He/him. IT Professional, geek, photographer, car enthusiast, gamer. Mentor to startups/entrepreneurs and Adjunct Lecturer to IT Uni students. Views are my own.
An IBM mathematician spent 3 years convinced he was the worst programmer at his company at work.
He built to escape that embarrassment became the first high-level programming language in history. Every line of code running on Earth today traces back to that one act of shame.
His name was John Backus.
He was born in 1924 in Philadelphia, the son of a wealthy stockbroker who expected him to follow the same path. He failed out of the University of Virginia. He dropped out of Haverford College. He enrolled in a medical program in the Army and decided he hated medicine. He spent years doing exactly nothing the conventional way.
Then one afternoon in 1945 he walked past a radio repair shop in New York and got talking to the owner and ended up building a radio from scratch in the shop's back room. Surprising thing is he had never done it before. He stayed for hours. When he left he knew what he wanted to study.
He taught himself mathematics and got into Columbia. From Columbia he walked into IBM in 1950 with a degree and no idea what he was doing.
He learned to program on machines that had no business being programmed. IBM computers in 1950 spoke in machine code. Raw binary. Every instruction written as a string of ones and zeros that told the hardware exactly which switches to flip. There were no shortcuts. No syntax. No vocabulary a human brain could hold in its head.
The programmers who were good at it held the entire machine inside their minds. They saw the binary and felt the logic. Backus could not do this. He wrote programs that were slow, tangled, and embarrassing next to what his colleagues were producing. He was not the worst programmer at IBM. But he believed he was, which amounted to the same thing.
He started building a tool to help himself. Not out of ambition. Out of humiliation.
The idea was simple to the point of seeming naive. He wanted to write mathematical expressions in something that looked like mathematics, not machine code, and have the computer translate them automatically into the binary the hardware needed. He called the project a "formula translation" system. His colleagues thought it was a nice idea that would never work.
The problem everyone could see was speed. Machine code written by a skilled human would always run faster than code generated by an automatic translator. The translator had to make guesses. Guesses meant inefficiency. Inefficiency meant the whole project was a toy.
Backus spent three years proving them wrong.
In 1957 IBM released FORTRAN to its customers. The first compiled programming language in history. The translator Backus built was so efficient that the code it generated ran at speeds within 20 percent of hand-written machine code. Not a toy. Not a curiosity. A working tool that let scientists and engineers write programs in expressions their own minds had generated, and watch the machine execute them.
The adoption was immediate and total. Scientists who had spent careers translating their equations into machine code by hand were suddenly writing programs in hours instead of weeks. Labs that had used IBM machines for narrow tasks started using them for everything. The market for computing changed overnight.
Then something happened that nobody predicted. Other people started building other languages using the same idea. COBOL. LISP. ALGOL. BASIC. Every language built its own translator using the architectural logic FORTRAN had demonstrated. The idea that a computer could read something resembling human thought, rather than the other way around, was now a proof of concept that anyone could extend.
Every programming language that has ever existed was built on the answer to the question Backus asked because he was ashamed of the code he was writing.
He won the Turing Award in 1977. The committee citation said his work had made it possible for more people to use computers for more things than any other single development in the history of computing.
He said in the acceptance speech that he had not set out to change computing. He had set out to stop writing bad code.
The gap between what you are bad at and what you are trying to fix is usually where the real invention lives.
@TracketPacer Had similar reactions when I submitted budget requests to get professional RF surveying done at my enterprise.
It was easier to explain away professional services instead of the equipment that my qualified engineers could use to do the same job.
#facepalm
You have noticed that too. Google Search is getting worse. The results look professional but say nothing. The answers are longer but less useful. Every page reads like it was written by the same voice.
You thought Google was broken. It is not broken. It is being replaced.
Researchers published a paper at the ACM Web Conference 2026 proving what is happening. They call it Retrieval Collapse.
Here is the mechanism in one sentence. AI-generated content is flooding the internet so fast that search engines are now showing you mostly AI-written pages. And the search engine cannot tell the difference.
They ran a controlled experiment. They started with a pool of real, human-written web pages. Then they gradually added AI-generated content until it made up 67% of the pool.
