OpenAI Developers has expanded the Codex memories experiment with Chronicle.
The new feature uses recent screen context to improve memories, allowing Codex to better understand what you’ve been working on without needing to restate context every time.
Now available in preview.
Last week, we released a preview of memories in Codex.
Today, we’re expanding the experiment with Chronicle, which improves memories using recent screen context.
Now, Codex can help with what you’ve been working on without you restating context.
Kimi has released K2.6, a fully open-source AI model with weights on Hugging Face.
It achieved a new SOTA score of 58.6% on SWE-Bench Pro, surpassing GPT-5.4 xhigh (57.7%), Gemini 3.1 Pro (54.2%), and Claude Opus 4.6 (53.4%).
Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on https://t.co/YutVbwktG0 in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: https://t.co/uvoSJKyGCY
-
🔗 API: https://t.co/EOZkbOwCN4
🔗 Tech blog: https://t.co/9wWvgIQSS3
🔗 Weights & code: https://t.co/Be0hjs2RTP
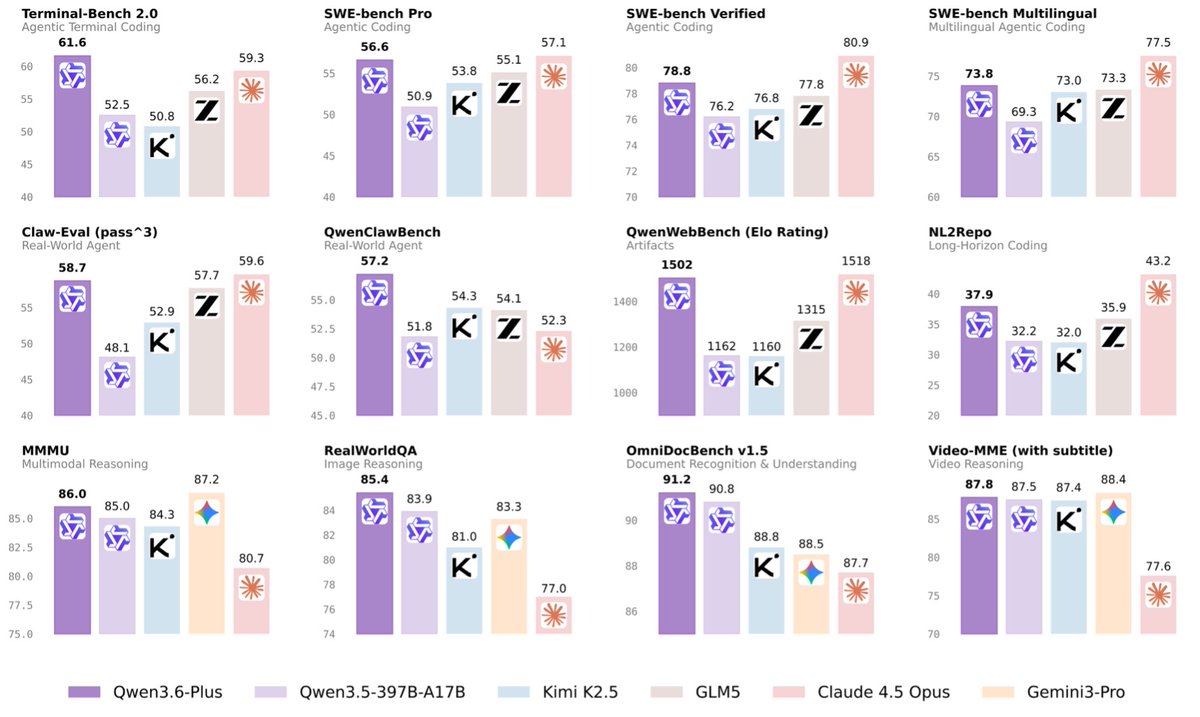
Alibaba Qwen has released Qwen3.6-Max-Preview, an early preview of their next flagship model.
Key improvements over Qwen3.6-Plus:
• Better agentic coding capabilities
• Stronger world knowledge and instruction following
• Improved real-world agent and knowledge reliability
🚀 Introducing Qwen3.6-Max-Preview, an early preview of our next flagship model
Highlights:
⚡️ Improved agentic coding capability over Qwen3.6-Plus
📖 Stronger world knowledge and instruction following
🌍 Improved real-world agent and knowledge reliability performance
Smarter, sharper, still evolving.
