Saturday Kill List - 13 June 2026
5 ideas we'd kill before you write a line of code.
This week every one came from a source that only proves the thing already exists. A startup database. A YC company page. A "top 10 emerging startups" list. A trade-press trend roundup. A freelance gig. Five proofs that someone is already building or selling it. Not one is a customer.
From the deadest up.
1 Imitation Learning Middleware - LRS 30.7 - YC list
0 monthly searches. Source was a "top 10 emerging startups revolutionizing robotics" listicle. Universal Robots, Fanuc and NVIDIA already own the stack. VCs are pouring in (funding signal 10/10), but budget proof is 3/10. Money is moving; buyers are not.
Funded is not the same as wanted.
2 5G Optimization Software - LRS 30.8 - Seedtable
0 monthly searches. Source was a startup-database profile of a funded company already doing it. Nokia, Huawei and Ericsson are the market. The entry you found is not a gap. It is your competitor's listing.
A database entry is a competitor, not a customer.
3 Botanical Hormone Support Lattes - LRS 32.0 - FoodNavigator
The one with traffic: 2,205 searches a month. But only 8% want to buy, you'd fight Amazon and 30 brands, and category budget proof is 0/10. Source was a "top functional food trends 2026" roundup.
Searched is not the same as bought.
4 Hardware R&D Talent Pipeline - LRS 32.2 - Freelancer
0 monthly searches. The entire idea came from one gig posted on Freelancer. Robert Half, TEKsystems and Kforce already staff this for a living. From r/ECE: "I am very frustrated when it comes to applying for entry level jobs."
One gig is one buyer, not a market.
5 RentAHuman, real-world tasks marketplace - LRS 32.7 - YC
0 monthly searches. Source was a YC company page. A funded company is not your validation. It is your competitor. TaskRabbit, Upwork, Fiverr and Thumbtack already own real-world tasks.
Someone already shipped it. That is the problem, not the proof.
5 ideas. 5 sources. Zero of them were "I found a painful problem nobody is solving."
All 5 were "someone is already building this, so it must be real."
Supply you can see. Demand you have to prove. The market did not show up: 4 of these 5 have zero monthly searches; the fifth has 2,205 searches and 8% real buy-intent.
A note on what LRS cannot see.
LRS reads public, consumer-style demand only. Search volume, complaint threads, named incumbents, funding rounds, monetization patterns. It cannot see institutional demand that lives in private sales cycles.
Two of this week's five, Imitation Learning Middleware and 5G Optimization Software, sell into exactly that world: funded robotics teams and telecom carriers. If a founder there is holding signed LOIs or MOUs from tier-1 buyers, the real market may exist exactly where no public signal can show it. That is a genuine green light the score will miss.
The named incumbents above are the wall. A signed pipeline the public cannot read is your ladder. Absent that private edge, a founder confusing thesis with traction loses six months and a runway.
If you have it, the kill argument is wrong. Tell us what we missed. We will re-score.
Want your idea graded on the same 6 signals before you sink a quarter into it?
$7. ~10 min. Human-readable report.
→ https://t.co/kT2HOUWu5y
More kills next Saturday.
Disagree with a call? Reply with which one we killed unfairly. The strongest pushback gets a follow-up post.
YC Demo Day is in 3 days, June 16
The biggest of the four groups (out of 194 YC-listed projects) is up: The AI Workforce, the agents coming for entire job functions. 56 startups automating the work people currently do, the largest group in the batch. Group average LRS: 49.1.
Same method as published yesterday: 6 public signals, a 0 to 100 Launch Readiness Score (LRS). Search demand, social pain, competition, monetization, funding, urgency. Public data only, the outside view every investor can run before the meeting.
Highest scored:
1. Saffron, 59.9, AI-aware engineer tests
2. Pentagon, 59.5, AI agent teams
3. InstaAgent, 58.8, multi-persona ad campaigns
4. OpenWork, 58.5, self-hosted agent workspace
5. Userlens, 58.2, customer-success signals
Lowest on the outside view:
52. Sidekick, 40.8, text-based frontline helpdesk
53. Keyframe Labs, 39.3, photoreal AI video calls
54. Light Anchor, 39.1, agent-operated brands
55. Pops, 38.7, social AI gaming
56. Drafted, 37.6, AI home blueprints
If the score reads a team low, it usually means real traction the public data can't see yet. Signed customers, design partners, private demand, LOIs - make a big difference. Closing that gap is the Demo Day job.