By that point, over 80% of the top search results were AI-generated. Not 67%. Over 80%. The ranking algorithm did not just let AI content in. It preferred it. The AI-written pages were better optimized, more fluent, and more keyword-rich than the human pages. They outranked the originals.
Here is the part that makes this invisible.
Answer accuracy stayed the same. The search results still looked correct. The information was still technically right. If you measured quality by accuracy alone, nothing appeared wrong.
But source diversity collapsed. Nearly every result came from the same type of content. AI-written. AI-optimized. AI-structured. The human-written pages, the ones with original reporting, personal experience, and genuine expertise, were buried.
The researchers describe a two-stage collapse. Stage one is Dominance. High-quality AI content silently takes over the top results. Everything looks fine. Accuracy is stable. Nobody notices. Stage two is Corruption. Once AI dominates the pipeline, adversarial and low-quality content starts slipping through. By then, the system is too dependent on synthetic sources to course-correct.
A separate analysis found that 74.2% of newly published web pages now contain AI-generated content. Organic click-through rates on pages with AI summaries have dropped 61%. The human internet is being outranked by the machine internet.
Model Collapse described what happens when AI trains on AI. The models get dumber. Retrieval Collapse describes what happens when search engines index AI. The results get emptier.
Both are happening right now. At the same time. And neither one looks broken from the outside.
The search engine still returns ten blue links. The links still load. The pages still answer your question. But the thing that used to make those answers trustworthy, a human who actually knew something, is being quietly replaced by a machine that sounds like it does.
@NRMA That might make sense, but maybe update your main pages to showcase that? Nothing in the pages or even the receipt to my retired parents said that.
It feels like a bait and switch.
Hey @NRMA - stop taking advantage of stressed-out folks and step up your game!!! Stop with the blatant false advertising of car battery prices for folks who are stranded.
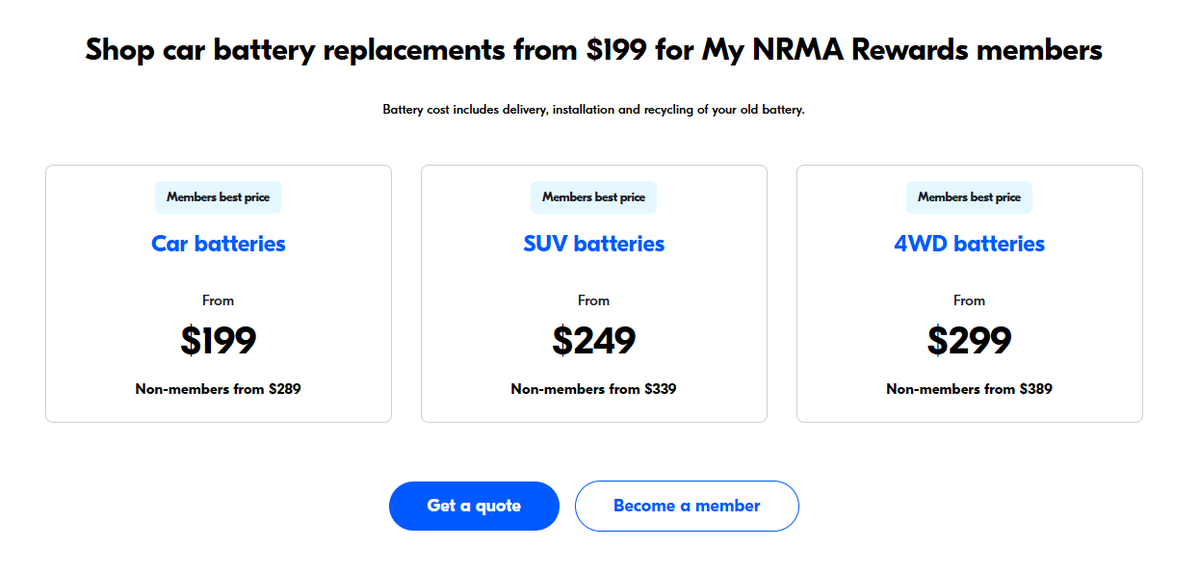
Pic1 - range of prices for different vehicle types.