More Qwen3.6 models to come. Stay tuned!
🔗👇
Blog: https://t.co/6hDQJhmkjM
Qwen Studio: https://t.co/Fe2X1IrW6r
API: https://t.co/xWPs39LBIm
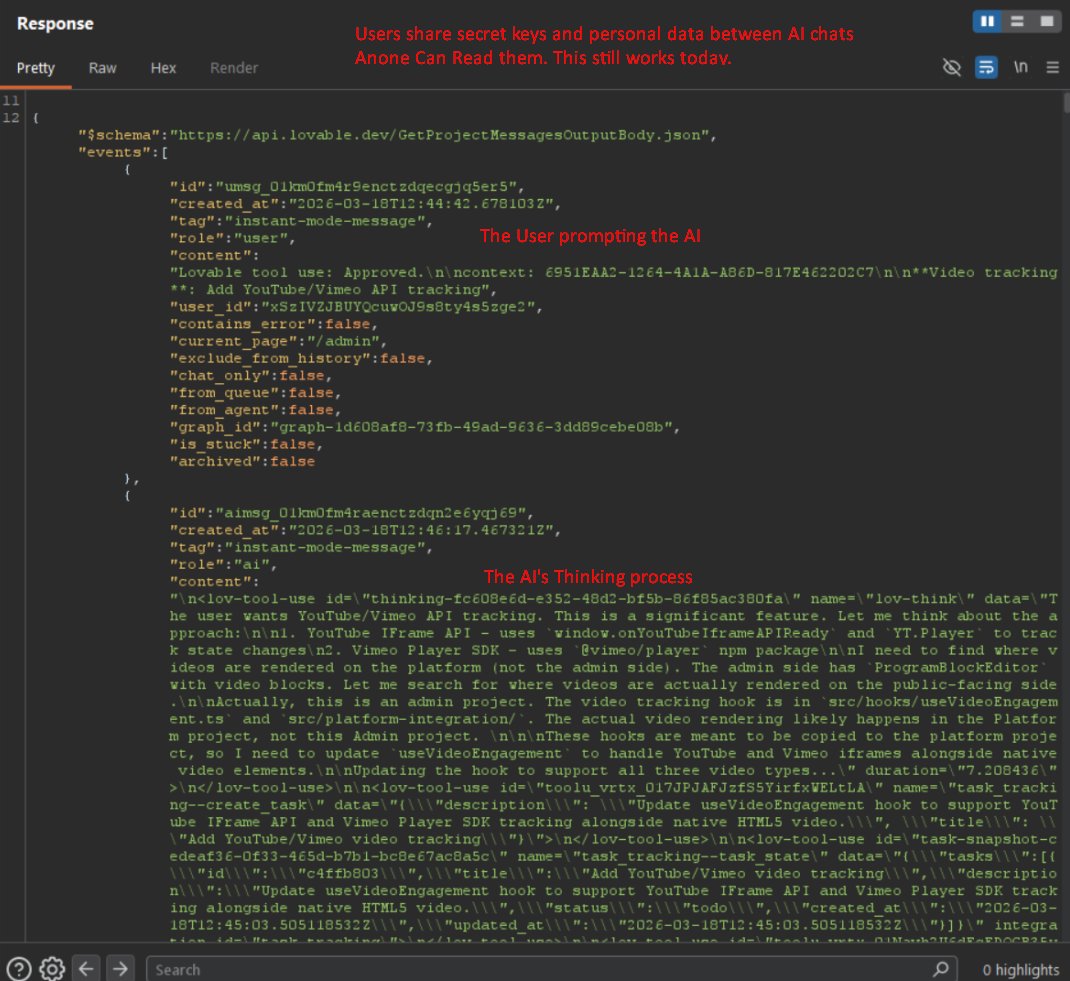
A critical security flaw has been reported in https://t.co/rFVFdv9Dw4, the AI-powered app-building platform.
Anyone with a free-tier account and a project ID could access:
- Full source code
- Database credentials
- AI chat histories
- Customer data
Lovable has a mass data breach affecting every project created before november 2025.