3 things the data says about this group:
1. The batch is fighting a dozen landlords. For 29 of 56, a frontier lab or Big Tech platform could be regarded as a direct competitor, or a potential acquirer: Microsoft or Copilot shows up in 21 of the reports, OpenAI or ChatGPT in 16, GitHub in 13. Most of these read less like standalone companies and more like features orbiting a handful of giants that can ship the same thing and bundle it for free. The real question for each one is what the platform can't, or won't, absorb.
2. The crowd goes to the back office; the score rewards the rooms nobody's in. 19 of 56 automate back-office ops, the most crowded lane, and it scores middling (avg LRS 48.5). The highest-scoring jobs are the least crowded: recruiting and HR (57.0) and sales (52.7). The agents are piling into repetitive desk work, while the score pays off for the teams that went where others didn't.
3. "AI and Automation" is the lowest-scoring label in the batch. The 29 vague AI-automation plays average 46.1; the 27 that name a specific job average 52.3, a 6.2-point gap, and every one of the bottom 6 is a generalist. Saffron does engineer tests, Userlens does customer-success signals, Pentagon does agent teams. The score pays a premium for specificity, and the engine says 39 of 56 still have to niche down.
How to use it:
- Founders in the batch: find your card, look at your lowest of the 6 signals. That's the question coming June 16. And if your one-liner is "AI automation for X," the room will ask which X you actually own.
- VCs and angels: want the full breakdown on any project, competitors, the category's funding history, the CAC vs payback math? The board is free at https://t.co/DfRK0nkHGo. DM us for the full per-project file, same-day, no charge. Or pull every report over the Fluenta MCP and run your own diligence in Claude or Cursor.
- Everyone watching from outside the room: the top of this board is a preview of what's coming. The highest-scoring names are the ones most likely to raise, and the ones a dozen builders will copy in their own market within a quarter. Scroll it if you're hunting for your next thing to build.
Browse all 194 scored: https://t.co/lM4X8lkhCH
Tomorrow, Group 3 of 4: AI Meets the Real World - robots, drones, defense, factories, energy, logistics, property.
Tagging the teams above in case you want to grab your report. No hidden subscription, no signup gate - the analysis is already done, the file is yours to pick up. DM here or email [email protected] and we'll send it same-day.