Pic2 - actual quote when you search for your vehicle
and before you all ask - no, this isn't about me, but for my retired folks....
Hey @acccgovau - this doesn't pass the pub test. Surely they can't just say "prices from" and expect people to make an informed decision?
A French engineer who lives quietly in Paris has spent 30 years writing software that the entire internet now runs on without knowing his name.
He wrote the code that streams every YouTube video, every Netflix show, every TikTok clip. He wrote the code that runs the virtual servers underneath AWS, Google Cloud, and Microsoft Azure. He calculated more digits of pi than anyone in history. He has no Twitter. He has no marketing. He just keeps shipping.
His name is Fabrice Bellard.
Here is the story, because almost nobody outside the systems programming world knows what one man has built.
Fabrice was born in 1972 in Grenoble, France. He studied at École Polytechnique, the top French engineering school. He never went to Silicon Valley. He never built a startup empire. He just wrote code.
In 2000 he started a project called FFmpeg, an open-source multimedia framework for encoding, decoding, and streaming video. He was 28. The project did one thing nobody else had done well. It handled every video and audio format that existed, in one library, on every operating system. He led it himself for years.
Today FFmpeg is the invisible engine of the internet. YouTube uses it. Netflix uses it. VLC uses it. Chrome and Firefox use parts of it. Every Android phone, every iPhone, every smart TV, every video editing tool you have ever touched runs FFmpeg somewhere underneath. If you have watched a video on a screen in the last 20 years, Fabrice's code processed it.
He was not done.
In 2003 he started QEMU, a machine emulator and virtualizer. He wrote it solo until version 0.7.1 in 2005. QEMU lets you run any operating system on any other operating system. It became the foundation of modern virtualization. KVM, the Linux kernel hypervisor, runs on top of QEMU. Every major cloud provider, AWS, Google Cloud, Microsoft Azure, IBM Cloud, runs virtual machines on infrastructure built around it. The Quick Emulator is the most cited piece of cloud infrastructure code on Earth.
He kept going.
In 2001 he won the International Obfuscated C Code Contest with a small C compiler that grew into TCC, the Tiny C Compiler. TCC can compile and boot a Linux kernel from source in under 15 seconds. In 2004 he calculated the most digits of pi ever computed at the time, using a personal desktop computer and an algorithm he derived himself called Bellard's formula. In 2011 he wrote a complete PC emulator in pure JavaScript that runs Linux in your browser, a project called JSLinux that engineers still cannot believe is real.
In 2019 he released QuickJS, a small but complete JavaScript engine that fits where V8 cannot. In 2021 he released NNCP, a neural network based lossless data compressor that immediately took the lead on the Large Text Compression Benchmark.
Then he turned his attention to large language models. He built TextSynth Server, a web server with a REST API for running LLMs locally. He released ts_zip and ts_sms, compression utilities that use language models to compress text and short messages at ratios traditional algorithms cannot reach. He released TSAC, a very low bitrate audio compression system. In December 2025 he released Micro QuickJS, a new JavaScript engine for microcontrollers, separate from QuickJS, designed for environments with almost no memory.
Fabrice co-founded a telecom company called Amarisoft in 2012, where he serves as CTO. Amarisoft builds 4G and 5G base station software used by carriers and labs around the world. He has been running it for over a decade while continuing to ship personal projects from his own home page at bellard dot org
He has no Twitter. He has no Instagram. He gives almost no interviews. His personal website is a flat list of projects with no styling, no fonts, no marketing copy. Just titles and links.
A quiet French engineer who never moved to Silicon Valley wrote the code that quietly runs the internet.
He is still shipping.
JOB INTERVIEW:
"Why are you looking to leave your current company?"
Most candidates say:
"I'm just looking for a new challenge, and I feel like I've outgrown my current role and there's no room for growth..."
THE WINNING ANSWER:
Lots of helpful hints here. Most I’d completely forgotten if I even knew them at one point.
Worth reading through and implementing.
You “should” be able to find similar tips for other email providers too.
A guy sat at his laptop ready to permanently delete his 15-year-old Gmail account.
