Before jumping into books like DDIA or Database Internals, it helps to understand the systems layer these designs are built on.
A lot of the design of such data-intensive systems is based on virtual memory: page tables, page faults, mmap, the page cache, swapping, NUMA placement, TLBs, and the tradeoffs between what the OS wants and what the database wants.
My latest article is a ~25,000-word mini-book on virtual memory.
It starts from first principles and goes all the way down to advanced topics like NUMA placement and performance debugging with tools like perf and /proc.
I also wrote it differently: as a dialogue between a user-space process and the kernel.
Most treatments of virtual memory are dry and fact-heavy. I wanted this one to feel more like a story, while still being technically deep.
Link below.
this is a big deal, on the order of Kelsey Hightower’s “Kubernetes The Hard Way” and probably all ai engineers should go thru this once
mostly i advocate “just in time learning”, but this is one scenario you want “just in case”
Paper: The Path of a Packet Through the Linux Kernel
https://t.co/aQQZ649dxa
Computer Networking is one of my favourite topics - I even did my final-year project on MPLS/LDP on a Linux box. That meant a lot of hands-on NIC configuration: setting up interfaces in various modes so packets could be routed correctly over LDP. And tracing how packet buffers are handled to implement zero-copy wherever possible.
This paper is a deep dive into how packets traverse the kernel - the kind I wish I'd had back then. Worth saving for a careful read.
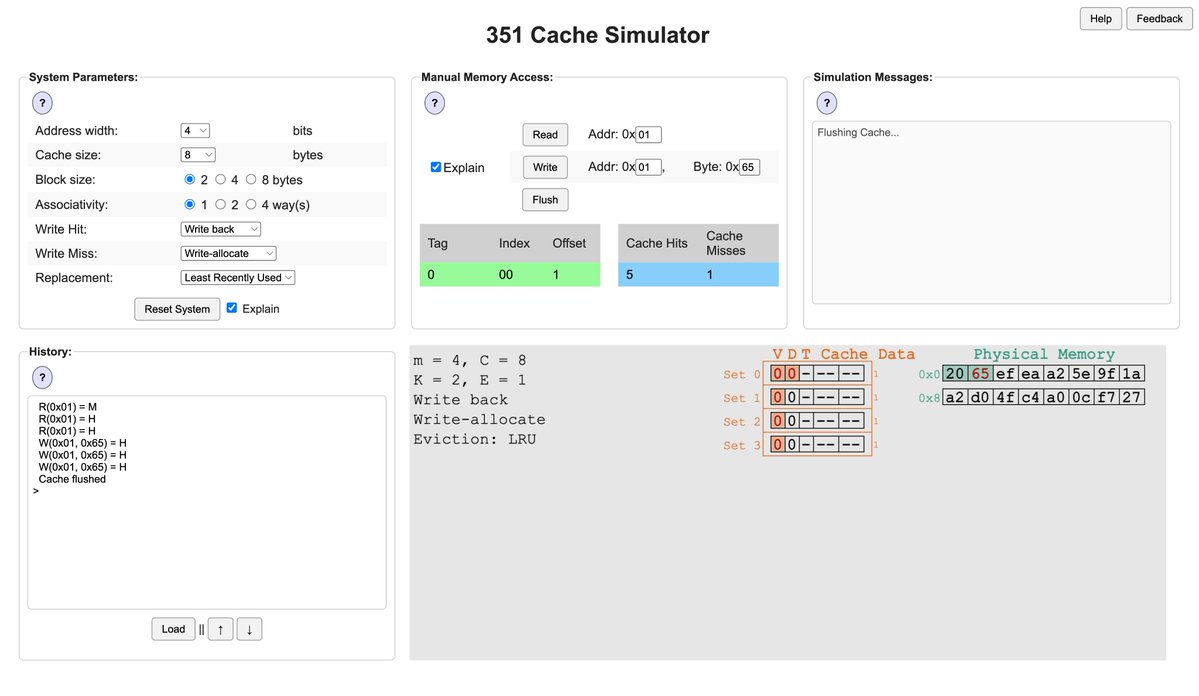
The CSE 351 Cache Simulator is the best hands-on way to understand cache hits, misses, LRU eviction, and write policies.
Tweak the parameters, step through memory accesses, watch it all happen live.
https://t.co/HKBrfyt5Go
almost 11 years ago i watched this talk on my lunch break. it ended up being one of the most influential videos i've ever watched.
been workflow pilled ever since
https://t.co/UATXnKsEWH
I disagree: https://t.co/D17M3HAF1b
Code is how we get precise abstractions into human heads
Saying code isn't important is like saying mathematical notation isn't important
There's a reason we glorify f = ma or e = mc2. Formalism holds immense power for mastering complexity
Expectation: the age of the IDE is over
Reality: we’re going to need a bigger IDE
(imo).
It just looks very different because humans now move upwards and program at a higher level - the basic unit of interest is not one file but one agent. It’s still programming.
If you want to become a database genius among your peers, you need to read this article. It offers invaluable insights that could mark the beginning of your breakthrough in the database field.
During his talk this morning in the #Go devroom at #FOSDEM2026 (10:30 AM CET), software engineer Valentyn Yukhymenko explores how Reflection actually works under the hood in @golang
https://t.co/8ycdZIzI8Z
#golang#GoRuntime#opensource
I'm Boris and I created Claude Code. I wanted to quickly share a few tips for using Claude Code, sourced directly from the Claude Code team. The way the team uses Claude is different than how I use it. Remember: there is no one right way to use Claude Code -- everyones' setup is different. You should experiment to see what works for you!
@PostgreSQL has long powered core @OpenAI products like ChatGPT and the API. Over the past year, our production load grew 10× and keeps rising. Today we run a single primary with nearly 50 read replicas in production, delivering low double-digit millisecond p99 client-side latency and five-nines availability. In our latest OpenAI Engineering blog, we unpack the optimizations we made to to scale @Azure PostgreSQL to millions of queries per second for more than 800M ChatGPT users. Check out the full post here: https://t.co/VTnxhlwlat