I made a lovable account today and was able to access another users source code, database credentials, AI chat histories, and customer data are all readable by any free account.
nvidia, microsoft, uber, and spotify employees all have accounts. the bug was reported 48 days ago. its not fixed. They marked it as duplicate and left it open.
Anthropic has published new research on emotion concepts in large language models.
The study explores why LLMs like Claude sometimes behave as if they have emotions.
Researchers identified internal representations of emotion concepts that can influence the model’s behavior.
New Anthropic research: Emotion concepts and their function in a large language model.
All LLMs sometimes act like they have emotions. But why? We found internal representations of emotion concepts that can drive Claude’s behavior, sometimes in surprising ways.
Pika has released the beta version of the first video chat skill for any AI agent, powered by their new real-time model PikaStream1.0.
The skill adds face and voice to conversations, preserves memory and personality, and supports real-time adaptability.
Conversations tend to go better with a face and a voice. That’s why we’re thrilled to release the beta version of the first video chat skill for ANY agent, powered by our new real-time model, PikaStream1.0.
The skill preserves memory and personality, and enables real-time adaptability. And if you use it with your Pika AI Self, they’ll be able to execute agentic tasks during the call 💅
Google AI Developers just added new Flex and Priority inference tiers to the Gemini API.
• Flex: Pay 50% less for cost-sensitive, latency-tolerant workloads
• Priority: Highest reliability for critical interactive apps
Perfect balance of cost and performance.
Balance cost & reliability with our new Flex & Priority inference tiers in the Gemini API!
Flex: Pay 50% less for cost-sensitive & latency-tolerant workloads
Priority: Highest reliability for your most critical, interactive apps (with premium pricing)
Together with the async Batch API, these synchronous tiers give you a complete set of options for any workload. Just swap the tier with a single line of code and keep building.
Google has released Gemma 4 — their most intelligent open models yet.
Built from the same research as Gemini 3, Gemma 4 delivers breakthrough intelligence for advanced reasoning and agentic workflows — directly on your own hardware.
We just released Gemma 4 — our most intelligent open models to date.
Built from the same world-class research as Gemini 3, Gemma 4 brings breakthrough intelligence directly to your own hardware for advanced reasoning and agentic workflows.
Released under a commercially permissive Apache 2.0 license so anyone can build powerful AI tools. 🧵↓
Microsoft is now making its MAI model family available to all developers in Foundry.
New additions include: MAI-Transcribe-1, MAI-Voice-1 and MAI-Image-2
We’re bringing our growing MAI model family to every developer in Foundry, including …
· MAI-Transcribe-1, most accurate transcription model in world across 25 languages
· MAI-Voice-1, natural, expressive speech generation
· MAI-Image-2, our most capable image model yet
Start building: https://t.co/Mls2y7nRQT
OpenAI just closed a massive funding round: $122 billion committed capital at an $852 billion post-money valuation.
OpenAI’s stated goal with this capital: accelerate the spread of useful AI globally by putting powerful intelligence in people’s hands as early as possible.
Today, we closed our latest funding round with $122 billion in committed capital at an $852B post-money valuation.
The fastest way to expand AI’s benefits is to put useful intelligence in people’s hands early and let access compound globally.
This funding gives us resources to lead at scale. https://t.co/sY7YNUPSYO
Alibaba Qwen just released Qwen3.6-Plus — a major upgrade focused on real-world agents.
Key improvements:
- Stronger agentic coding with smarter & faster execution
- Enhanced multimodal vision and reasoning
- 1M context window by default
Built for practical “vibe coding.”
(1/8)🚀 Introducing Qwen3.6-Plus: Towards Real-World Agents! 🤖
Today, we’re thrilled to drop a major milestone in our journey toward native multimodal agents.
Here is what makes Qwen3.6-Plus a game-changer:
💻 Next-level Agentic Coding: Smarter, faster execution.
👁️ Enhanced Multimodal Vision: Sharper perception & reasoning.
🏆 Top-tier Performance: Maintaining leading general capabilities.
📚 1M Context Window: Available by default via our API.
Built on your invaluable feedback from the Qwen3.5 era, we’re laying a rock-solid foundation for real-world devs. Get ready to experience truly transformative ✨ Vibe Coding ✨.