He was getting 400 spam emails a day. Fake Best Buy receipts. Phishing links from "Netflix." Cryptic extortion threats.
He hovered his mouse over "Delete Account" and sighed: "I just want peace."
His coworker, a former email deliverability engineer, looked over his shoulder.
"Before you nuke 15 years of contacts and data, let me show you something. Your email isn't broken. It's weaponized. There are 22 ways you've been leaving the door wide open. Google won't tell you this because the data collection feeds their entire ad engine. Give me 14 minutes."
Here's what she showed him:
The creator of Linux just publicly called out the AI hype. Word for word.
Linus Torvalds took the stage at Open Source Summit 2026 and said this:
"When I see people saying 99% of our code is written by AI, I literally get angry. Because those same people — I can pretty much guarantee — 100% of their code is written by compilers. But they never say that."
He is not anti AI. The Linux kernel saw a 20% jump in submissions this release because of AI tools. He uses it. He gets it.
His point is something most people are too afraid to say.
AI is a productivity tool exactly like compilers were. Compilers boosted programming by 1000x. AI adds another 10x on top. Enormous. But nobody says "the compiler wrote my code." So why are we saying AI wrote it?
He also flagged something nobody is talking about.
AI is flooding small open source projects with drive-by bug reports. Someone runs a prompt, files a report and disappears when asked for a patch. Maintainers with one or two people are drowning trying to keep up.
"Sometimes AI reports a bug and when you ask for more information the person has done that drive-by and does not even answer your question. That is the real burnout issue."
And his final warning was the sharpest of all.
"People who do not understand the complexity of systems will prompt systems and write processes that will fail."
The AI hype crowd is very loud right now.
Linus has been building real systems for 35 years. When he talks, engineers listen.
Full interview here:
https://t.co/LmXJtvKc4O
CEOs are quietly realizing the AI replacement plan has a problem.
Two problems, actually.
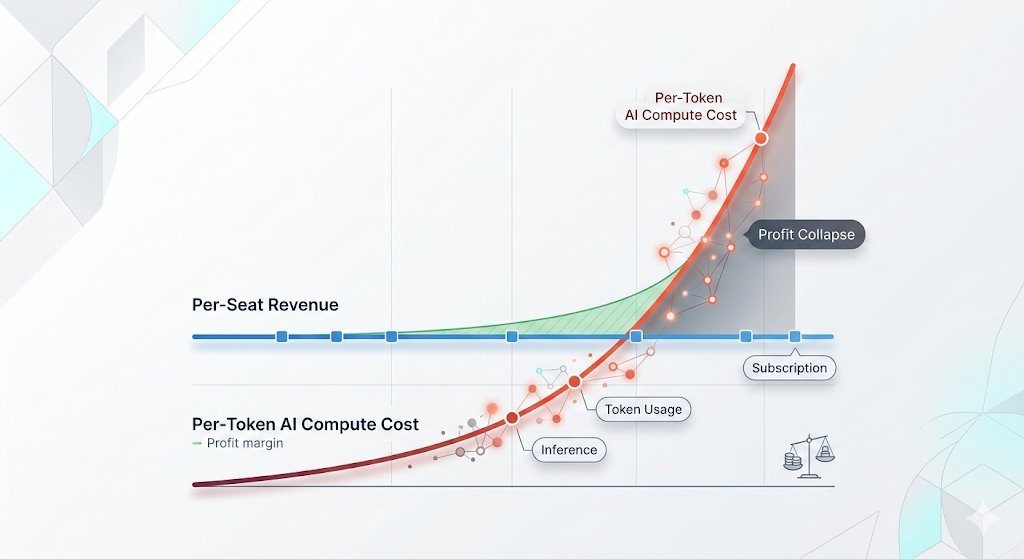
One: the token costs for running AI agents are now exceeding what they were paying the employees they fired.
Two: when the tokens run out, the AI stops. Just stops. No continuity. No workaround. Just a spinning wheel where your workforce used to be.
You fired humans to save money and bought a subscription that bills you into a corner.
The employees you let go knew what to do when things broke.
The AI just invoices you for the outage.
