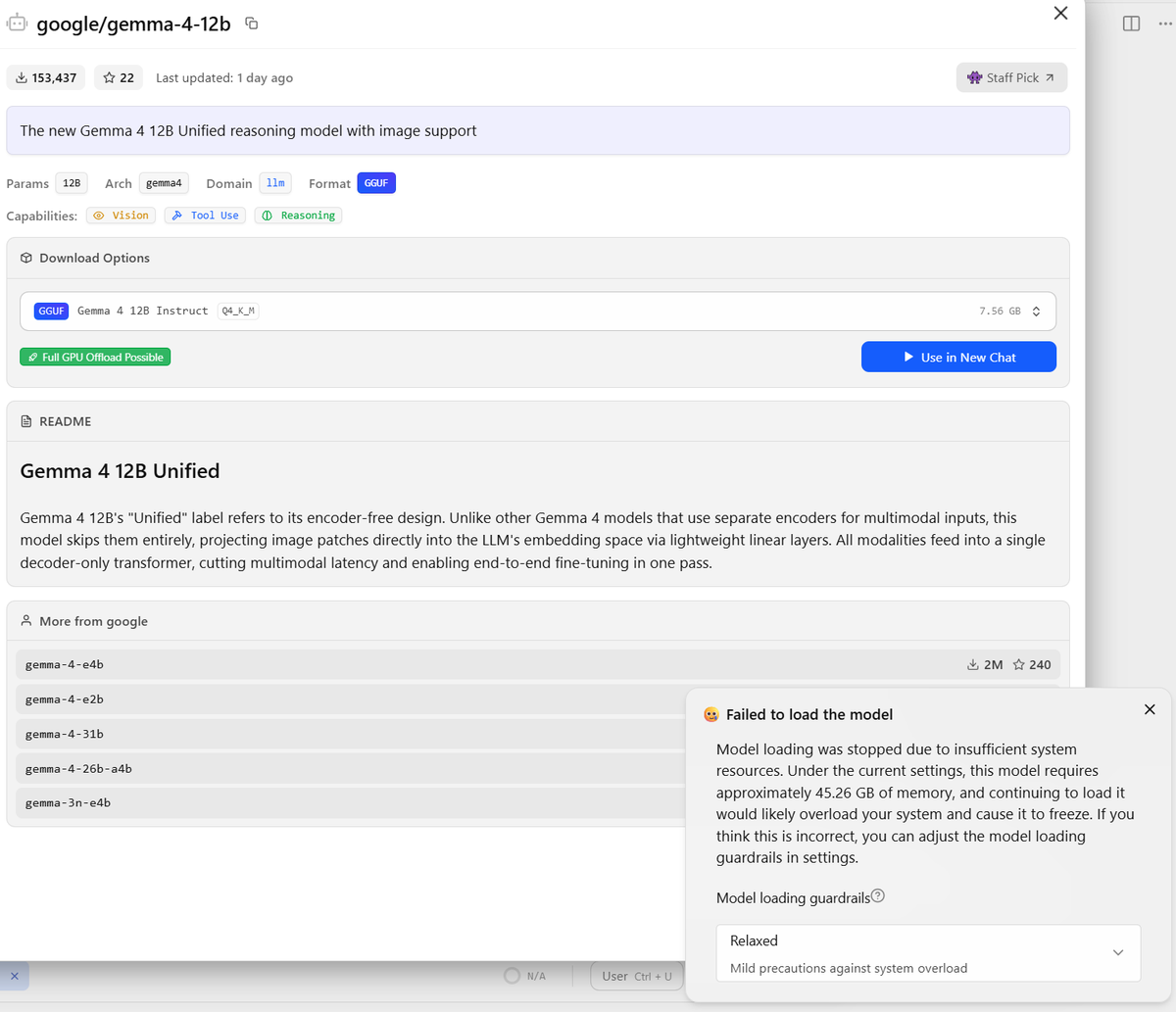
🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: +21.8% on Kimi Code Bench v2, +11.0% on Program Bench, and +31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: https://t.co/uvoSJKyGCY
🔗 API: https://t.co/EOZkbOwCN4
Humanoid robots don't need to look human.
Meet Eno, our first general-purpose robot.
Not a machine pretending to be human, but intelligence given a body.
At Genesis, we’re building a future where robots don’t feel cold or distant, but capable, calm, and ready to help.
Available Q4 this year.
we just built what @satyanadella is talking about.
here's the ultimate COMPANY BRAIN, your sovereignty 👇🏼
try here- https://t.co/p4xkDWmefL
minimi feeds Claude every tab, doc, call, and thread on your mac. add your team-mates' links and claude knows their work as well. 💫
Apple hid 15.8 TFLOPS of raw AI power in every M4 Mac & iPhone.
They only let you use the Neural Engine for inference.
Reverse-engineered their private APIs and ran full backpropagation & transformer training directly on the
ANE, No CoreML, No Metal, No GPU,
- Training transformers at 9.3ms/step on M4.
Full transformer training forward pass, backward pass, attention, gradients, optimizer
Everything in memory.
- Built custom MIL (Model Intermediate Language) programs from scratch
- Compiles neural network graphs directly to ANE hardware in memory
- Zero external dependencies.
Just system frameworks. without disk writes, mlmodelc files,
Everything happens in memory , The hardware was capable.
The workaround? Right
The program checkpoints its state and restarts itself via exec().
It literally respawns to keep training.
Now you can train on Apple's Neural Engine.