If the score reads you wrong, that gap is the thing to close on stage.
@roblukan (Saffron) · @edgarpavlovsky (Pentagon) · @klwongkyle (InstaAgent) · @benjaminshafii (OpenWork) · @ankur_d (Userlens) · @designtday (https://t.co/fnnzi6M5tr) · @burnedchris (Inth) · @aidan__pratt (Autostep) · @nikolas_keller (Walter)
Grab your full report: https://t.co/lM4X8lkhCH or DM us
YC Demo Day is in 2 days, June 16
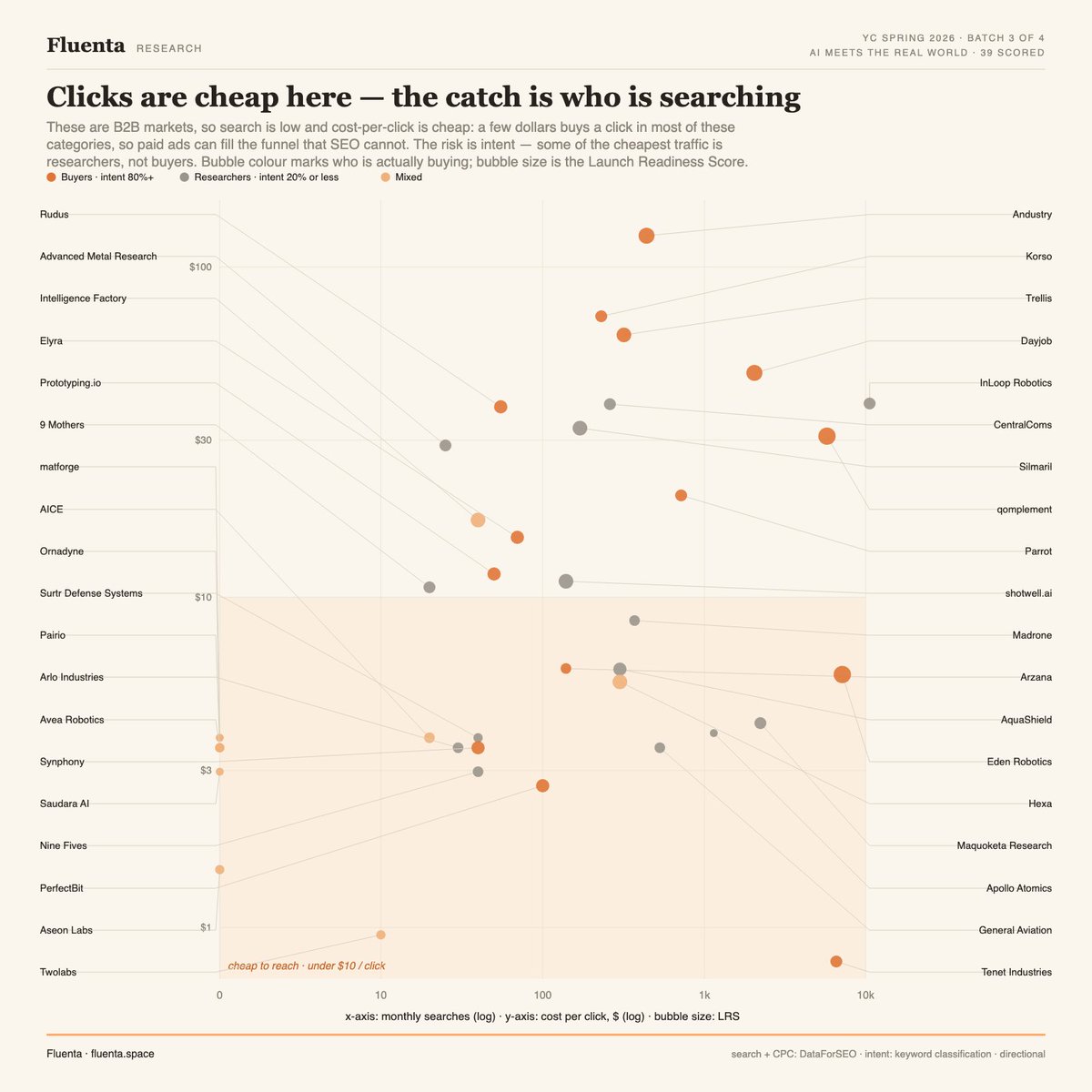
Group 3 of 4 is the hardest one to score from the outside: AI Meets the Real World. 39 startups building atoms, not bits, robots, drones, satellites, reactors, defense. Group average LRS: 46.3, the lowest of the four groups so far.
Same method: 6 public signals, a 0 to 100 Launch Readiness Score (LRS). Search demand, social pain, competition, monetization, funding, urgency. Public data only, the outside view every investor can run before the meeting.
Highest scored:
1. Eden Robotics, 61.8, robots for physical work
2. qomplement, 60.1, agentic ERP for supply chain
3. Dayjob, 58.9, AI dispatch for short-haul trucking
4. Andustry, 57.5, supplier discovery for manufacturers
5. Hexa, 54.8, autonomous ops for industrial distributors
Lowest on the outside view:
35. matforge, 36.8, AI scientists for new materials
36. Saudara AI, 34.1, AI sourcing for Indonesian factories
37. Apollo Atomics, 33.8, ultra-compact nuclear reactors
38. Dispatch, 32.9, reusable heat shields for cargo return
39. Ornadyne, 31.2, bird-like surveillance drones
When the score reads a team low here, it usually means the opposite of a weak company. Atoms do not generate search, and a low public signal often sits on top of signed pilots, defense contracts, or a category that buys through procurement, not Google. Closing that gap is the Demo Day job.
3 things the data says about this group:
1. The demand is invisible, and it is brand-shaped. We score these from the outside on public search, and the median is 100 searches a month, 30 of 39 under 500. But the category keyword is near-dead even for the giants: "microreactor" gets 450 searches a month while "Oklo" gets 66,000. Across this group the incumbent brand outsearches the problem term by a median of 17 times. Demand in atoms hides on brand names and inside procurement, not in keywords, so an outside-in search signal under-rates the whole category. The teams that look weak here are the ones whose buyers were never going to be found through a keyword.
