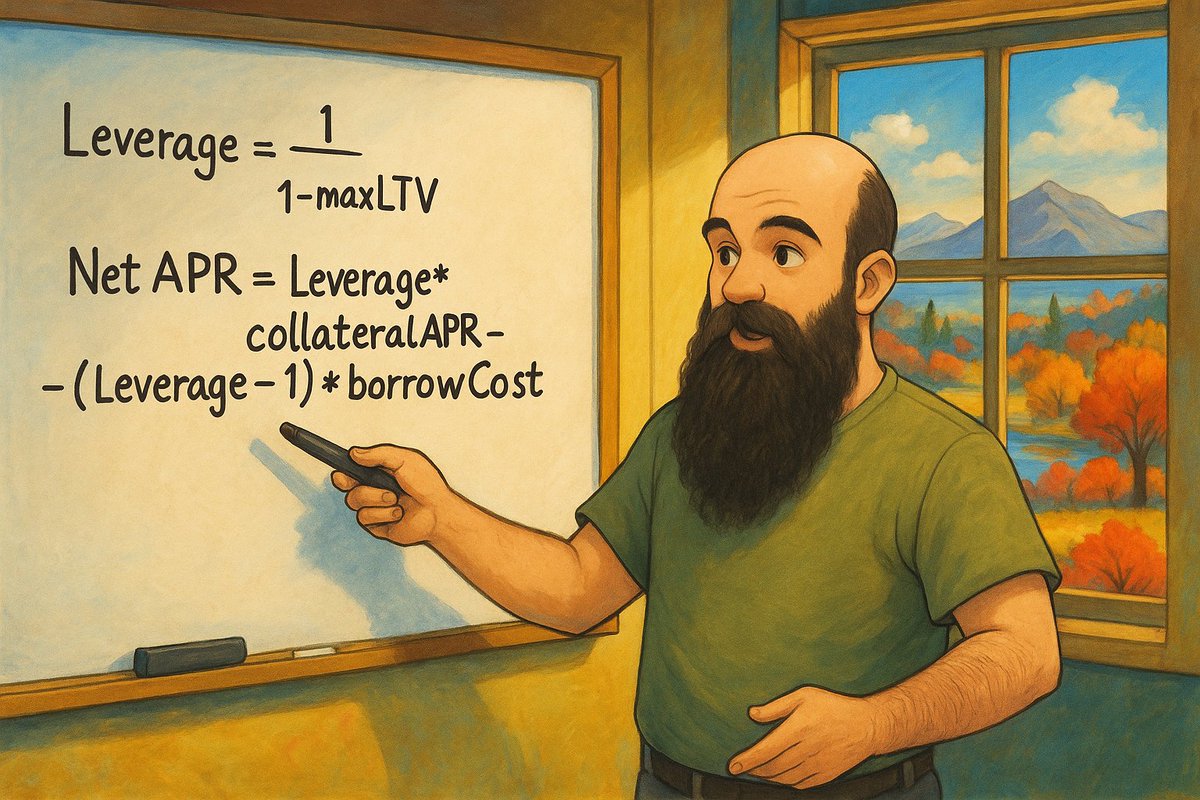Andrej Karpathy built a wiki to think with AI.
I built something that thinks back.
Claude Code + Obsidian equals an AI that actually knows you.
Your goals. Your context. Your history.
Not a chatbot you explain yourself to every session.
A second brain that remembers everything permanently.
Build it once. It compounds forever.
Bookmark it for later and start this weekend.
ANDREJ KARPATHY SPENT 4 MINUTES IN AN INTERVIEW AND ACCIDENTALLY EXPOSED HOW ALMOST NOBODY IS ACTUALLY USING CLAUDE.
Not using it wrong.
Not using it inefficiently.
Not using it at all.
His exact point: paying $20 a month for a subscription is not using Claude.
Typing questions into a chat window is not using Claude.
The real skill is building with Claude.
And most people have never even started learning how to do that.
He identified 4 behaviors that break Claude Code in almost every developer's setup.
A developer took those 4 behaviors, expanded them into 21 configuration rules, and published them in one file.
82,000 GitHub stars.
