Optimist, Geek, Building @AgletsAI. Dot Connector, Tool Builder, Info Hacker & Coder. Into Edge & Physical AI, Agents, Small LLMs, and making hard things easier
@rachelnabors PS. I’m going to try and put the new full weight MiniMax M3 model through the wringer (via api) and see how it handles things.
Can it code while 5.5 plans and validates? How much clean up will be required? Only real tests will tell the tale.
I’m skeptical but hopeful.
@rachelnabors Curious where u r finding limits w/ DS4 or others especially the local quants. I keep debating upgrading my M3/64GB to a maxed out unit but I’m still worried it’s too early to hand over real coding tasks especially brownfield to open source models. I want to adopt tho! Thank you
@gregisenberg Serious question. How do they handle:
Cool app like this is released
Creator profits
Untold number of slop copies pop up overnight making visibility an even bigger issue then in App Store
Sales vanish
Users upset because they bought wrong product got slop blame original author
@ClementDelangue Here’s how I framed where we’re D in another tweet
We’re seeing a steady shift toward intelligence ownership
By adopting open models & fine-tuning them, enterprises (& startups) r building core proprietary asset that lower long-term costs while continuously compounding in value
@badlogicgames It’s so weird.
Google’s commercial models always underwhelmed me while at the same time I LOVE the Gemma series w/ 4 being incredible especially for fine tuning
Can’t wait to play w/ this one
Can’t believe @Prince_Canuma has already done his MLX magic! They msn rocks. 🔥🍺✨
Today, we’re excited to introduce Miso One, the most emotive voice model in the world.
Miso One is an 8-billion-parameter text-to-speech model for highly expressive speech generation. It emotes like a human and responds faster than a human, with just 110 milliseconds of latency.
We’ve open-sourced the model weights, with API access coming soon.
Hear how Miso One sounds in the thread below.
@TrelisResearch Nice ongoing work!
It’s sad we have to add a training disclaimer. Not training on benchmark data should be a given but again sadly it’s not
I wonder if there’s something at test time u can apply to boost accuracy where it’s having challenges? I’ve never trained ASR so guessing
Totally random none agents, none startup thought.
Friend accidentally gamified hand washing by installing an automated soap dispenser.
Her daughter emptied the thing on the first day. New usage rules in place.
Her daughter not washing her hands, no longer an issue. 🥳
@helloiamleonie@liquidai@maximelabonne@paulabartabajo_ Wow. 🤩
That’s a huge move..
I love Liquid’s mission and approach and I’ve enjoyed your writing while you were at elastic. Feels like a great match.
Congratulations‼️🍺🥳
@MengTo Agreed. Sadly most courses are shipping slop. I’ve only recommended 2 courses to people who asked me out of every course I looked into. That’s 2 out of a very large number. The space is awful and could use more real instructional content.
@TheTuringPost@ammaar It’s a great one. Reminds me of my philosophy I keep pinned to the whiteboard.
"Miracles aren't magic. They’re just patience multiplied by work."
@evalstate I think I should sign up for multiple accounts. Trying to figure out how to maximize $$$. It’s getting expensive but impressive to see serious results.
@evalstate It’s incredible if it’s going that deep and I love plan as code but I worry the sub-agent implantation is incredibly inefficient. Nothing to go on. It’s a feeling.
A new open beast (198B-11B) of a model with a 256K context and 3 reasoning levels released. Benchmarks are compelling. Need to test real world tasks especially with the quants but if they hold up it’s a strong contender model for Claws, Hermes, etc.
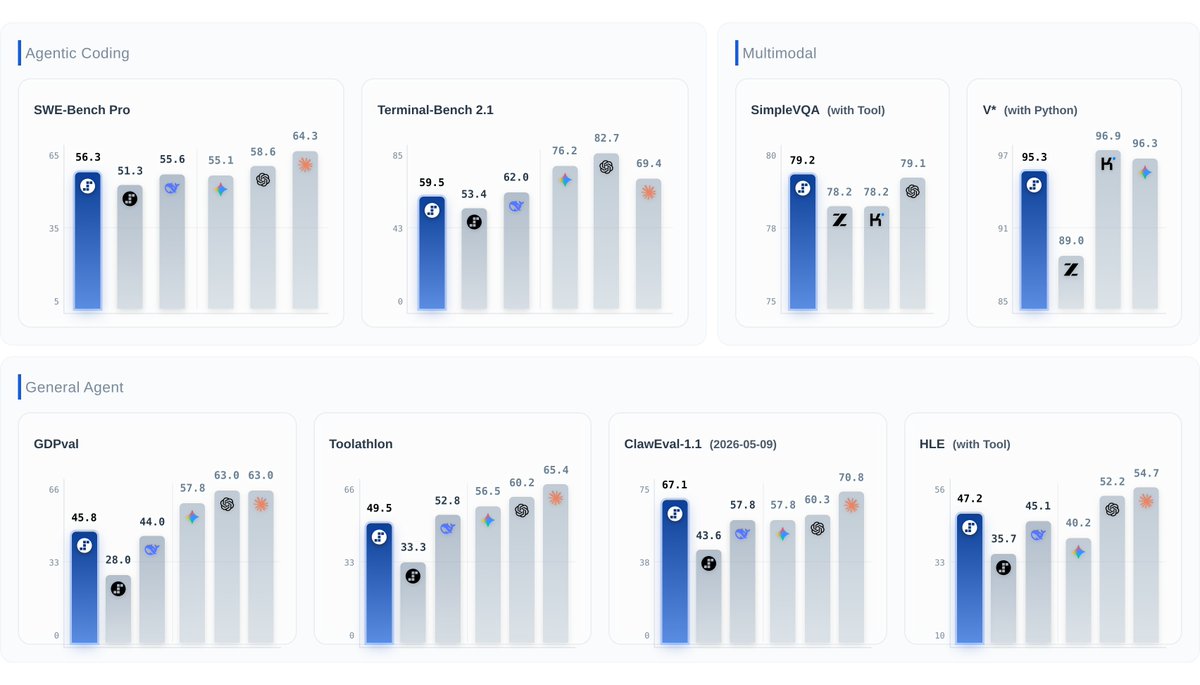
⚡️ Step 3.7 Flash is here: The new frontier is agent efficiency.
#1 ClawEval-1.1 (67.1), #1 SimpleVQA Search (79.2), #2 SWE-PRO (56.3), 95.3 on V* Python. Open weights under Apache 2.0.
Built for agentic, coding, search, and multimodal workflows — balancing speed, cost, and reliable execution.
- 400 TPS. 198B sparse MoE, ~11B active. 256K context, 3 reasoning levels.
- Understands UIs, charts, docs, images — then writes code or calls tools to act on what it sees.
- Web + visual search reaches further: more sources, deeper follow-up.
- Reliable tool use — less drift, fewer broken toolcalls. 98%+ on τ²-bench across all difficulty levels.
- Works with Claude Code, KiloCode, Hermes Agent, OpenClaw, and protocols like MCP.
- Runs locally on Mac Studio M4 Max, DGX Spark, AMD AI Max+ 395.
GitHub: https://t.co/kqlZkVIRHv
HuggingFace: https://t.co/qqceCrgPiw
GGUF: https://t.co/rR6XrnymWG
ModelScope: https://t.co/wney6Tzvqy
API: https://t.co/RvHWzRG7Fu
Blog: https://t.co/BxDiajiQ5G