2. The buyers split in two, with no middle. Purchase intent is bimodal: 14 of 39 sit under 20% transactional, researchers still asking whether the thing is possible, and 14 sit over 80%, operators ready to sign. Almost nothing in between. Half this group is selling to curiosity and half to budget, and which side you are on changes the entire go-to-market.
3. The capital already chose sides. Every company here gets the same "under-served" label, but the funding records tell a different story. 24 of 39 sit in a category where a competitor already raised 100 million dollars or more in the past year: Apollo Atomics against X-energy's 700 million, warehouse robots against Pudu's 150 million, humanoid eldercare against Apptronik's 350 million. Only 6 are genuinely open lanes with no nine-figure incumbent, data-center cooling, subsea, supplier discovery, short-haul dispatch. In atoms the moat is capital and contracts, so the real question is not market size, it is whether you can out-deploy a competitor who already has the war chest.
How to use it:
- Founders in the batch: find your card, look at your lowest of the 6 signals. If it is demand or competition, that is probably the public-data lens missing your buyer, and the room will ask you to prove the private traction it cannot see. If it is monetization, bring real per-unit economics.
- VCs and angels: want the full breakdown on any project, the named competitors, and the real funding history of the category? The board is free at https://t.co/DfRK0nkHGo. DM us for the full per-project file, same-day, no charge. Or pull every report over the Fluenta MCP and run your own diligence in Claude or Cursor.
- Everyone watching from outside the room: this is the group that gets cloned slowest and copied hardest once it works. The highest scorers are the teams that found a buyer in a market with no search term. Scroll it if you want to see where the next decade of hard things gets built.
Browse all 194 scored: https://t.co/lM4X8lkhCH
Tomorrow, Group 4 of 4: Care & Capital.
Tagging the teams above in case you want to grab your report. No hidden subscription, no signup gate - the analysis is already done, the file is yours to pick up. DM here or email [email protected] and we'll send it same-day.
@StamatisTWIY @andresfgg_@kerimtaray@qomplementai@hetdv@JStuerken@andustry_hq@advaith_sridhar@saudaraAI@edwardharyono_@jenandtech_@ApolloAtomics@dispatchspace@geourgkivijian
If the score reads you wrong, that gap is the thing to close on stage.
YC Demo Day, June 16
The biggest stage in startups opens in four days. The Spring 2026 batch puts 194 companies on stage - https://t.co/WQY1EvYyTC. We scored all 194 before they walk on, then split the batch into four groups and we're dropping one a day.
The method: 6 public signals, a 0 to 100 Launch Readiness Score (LRS). Search demand, social pain, competition, monetization, funding, urgency. Public data only. The outside view every investor in that room runs before the meeting.
Group 1 of 4: Agent Infrastructure. The picks and shovels. 55 startups building the rails everyone else builds agents on. Group average: 50.3.
Highest scored:
1. Kuli, 65.5, automated influencer marketing - @maradoh22
2. Armature, 63.2, product analytics for agents - @Totzenberger
3. Superlog, 63.2, self-healing logging - @superlogYC , @ArseniySvist , @nicolomagnante
4. Memory Store, 62.4, memory layer for agents - @memorydotstore , @IshitaJindal17 , @diwanksingh
5. Netter, 62.4, data ops for mid-market
Lowest on the outside view:
51. Hub xyz, 38.2, real-world AI datasets - @hubxyz, @xarmin @tim404x
52. The Company Company, 38.2, autonomous company - @thecompanyai, @juliuslip
53. General Instinct, 38.0, physical-AI deployment - @BillJiao930@Guanming717
54. Minicor, 37.7, self-healing desktop agents - @minicor_ , @faizchishtie@sahee_d
55. RentAHuman, 32.7, real-world tasks marketplace @rentahumanx, @AlexanderTw33ts
If the score reads low, it usually means the data on 6 public signals (search demand, social pain, competition, monetization, funding, urgency) is either poor or hardly available. Could be worth closing that gap on stage on June 16.