Number 1 on GitHub Trending.
Coding accuracy jumped from 65% to 94%.
Here are the 21 rules and why most developers have never configured them.
Most Claude Code sessions fail not because Claude is incapable but because it operates without constraints.
No rules about when to stop and ask versus when to proceed.
No rules about how to handle uncertainty.
No rules about file modification scope.
No rules about when to run tests.
No rules about how to communicate blockers.
Without these rules Claude makes reasonable assumptions.
Reasonable assumptions compound into unreasonable outcomes across a 200-turn session.
The 21 rules eliminate the assumption layer entirely.
Claude no longer guesses what you want when you have not specified.
It follows rules you wrote once and never has to write again.
The jump from 65% to 94% accuracy is not a model improvement.
It is what happens when you stop asking Claude to guess and start telling it exactly how to operate.
Karpathy understood this in 4 minutes.
The file took one afternoon to configure.
82,000 developers have already starred it.
Most of the people paying $20 a month still have not.
Bookmark this.
Follow @cyrilXBT for the exact configuration file that takes Claude Code from 65% to 94% accuracy.
Andrew Ng just taught the entire mathematical foundation of machine learning in one lecture.
Free. Stanford University CS229.
4 concepts most developers spend YEARS piecing together:
Locally weighted regression — fit any curve, not just lines.
Maximum likelihood — why squared error actually makes sense statistically.
Logistic regression — the real math behind every binary classifier you have ever used.
Newton's Method — reaches the optimum in quadratic time while gradient descent is still warming up.
This is the lecture that separates engineers who understand the tools from engineers who just use them.
Save it. Watch it tonight.
ANTHROPIC JUST PROVED MOST PEOPLE HAVE NO IDEA HOW TO PROMPT CLAUDE.
Their applied AI team dropped a 24 minute free workshop.
Not a creator who reverse engineered it.
Not a Reddit thread.
ANTHROPIC.
The people who wrote the weights.
And what they showed is uncomfortable.
There are 6 elements to a properly structured Claude prompt.
Most people are using 1.
Maybe 2.
That is not a skill issue.
That is an information issue.
And it has been quietly costing you every single day.
The outputs that felt slightly off.
The responses you had to rewrite 4 times.
The prompts that worked once and never again.
All of it traces back to the same 6 missing elements.
The people who watch this 24 minute workshop tonight will understand something about Claude that most daily users still do not know exists.
The people who skip it will keep getting 30% of what the tool is actually capable of and wonder why the results never quite land.
I watched it twice.
Then I built a Claude Skill that applies all 6 elements to every prompt automatically.
No more thinking about structure.
No more guessing what Claude needs.
The framework runs in the background every single time.
Full breakdown and skill setup is below.
Bookmark this now.
Watch the workshop first.
Then read the guide.
This is the one that compounds.
Follow @cyrilXBT for the exact prompt architecture, Claude skills, and systems I use to get outputs most people do not believe came from one person working alone.
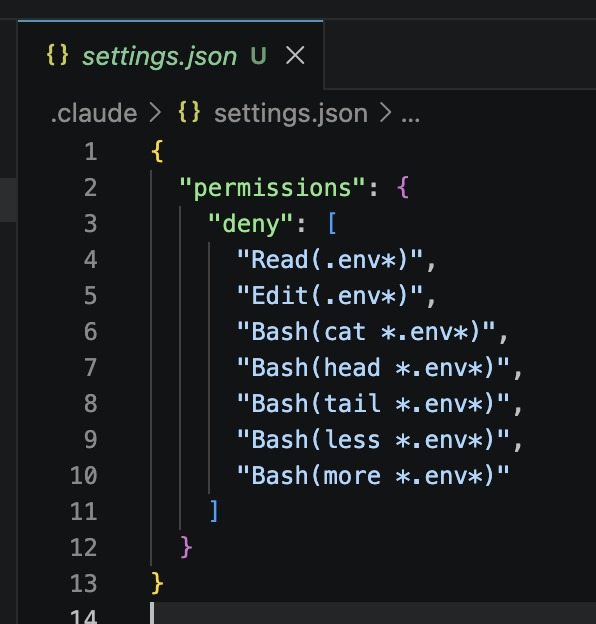
CLAUDE CODE CAN READ YOUR .ENV FILES BY DEFAULT.