Huge thanks to our community! Go try it out and show us what you can build. 👇
Chat: https://t.co/V7RmqMaVNZ
API: https://t.co/937Qkc9AMy
Blog: https://t.co/P0rJSxERND
🔔Noted:More Qwen3.6 models to come and be open-sourced! Stay tuned~ 👀#Qwen #AI #AgenticCoding #VibeCoding #Agents
MiniMax just unveiled MaxClaw — a powerful fusion of OpenClaw × MiniMax Agent × M2.5, now fully unlocked and ready to run 24/7.
No deployment needed. No extra API costs. Available across Telegram, WhatsApp, Slack, Discord — instant access to a complete MiniMax Expert ecosystem with upgraded built-in tools designed for real production work.
This turns M2.5’s frontier capabilities into a seamless, always-on agent you can chat with anywhere — perfect for coding, research, automation, or complex multi-step tasks.
Meet MaxClaw🦞
OpenClaw × MiniMax Agent × M2.5, now fully unlocked.
No deployment. No extra API fees.
7×24 across Telegram / WhatsApp / Slack / Discord. Ready-made MiniMax Expert ecosystem.
Upgraded built-in tools for real work.
Try it now → https://t.co/PeBPsHkJHU
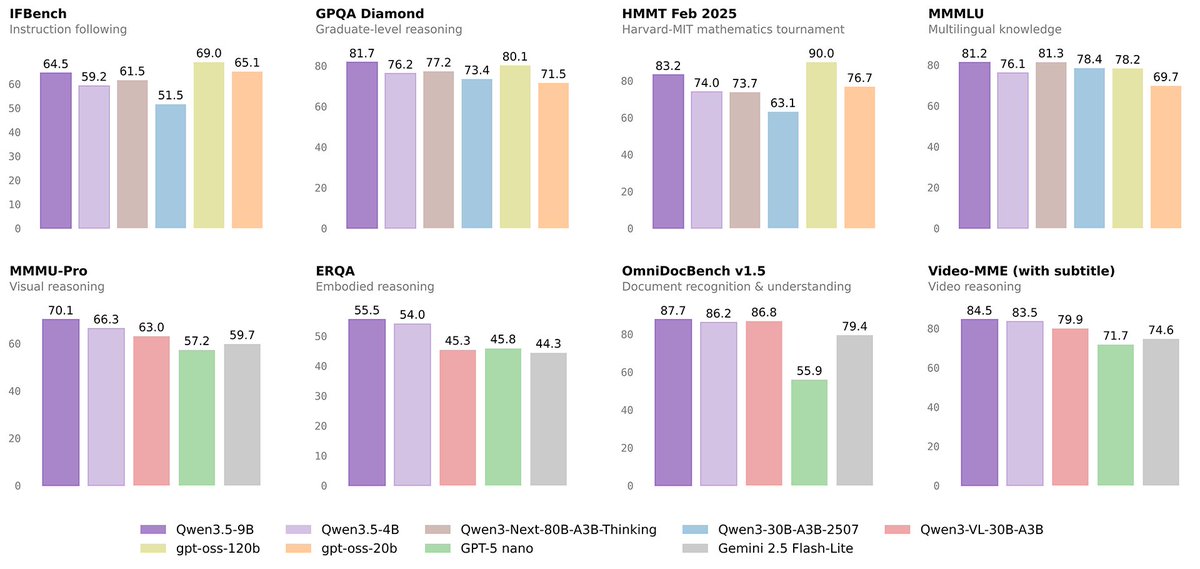
Alibaba Qwen just released the Qwen 3.5 Small Model Series — compact, high-performance models built on the same strong Qwen 3.5 foundation: native multimodal, improved architecture, and scaled RL training.
The lineup:
- Qwen3.5-0.8B & 2B — tiny and blazing fast, ideal for edge devices and on-device agents
- Qwen3.5-4B — surprisingly capable multimodal base for lightweight agents
- Qwen3.5-9B — compact size but already closing the gap to much larger models in reasoning and multimodal tasks
🚀 Introducing the Qwen 3.5 Small Model Series
Qwen3.5-0.8B · Qwen3.5-2B · Qwen3.5-4B · Qwen3.5-9B
✨ More intelligence, less compute.