And then there’s the permission problem nobody wants to talk about.
To do its job, the AI agent needs access. Full access. Your systems, your patents, your contracts, your future plans. Everything you spent years building, handed over to a process that has no loyalty, no discretion, and no skin in the game.
You didn’t hire a replacement.
You gave a stranger with no soul the keys to everything you own.
Enjoy.
Microsoft just banned its own engineers from using AI.
The tool was literally costing MORE than the humans it was supposed to replace.
They lied to you about AI adoption and now the whole narrative is blowing up:
Microsoft gave thousands of engineers access to Claude Code six months ago and encouraged them to use it.
Engineers loved it and adoption exploded. But then the invoices arrived.
Token-based pricing means every query, every code review, every debugging session costs money. At scale across 100,000 engineers, the numbers became so large that Microsoft issued an internal order to cancel nearly all Claude Code licenses by end of June and force everyone onto their own cheaper tool instead.
The company that invested $5 billion in Anthropic just told its own people to stop using Anthropic's product because it costs too much.
Uber's story is even worse...
Their CTO Praveen Neppalli Naga told The Information that the budget he planned for the full year was "blown away already" by April.
Uber had rolled out Claude Code in December 2025. By March, 84% of their 5,000 engineers were using it with 70% of all committed code coming from AI systems.
Heavy users were burning $500 to $2,000 per month each. Naga himself spent $1,200 in a single two-hour demo session.
The company had even built internal leaderboards ranking engineers by how much AI they used. They literally gamified the spending and then ran out of money.
Now look at what Nvidia's own VP of applied deep learning Bryan Catanzaro said to Axios last month. Direct quote:
"For my team, the cost of compute is far beyond the costs of the employees."
This is a VP at the company that SELLS the chips saying that using AI is more expensive than paying humans.
Think about what this means for the entire AI narrative.
Every CEO on every earnings call for the past two years has said the same thing:
AI will make us more efficient, reduce headcount, and cut costs.
The stock market rewarded every company that said it.
Fired workers, stock goes up. Announced AI adoption, stock goes up.
But the actual companies deploying AI at scale are discovering the math doesn't work. The MORE employees use AI, the HIGHER the bill.
Goldman Sachs forecasts a 24x increase in token consumption by 2030 as companies adopt AI agents. Gartner just published a report showing that even though individual token prices will drop 90% by 2030, total enterprise AI costs will go UP because agents consume exponentially more tokens per task than basic tools.
Meta built an internal dashboard called "Claudeonomics" to track which employees use the most AI. Amazon started pushing engineers to "tokenmaxx," their internal term for consuming as many AI tokens as possible.
Both companies are spending hundreds of billions on AI infrastructure this year alone.
And Microsoft, the company that bet its entire future on AI, just told 100,000 engineers to stop using the tool they liked best because the per-token bills got out of control.
The companies building AI are telling investors it saves money. The companies using AI are finding out it costs more than the humans it was supposed to replace. And even the company that makes the chips just admitted it through its own VP.
This is the gap nobody on Wall Street is pricing in.
$725 billion in AI infrastructure spending this year across Big Tech. And the first companies to actually deploy these tools at scale are already pulling back because the economics don't work.
What do you think?
Some of you have forgotten that only three years ago you were perfectly capable of writing an essay, writing a eulogy, telling a bedtime story to a child, and it should worry you that powerful companies have convinced us we can’t do things we’ve been doing for 5,000 years.
The AI bubble math doesn't add up.
Anthropic spends $3 to make $1 and that’s before you include any and all other costs like staff or electricity.
Microsoft dumped $300B in capex, made ~$18B in AI revenue. OpenAI and Anthropic alone make up 43-54% of Microsoft, Google, Amazon and Oracle's entire revenue backlogs.
Enterprises are burning through annual AI budgets in 4 months with zero measurable ROI.
This is the most expensive science experiment in history, funded by your SaaS subscriptions.
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
@ICT_GURU@grok You asked grok the wrong question…. It ought to be “which passport allows the least hassle for travelling to all countries on this route”.
Visa-free travel isn’t the issue when border control don’t like the look of you.