Your API keys. Your database passwords. Your secret tokens.
All of it visible to the agent unless you tell it otherwise.
One setting. Two minutes. Fixes it completely.
Add this to your CLAUDE.md right now:
Secure your stack before you ship it.
Stop watching 45-minute Claude tutorials.
Everything you need is in this one image (save this):
1. Cowork Setup (Tips 1–10)
☑ Download the desktop app. Not the browser.
☑ Create one folder on your PC called 'COWORK'.
☑ 4 subfolders: About me, project, template, output
☑ Download anti-ai-style here: https://t.co/psB7XxB2Y4.
☑ Subscribe for free. Open my welcome email.
☑ Hit the automatic reply button inside.
☑ Download anti-ai & my about me from my Notion.
2. Pick the Right Model (Tips 11–20)
☑ Opus 4.6 + Extended Thinking for complex tasks.
☑ Sonnet = quick edits. Haiku = scanning files.
☑ The model matters less than the prompt.
☑ Bad prompt on Opus > Great prompt on Haiku.
3. Prompting (Tips 21–30)
☑ Stop writing long prompts. Files > prompts.
☑ One task per prompt. One. Not five.
☑ Say "Does NOT sound like" to kill the AI voice.
☑ Give the task, not the method. Let it figure it out.
4. AskUserQuestion Tool (Tips 31–40)
☑ "Start with AskUserQuestion" in all 1st prompts.
☑ Claude builds you a clickable form. Click answers.
☑ It asks the right questions so you don't have to.
☑ If the direction is wrong, say it. It rebuilds.
5. Connectors (Tips 41–50)
☑ Settings → Connectors → Browse → Click "Add."
☑ Slack, Google Drive, Notion, Gmail. 50+ tools.
☑ Claude reads your actual files. No copy-pasting.
☑ Free on all plans. No extra cost. Just connect.
6. Plugins (Tips 51–60)
☑ Cowork → Customize → Browse → Install.
☑ Marketing, Legal, Sales, Data — pick your role.
☑ Type / to trigger any plugin command instantly.
☑ Customize to match your company and voice.
7. Claude in Excel (Tips 61–70)
☑ Install "Claude by Anthropic" from Microsoft Marketplace.
☑ It reads every tab. Explains formulas in English.
☑ Drop a PDF in. Claude extracts the tables for you.
☑ No macros. Claude highlights what it touches.
8. Projects & Teams (Tips 71–80)
☑ One Project per deliverable. Not per client.
☑ Upload a great example. It matches the standard.
☑ Convert one person first. Then scale to the team.
☑ Use the 15-minute demo. Show, don't tell.
9. Artifacts (Tips 81–90)
☑ Charts, dashboards, trackers - inside the chat.
☑ They work automatically in Cowork.
☑ Preview before you export. Edit it live. Then copy.
☑ Share with non-Claude users as HTML.
10. Advanced Mastery (Tips 91–100)
☑ Keep your files under 200 lines. Shorter is better.
☑ 80% of your file should be what you're NOT.
☑ Review outputs. Especially financial work.
☑ Claude does 80% busywork. You do the 20%.
---
To download all of my other Claude infographics:
Step 1. Go to https://t.co/psB7XxB2Y4.
Step 2. Subscribe for free. Don't pay anything.
Step 3. Open my welcome email (most skip this).
Step 4. Hit the automatic reply button inside.
Step 5. Download my infographics from my Notion.
Bonus. Enjoy my best copy-paste prompts, too.
♻️ Repost this to save someone 6 months of trial.
I post this math periodically, but borrow rates are super low on @aave at the moment, and I haven't mentioned an $ETH yield in forever.
SO, here's the math on the best long-term ETH yield of the past few years:
TL;DR: 16% APR on weETH with near infinite sizing
The strategy is fairly simple:
➢ Max leverage @ether_fi's weETH on Aave
Why weETH? Because it gets 3% APY instead of just the 2.5% base staking APR.
The maxLTV for weETH in E-Mode is 93%.
