📢 Models like #ChatGPT are trained on tons of human feedback. But collecting this costs $$$!
That's why we're releasing the Stanford Human Preferences Dataset (🚢SHP), a collection of 385K *naturally occurring* *collective* human preferences over text.
https://t.co/cRY1F8TjFz
Just started a compilation of generative models for search / information retrieval.
https://t.co/LNiyij82yl
Mostly divided in:
- Grounded Answer Generation (retrieval-augmented, attribution, ...)
- Generative Document Retrieval (DSI, ...)
What is still missing?
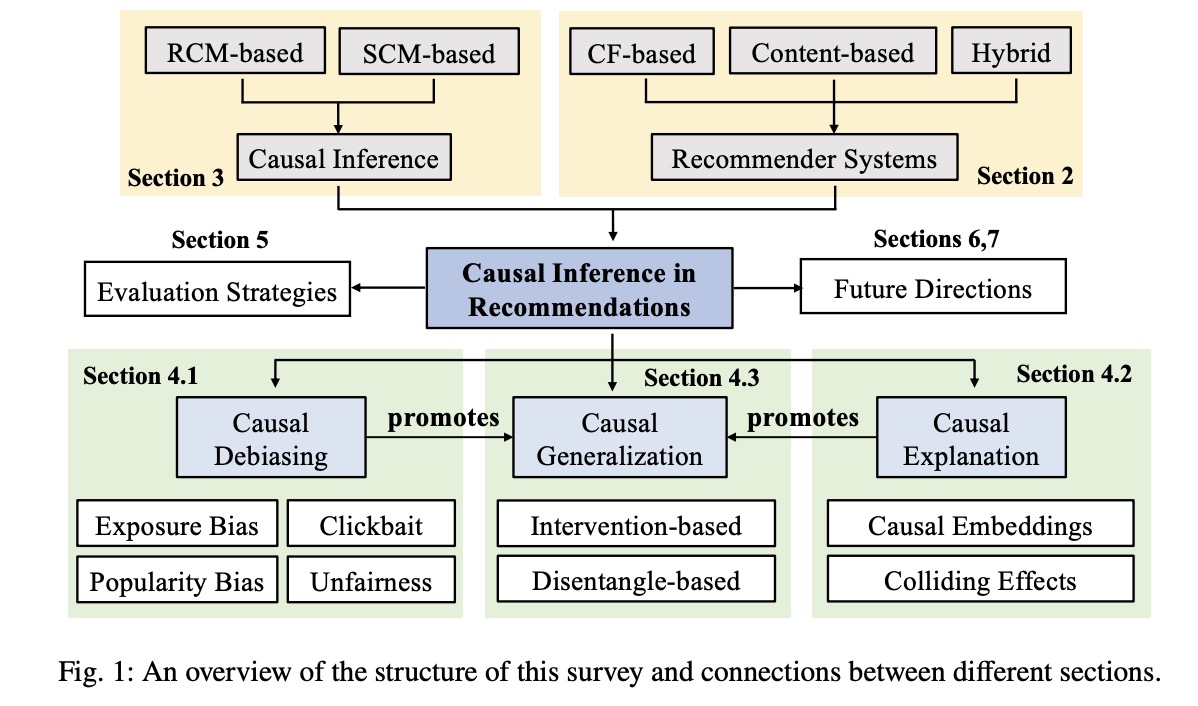
We just released a comprehensive survey paper on causal inference in recommender systems https://t.co/t7aX0OA3RN. It covers widely-used strategies for bias mitigation, explanation, and generalization. Please check it out!
I am thrilled to share that our work paper "Model-based Unbiased Learning to Rank" is accepted as a full paper at #WSDM23 with @lixin26814124@QingyaoAi@colozoy Dawei Yin and @BrianDavison. Updated arxiv version and code come soon.
Thrilled that share our work "StruBERT: Structure-aware BERT for Table Search and Matching" w/Mohamed Trabelsi, @colozoy@BrianDavison, and Jeff Heflin has been accepted at @TheWebConf#WWW2022 as a full paper!
Thread: We are organizing a #SemEval22 shared task #multiconer on Multilingual Complex #NER.
The training data is already available for download. Make sure you check it out and participate to the task. https://t.co/qDco5vOrtW #NLProc 1/3
Check out a case study with Know Your Data — a dataset exploration tool introduced earlier this year at Google I/O — that highlights how biases can be traced to both dataset collection and annotation practices. https://t.co/CZ9sXYG7NN
For those working on MS MARCO v2 for the TREC 2021 Deep Learning Track, we're happy to share an augmented passage corpus that pulls in metadata from the doc corpus: provides a nearly 20 point bump on recall@100 on the dev queries for first-stage retrieval! https://t.co/2lV913VD2G
Empirical studies observed that generalization in RL is hard. Why? In a new paper, we provide a partial answer: generalization in RL induces partial observability, even for fully observed MDPs! This makes standard RL methods suboptimal.
https://t.co/u5HaeJPQ29
A thread:
During #SIGIR2021's Poster Session C this afternoon (12 PM EDT), @LehighCSE's Zhiyu Chen will present "WTR: A Test Collection for Web Table Retrieval," a paper co-written with our #AI Research Scientist @imsure318 and @BrianDavison
https://t.co/Gt1AF5AM1v
Telling which results in RL are worth building on is hard. This blog post discusses three heuristics I use. Curious to learn about what other folks do! https://t.co/fWZ8jtIfxr
Data augmentation has been one of the most common approaches for mitigating the need for labeled data&improving data efficiency. We provide an empirical*survey of data augm for limited data learning in NLP: https://t.co/y4jTDOSgTg
w/ Derek Tam @colinraffel @mohitban47@Diyi_Yang
Our team is still looking summer intern candidates. The candidate is expected to have a solid background in NLP. They will be working on NLP related research projects. You can reach out with your CV (send to anjiefang at gmail com). #AmazonScience#InternAtAmazon
Our resource paper accepted at #SIGIR2021 “WTR: A Test Collection for Web Table Retrieval”, w/@colozoy and @BrianDavison, has extended the table retrieval test collection, WikiTables (w/@krisztianbalog ), with more diverse Web tables and labels on contextual fields.