmarks involving {fastverse} packages ({collapse}, {data.table}, etc., including extensions) please contribute them (takes 1 min) #rstats#DataScience
I just improved the vignette a bit further, adding some detailed benchmarks and a section on Global Options. I needed to correct myself: it is not true that {collapse} global options should never be invoked in packages - they just need to be reversed like #rstats global options.
It's nice to see an increasing number of #rstats packages using {collapse}. A developer focused vignette was long planned and now it is here - with modest advice on writing efficient R package code in general and using {collapse} in particular: https://t.co/5j7EiFk4dk
{collapse} is now also on BlueSky (https://t.co/ODTcOh0GjA) and I am also there (https://t.co/yQnDqHAANa) [and on Mastodon: https://t.co/kKomhUJbOp]. I will repost {collapse} posts but also share about research/data. This X account will remain active. #rstats
@MislavSagovac@r_data_table Of course not. But {collapse} can do many things, particularly complex statistical things, that cannot be done with {data.table} or are more difficult to do or do efficiently with {data.table} - as shown in this post and further in the docs/resources: https://t.co/pAm5Hb7NyC
Check out the latest package to be granted the Seal of Approval: {collapse} by Sebastian Krantz!
{collapse} is a partner package, that implements various data transformation and statistical analysis tasks using ultra fast C/C++ implementations.
https://t.co/fJ0QdElEVX
{collapse} v2.0.15, with fast aggregation pivots, has just reached CRAN. A minor but neat feature worth pointing out in this release is enhanced join verbosity. In addition to the join success rates, the join relationship is now determined and reported - at no extra cost #rstats
@statquant @JosiahParry Agreed, it’s not more apples to apples, but equally valid. DuckDB benchmarks max out all frameworks on a large linux cloud server. This one compares performance on a local windows system through IDE‘s and is thus closer to many users. For the 100M data they are quite similar…
New independent benchmark by Adrian Antico: https://t.co/prVkzllrtD
Setup:
- large local Windows machine
- real data
- broad range of tasks
- scripts executed inside Rstudio and VScode
-> shows that {collapse} is an absolute top performer in this setting #rstats#DataScience
@Yann_the3rd @JosiahParry Thanks, but I doubt that {collapse} is buggy. Many people are using it and most issues I get are feature requests. It simply does not support tidyselect syntax. across() inside fmutate() works fine. Please carefully read the docs and report any issues that you find on GitHub.