93% means we can get over 14x leverage on weETH.
The math for that is fairly simple.
➢ Max Leverage
= 1 / (1-maxLTV)
14.28 = 1 / (1 - 0.93)
Then, to get the strategy's net APR you use another easy formula:
➢ Net APR
= collateralAPR*leverage - (leverage - 1)*borrowCost
So, in this case,
3%*14.28 - 2*13.25 = 16.34%
Super simple. And this uses fundamental oracles, so the only risk of liquidation would be borrow costs turning against you.
The other risk is mass staking withdrawals, where it becomes hard to exit during high-interest rate periods.
This strategy is typically best if done long-term and not for less than a month.
Pair it with ETH shorting on your favorite perp dex to farm points and get a >10% delta neutral yield.
ZK, Privacy, AND FHEs
These three cryptographic ideas often get lumped together as if they are one thing. It is interesting that many people still treat ZK and privacy as the same, partly because in many systems, they work together and reinforce each other. FHE starts from a similar goal, but uses a different path.
In practice, they each answer a different question:
→ ZK asks: “How do I convince everyone this was done correctly without showing them everything?”
→ Privacy asks: “Who is allowed to learn what, and at what point in the system?”
→ FHE asks: “How do I let an untrusted computer work on my data without ever seeing it?”
The market grouped them under “privacy tech”, and I want to separate them in order of understanding and development. Read along 👇
--------
📌First: ZK As A Proof Engine Before A Privacy Feature
From first principles, zero-knowledge proofs (ZKPs) are about proof. You should understand this if you read my piece on the history of ZK.
They exist because verifying a computation directly is expensive. Instead of everyone replaying the same work, a proof system replaces “re-run the whole computation” with “check this small object instead.” It gives you completeness, soundness, and zero knowledge.
That is the core behaviour of ZK. You will see this in:
→ Rollups proving a batch of transactions in one proof.
→ Coprocessors like Brevis or Axiom proving a query on old state.
→ Bridge or crosschain systems that use Succinct style provers with Cysic hardware to ensure some state on chain A is valid before acting on chain B.
They all use the same pattern. One side runs the full logic, the rest of the system only sees inputs, outputs, and a proof that connects them.
---------
📌 Second: Privacy As A system
Like I said earlier, if ZK cares about “how do I prove this,” privacy cares about “who gets to learn what, and when.” This is a layout problem, and ZK is one tool in it. However, privacy itself is a system design that cuts across four surfaces:
→ Identity Surface: Which keys or accounts are visible, and how easily an observer can link them back to the same person.
→ Data Surface: Which balances, positions, orders, and messages are exposed in plain text.
→ Flow Surface: Who talks to whom, in what order, and how easy it is to trace that flow across time.
→ Compute surface: Which machines get to see raw data while executing logic.
Most “privacy tech” is just moving one of these surfaces around. Some designs, like Monero, hide identities at the protocol level. You will never see a clean link between the person who spent and the person who received. The inputs are mixed with decoys, receivers get one-time style addresses, and outsiders only see that the totals still balance.
Some designs, however, separate public and private activity. Think Zcash. You keep a normal, transparent pool for compatibility, and a shielded pool for when you want sender, receiver, and amount to disappear from public view, while proofs make sure nothing breaks.
Then, we have some designs that focus on the flow of actions. These are Mixers and Tumblers. They try to make it harder for anyone watching the network to match “this person is about to do this trade,” or to trace a straight line between liquidity flows. We have private intents, internal matching, delayed broadcasts, and encrypted mempools working on that surface.
Finally, some designs move the question to the execution layer. They care about who gets to see your raw data when the system is running logic. That is where multi-party computation, hardware enclaves, or encrypted execution show up. They change who needs to be trusted while the work is being done.
When you look at it this way, privacy is simply a pattern you design. ZK, FHE, MPC, TEEs, and network-level protections are just ways of deciding what different observers are allowed to learn from your system. So, the privacy model is the arrangement, while the tools are how you enforce it.
--------
📌 Third: FHE As Encrypted Execution
In most real designs today, ZK proofs and privacy systems still leave the last layer of execution exposed. A user or sequencer may hide inputs from the chain, and the network or prover may hide flows from observers, but the executor still sees your data before returning output. That weakens end-to-end privacy.