- https://t.co/1i5q9L7K4l
A PhD student built a working nuclear fusion reactor in his garage, let an AI run it, and 400 thousand dollars later he works for Elon Musk.
he posted it once. that single post ended with a grant in his account and a job offer from the most powerful man on earth.
not a simulation. not a school project. an actual device that fuses atoms, sitting where his car used to be.
fusion is the thing governments have been chasing for 70 years with billion dollar labs. the hard part was never the reactor itself. it was the control. the plasma inside has to be held at conditions hotter than the core of the sun, and it shifts and collapses in milliseconds. no human can react fast enough to keep it stable.
so he stopped trying to do it himself. he handed the control loop to an AI.
the model reads the sensor data hundreds of times a second, predicts how the plasma is about to move, and adjusts the magnetic fields before it ever drifts out of line. it does not wait for the plasma to misbehave. it sees it coming and corrects it before it happens. the same reaction-before-the-event speed no person could ever match.
this is the exact kind of build people are tearing apart inside @NeuroClubAi. not to make reactors, but because the workflow is identical for anything hard. let the AI run the loop, predict the problem, fix it before it breaks. same playbook whether it is plasma or a business.
then the post went out.
within days Elon's fusion team reached out. they did not ask him to interview for an entry role. they handed him a 400 thousand dollar grant and pulled him onto the team building this at scale. one garage build turned a PhD student into an operator for the most ambitious man alive.
here is the part that should stop you.
he was one guy with a PhD, a garage, and an AI model doing the job that entire teams of physicists used to fail at. the AI was not assisting him. it was the operator. he built the hardware. the machine ran it. and that was enough to get noticed at the very top.
most people think AI writes emails and makes pictures. meanwhile someone pointed it at one of the hardest physics problems on earth, held the plasma steady, and got paid by Elon Musk for it.
the gap is not between humans and AI anymore. it is between the people who realize what this thing can already do and the people still using it to summarize their inbox.
The gap between AI products for devs vs for non-technical people is beginning to close
I switched to Codex a month ago - it was a massive upgrade. Tons of tasks that ChatGPT or Claude failed, Codex did seamlessly
20% of Codex users now are non-technical and this should grow 👇
Alibaba’s new Qwen3.7 Max model scores 56.6 on the Artificial Analysis Intelligence Index, 4.8 points higher than Qwen3.6 Max Preview (51.8). While Alibaba still trails models from OpenAI, Anthropic and Google, Qwen3.7 Max is the closest they have been to the frontier
Qwen3.7 Max is @Alibaba_Qwen's latest proprietary flagship, scoring 56.6 on the Intelligence Index, a 4.8 point gain over Qwen3.6 Max Preview (51.8) released in April. Qwen3.7 Max continues Alibaba's pattern, in place since Qwen2.5 Max (January 2025), of releasing Max and Plus models as closed weights while the rest of the Qwen line remains open weights. The leading open weights Qwen on the Intelligence Index is Qwen3.6 27B (Reasoning, 45.8) released in April 2026, and the leading open weights MoE Qwen is Qwen3.5 397B A17B (Reasoning, 45.0) released in February 2026
Key takeaways for the reasoning variant:
➤ The Intelligence Index gains over Qwen3.6 Max Preview are concentrated in scientific reasoning, agentic capability and coding. CritPt +9.7 p.p (3.7% to 13.4%), HLE +9.2 p.p (28.9% to 38.1%), TerminalBench Hard +6.9 p.p (43.9% to 50.8%) and GDPval-AA +42 Elo (1504 to 1546). Scores on other benchmarks in the Intelligence Index are flat compared to Qwen3.6 Max Preview
➤ A significant share of the Intelligence Index gain is driven by higher abstention on AA-Omniscience, not higher accuracy. Qwen3.7 Max's accuracy on AA-Omniscience dropped 7.6 p.p (37.7% to 30.1%), while its hallucination rate dropped 21.3 p.p (44.2% to 22.9%). The model is choosing not to answer more questions rather than recalling more facts. Because hallucination rate and accuracy both feed into the Intelligence Index, the hallucination reduction is one of the larger single contributors to the +4.8 point gain on the Intelligence Index
➤ Qwen3.7 Max used 96.7M output tokens to run the Intelligence Index, ~31% more than Qwen3.6 Max Preview (73.9M). It sits mid-pack on frontier token usage: above GPT-5.5 (high, 44.5M) and Gemini 3.1 Pro Preview (57.3M), below Claude Opus 4.7 (Adaptive Reasoning, Max Effort, 112M), Kimi K2.6 (166M) and DeepSeek V4 Pro (Reasoning, Max Effort, 187M)
Key model details:
➤ Context window: 1M tokens (up from 256K on Qwen3.6 Max Preview)
➤ Multimodality: Text input and output only
➤ Pricing: Yet to be announced (Qwen3.6 Max Preview is priced at $1.30/$7.80 per 1M input/output tokens on the @alibaba_cloud first-party API)
➤ Licensing: Proprietary, closed weights
13 open-source tools for foundation model deployment
▪️ vLLM
▪️ Ollama
▪️ Hugging Face TGI
▪️ BentoML
▪️ Seldon Core
▪️ Kubeflow
▪️ MLflow
▪️ MLRun
▪️ Metaflow
▪️ TensorFlow Serving
▪️ TorchServe
▪️ SGLang
▪️ llama.cpp
Save the list and learn where to use each of them here → https://t.co/DtqulL1P6P