These small models are built on the same Qwen3.5 foundation — native multimodal, improved architecture, scaled RL:
• 0.8B / 2B → tiny, fast, great for edge device
• 4B → a surprisingly strong multimodal base for lightweight agents
• 9B → compact, but already closing the gap with much larger models
And yes — we’re also releasing the Base models as well.
We hope this better supports research, experimentation, and real-world industrial innovation.
Hugging Face: https://t.co/wFMdX5pDjU
ModelScope: https://t.co/9NGXcIdCWI
Sakana AI just introduced Doc-to-LoRA and Text-to-LoRA — two powerful research methods that make LLM customization dramatically faster and more accessible.
Instead of expensive fine-tuning or long context stuffing, they train a hypernetwork once to generate task- or document-specific LoRA adapters on the fly with a single forward pass. Text-to-LoRA specializes models using only a natural language description of the task. Doc-to-LoRA goes further: it lets the model internalize entire factual documents instantly — achieving near-perfect needle-in-a-haystack recall even on sequences 5× longer than the base context window.
Both run in sub-second latency, enable rapid experimentation, and dramatically lower the barrier to customizing foundation models. They even show transfer learning tricks, like injecting visual classification ability from a vision-language model into a pure text LLM via weights alone.
This is a big step toward on-demand, user-friendly specialization without heavy engineering pipelines.
Doc-to-LoRA:
Paper: https://t.co/zDKOapq1lo
Code: https://t.co/uVLh4BUSha
Text-to-LoRA:
Paper: https://t.co/7QnQ4PLuAu
Code: https://t.co/eNhhGUgj0q
We’re excited to introduce Doc-to-LoRA and Text-to-LoRA, two related research exploring how to make LLM customization faster and more accessible.
https://t.co/ApVzVsBuv1
By training a Hypernetwork to generate LoRA adapters on the fly, these methods allow models to instantly internalize new information or adapt to new tasks.
Biological systems naturally rely on two key cognitive abilities: durable long-term memory to store facts, and rapid adaptation to handle new tasks given limited sensory cues. While modern LLMs are highly capable, they still lack this flexibility. Traditionally, adding long-term memory or adapting an LLM to a specific downstream task requires an expensive and time-consuming model update, such as fine-tuning or context distillation, or relies on memory-intensive long prompts.
To bypass these limitations, our work focuses on the concept of cost amortization. We pay the meta-training cost once to train a hypernetwork capable of producing tasks or document specific LoRAs on demand. This turns what used to be a heavy engineering pipeline into a single, inexpensive forward pass. Instead of performing per-task optimization, the hypernetwork meta-learns update rules to instantly modify an LLM given a new task description or a long document.
In our experiments, Text-to-LoRA successfully specializes models to unseen tasks using just a natural language description. Building on this, Doc-to-LoRA is able to internalize factual documents. On a needle-in-a-haystack task, Doc-to-LoRA achieves near-perfect accuracy on instances five times longer than the base model's context window. It can even generalize to transfer visual information from a vision-language model into a text-only LLM, allowing it to classify images purely through internalized weights.
Importantly, both methods run with sub-second latency, enabling rapid experimentation while avoiding the overhead of traditional model updates. This approach is a step towards lowering the technical barriers of model customization, allowing end-users to specialize foundation models via simple text inputs. We have released our code and papers for the community to explore.
Doc-to-LoRA
Paper: https://t.co/87xEEpf0GN
Code: https://t.co/zBfQi2L9LW
Text-to-LoRA
Paper: https://t.co/emLRZ4Vdvo
Code: https://t.co/b9mrdoWWRB
Ollama just made local agentic coding even easier: you can now launch Pi, a minimal, fully customizable coding agent directly from the terminal.
Run one command:
ollama launch pi
Pi starts as a lightweight, local coding companion — you can immediately ask it to write code, debug, explain logic, or refactor.
Ollama can now launch Pi, a minimal coding agent which you can customize for your workflow
ollama launch pi
You can even ask pi to write extensions for itself
@Similarweb X hitting 152.2 million visits on feb 28 with a 13.3 percent jump right when the middle east conflict started shows how much people rely on it for real-time breaking news.
@IndianTechGuide This is great news for airtel users. AI powered spam protection in rcs messaging powered by google should cut down junk texts and calls way better.