People tried to close this gap with secure multi-party computation and trusted hardware environments, each with their own trust and performance tradeoffs. This is why Fully Homomorphic Encryption answers the question: “Can the machine that runs my code stay blind from start to finish?”
With FHE, you encrypt your data once, send only ciphertext, and allow an untrusted machine to run the logic directly on that encrypted form. The machine will never learn your real inputs, and when you decrypt the final output, you will get the same result you would have gotten if the computation had been run normally.
At first glance, it looks similar to ZK, but the axis is different. That is, ZK proves a result without showing the underlying data, while FHE produces the result without ever seeing the underlying data.
If you want everyone else to trust that the encrypted execution followed the right rules, you can still add a ZK proof around it later. But the core of FHE is at execution, not verification.
Below are examples of use cases:
→ A market that runs on FHE can update positions or balances without exposing them to validators.
→ A matching engine or intent layer can work on encrypted orders while only revealing final trades.
→ A credit or scoring system can process encrypted financial or identity data without anyone seeing the raw information.
So if ZK is the tool that gives the world proof verification, FHE is the tool that executes data while everything stays hidden.
The constraint FHE has is cost. The gates are very heavy, and every multiplication and bootstrapping step has a price, which slows adoption and scale. However, just as with ZK and privacy, there are improvements, and we will definitely see growth in the coming years. This is why Zama and Fhenix exist today.
--------
📌 The Triangle: ZK Privacy FHE
When you put the three questions side by side, you realize that in designs, you rarely pick only one. For example:
→ A private payment system might keep balances encrypted with FHE, use ZK proofs to show that no extra money was created, and rely on stealth-style addresses and routing to ensure that outsiders do not see who paid whom.
→ A rollup might use ZK to compress a batch of transactions, use privacy at the RPC or intent layer to reduce MEV and tracing, and keep FHE for only a small set of sensitive operations, such as credit scoring or identity checks. Thirdly;
→ A crosschain protocol might use ZK as a light client to verify state on another chain, apply privacy patterns to avoid leaking which account is moving funds, and still keep some information or parameters encrypted under FHE so that no relayer ever sees them.
From a marketing perspective, they all look like privacy techs because of the language used. “Trustless,” “Privacy preserving,” “Encrypted,” and “Zero knowledge” all signal that ZK appears in privacy systems, privacy systems use ZK and FHE, and FHE protocols promise to limit unwanted transparency.
However, as explained above, they have distinct roles, share some design patterns, and amplify each other. One thing they cannot do is replace each other. That is why you should see them as a triangle.
--------
📌 A Memorandum Of Understanding
Once you separate their roles, you gain clarity that:
→ A ZK rollup like zkSync or Starknet is not automatically a private chain. Same with ZK infra like Brevis, Axiom, Cysic, and Succinct. They can prove execution cheaply, but still need a privacy system on top if you do not want the world to see everything.
→ A privacy coin without a strong proof design and good handling of metadata can leak information or suffer from heavy verification costs.
→ An FHE chain without ZK or large economies of scale might keep everything encrypted, but still has to trust someone or something to ensure that computation is correct at all times.
The purpose of this is to help us avoid lazy labeling. When you are researching a “privacy” token, you should know the right questions to ask. For example:
→ What proof engine does it use?
→ How is privacy arranged at each surface?
→ Which parts, if any, are actually using encrypted execution?
--------
📌 The Driver Of The Next Cycle
ZK, Privacy, and FHEs will become the center for Web3 growth in the coming months and years. This is because, as more users and institutions move on-chain, they will want to use private systems with zero-knowledge and encryption. The goal is to prove the truth, control visibility, and compute on secrets, while the crypto economy grows.
Thanks for reading!
I thought I understood crypto already
but this week humbled me again.
I learned 5 new things that showed me how much money I’ve been leaving on the table.
If you want to stop repeating the same silent mistakes, read this:🧵👇
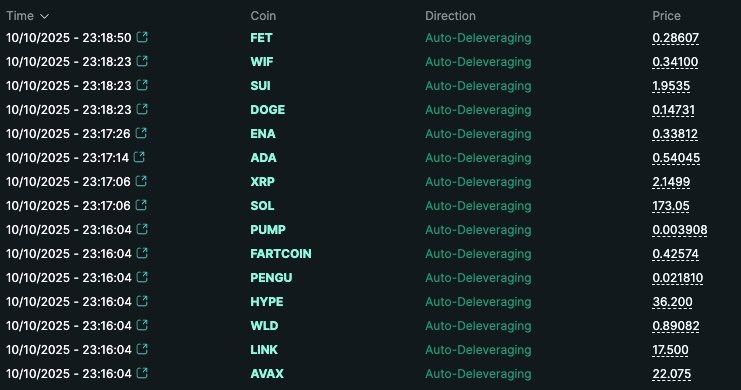
1/ Since a lot of people are waking up to see their perps positions closed and wondering what the hell “Auto-Deleveraging” means, here’s a quick and dirty primer.
What is ADL? How does it work? And why does it exist?
➥ Your Complete $KAITO Ecosystem Airdrop Strategy
In September, many people received 4-5 figure airdrops from their staked KAITO, all without needing to climb the @KaitoAI leaderboard.
So, how do you strategize effectively?
Here's the no-nonsense guide:
❶ Vanilla Stake
If you have idle capital, buy and stake KAITO to $sKAITO. While there are no official qualification numbers for the airdrop, a target of over 5,000 sKAITO (~$7,800) is a good benchmark, earning approximately 7% APY.
—
❷ Small Capital → YT Strategy
For smaller capital (<$5,000), consider buying YT-KAITO on @pendle_fi. Each YT represents yield from 1 sKAITO, including all future points and airdrops of staked KAITO.
With about $1,200, you can acquire YT equivalent to 5,000 sKAITO. However, YT expires in January 2026, meaning it will eventually be worthless.
If you believe the Q4 2025 airdrop will surpass your investment in YT, this option is favorable. Otherwise, you can trade it anytime (it has already doubled since last week).
—
❸ KAITO Maxi → PT Strategy
If you're a KAITO Maxi focused on growth, consider choosing PT. While this option forfeits all future ecosystem airdrops, it offers a maximum APY of approximately 90%, outperforming the returns from staking KAITO alone. Unlike YT, PT will convert to sKAITO at a 1:1 ratio upon expiration.
—
❹ LP Strategy
Lastly, consider the LP strategy, which lets you benefit from both YT and PT participation.If you've already staked sKAITO, you can deposit it here to boost your yields as a liquidity provider and hedge your airdrop position.
This strategy enables you to earn ecosystem airdrops while also gaining APY from trading fees, PENDLE emissions, and more. However, please note that you'll receive only a portion of the airdrop, not the full amount.
e.g. if the ratio is 20 PT:80 SY → You will get 80% of the airdrop proportion which is quite good for hedging consider that the airdrop is not fully unlocked for some projects.
To maximize your APY, using vePENDLE as a booster is crucial.
However, if you prefer not to, you can utilize third-party $PENDLE optimizers like @Penpiexyz_io and @Equilibriafi.
—
► Credits:
Special thanks to @Rightsideonly for clarifying some LP mechanics.
If you’re into learning ZK this thread is for you.
Here you will find ALL the modules from the previous 2 seasons of the ZK Whiteboard Sessions.
P.S. We're dropping a new Module this coming Tuesday
Let’s start.
The "Everything RWAs" database is back.
35+ projects you can read about, including:
• @PlasmaFDN
• @maplefinance
• @plumenetwork
• @gaib_ai
• @OpenEden_X
• @avax
• @Figure
• @CredoraNetwork
• @BackedFi
• @capapp
Big thanks to @x_yl625, who motivated me to update it and contributed to the project.
More projects will be listed over the next weeks. If you have any suggestions, feel free to leave them in the comments.
Check it out: https://t.co/cYhVKmLLRA.
A new contendor has entered the chat.
Driving the fully onchain narrative and gaining tons of momentum.
This ecosystem is looking promising and could possibly be the next BIG thing.
A deep dive into the @Somnia_Network ecosystem ⤵️