3 things the data says about this group:
1) Some are building ahead of demand, some aren't, and search alone won't tell you which. 33 of 55 sit under 500 searches a month (nobody googles "agent memory" yet). But a few have real pull: Kuli and Netter clear 11k at 80 to 94% purchase intent, and the biggest raw number, Runtime's 311k, is mostly generic "runtime" spill, not category demand. The caveat that matters most: this is public search only. Infrastructure sells through private B2B motion, so a low score can sit on top of signed LOIs, paid design partners, or institutional pre-orders the outside view can't see. If that's you, that private demand is the single strongest thing to put on stage June 16.
2) One bet, 55 ways, and from the outside every idea could have the same shape. Half literally build "for agents," 71% sit in dev tools or AI automation, median 10 direct competitors each. Strong willingness to pay, crowded competition, and weak funding, not because these founders can't raise, but because the capital already came to some of these categories in 2020 to 2022 and got absorbed, not broken out. The batch converged on one thesis and now competes with itself.
3) The strongest signal is the one that lies. Monetization scores highest across the board, people pay. But that score measures whether a market pays, not whether you can afford to win it. On the real CAC vs payback math, 14 of 49 priced startups need 12+ months to earn back one customer, and 13 of those 14 scored STRONG on monetization. So the question isn't "is there a business," it's "is this a company or a feature." That's what you get pushed on June 16.
How to use it:
- Founders in the batch: find your card, look at your lowest of the 6 signals. Those could be the questions coming. Worth prepping now.
- VCs and angels: want the full breakdown on any project, competitors, the CAC vs payback math, search demand, etc? Check on https://t.co/lM4X8lkhCH. DM us to uncover the paywalled parts as well. The reports are done, so no additional costs here. Or use Fluenta MCP to pull all reports in one batch and do a thorough analysis on each one in Claude, Cursor, etc.
- Everyone not in the room June 16: the high-LRS names are the ones who’d mostly likely get funded, and who get cloned in every local market inside 90 days. Browse the board for your business inspiration.
Tomorrow, Batch 2 of 4: The AI Workforce. The agents coming for entire job functions.
Tagging the teams above in case you want to grab your report. No hidden subscription, no signup gate - the analysis is already done, the file is yours to pick up. DM here or email [email protected] and we'll send it same-day.
If the score reads you wrong, that gap is the thing to close on stage.
Garry Tan publicly promoted 17 projects this week on Product Hunt and GitHub. We ran our 6-signal Launch Readiness Score over each. 5 landed in PROMISING. 1 sits on our Saturday Kill List threshold.
We have been tracking Garry Tan's (CEO of Y Combinator) public promotion activity. He has been heavily on Product Hunt and GitHub these last 8 days. Open upvotes, retweets, hunts. Public signals you can scrape.
We pulled the 17 projects he flagged between May 19 and May 26 and ran our standard Fluenta 6-signal Launch Readiness Score over each. Public-launch info only. Directional, not final, but useful as a "what is the most influential accelerator CEO actually betting on this week" read.
There is a pattern in how investor signal sources mature. Twenty years ago a founder's edge was a Sequoia partner's lunch schedule. Ten years ago it was the portfolio page on a VC homepage. This week it is a Product Hunt upvote feed scraped on a Monday morning. The infrastructure for tracking taste has gotten faster than the taste itself.
The 17, by LRS:
PROMISING band (LRS 60+):
→ Open Vibe - 65.9 - AI SaaS coding flow
→ Willow Scribe - 63.3 - voice-to-text Mac app
→ Superset - 61.8 - coding agent orchestration
→ Runtime - 61.5 - sandboxed agent execution
→ Airbyte Agents - 60.3 - AI agent data layer
EXPERIMENTAL band (LRS 40-59):
→ Voker - 54.4 - AI agent analytics
→ Contrario - 52 - AI-human recruiting
→ Emdash - 52 - multi-agent desktop hub
→ Mailx - 51 - email deliverability
→ Chert - 50 - iMessage AI agent platform
→ Prism - 48 - AI candidate sourcing
→ Lingo dev - 46 - AI localization
→ Ara - 46 - Mac-notch AI agent
→ Motion - 45 - AI motion-design video
→ Open Finance MCP - 44 - bank data MCP server
→ Mintlify Workflows - 41 - auto-updating docs
WEAK SIGNAL band (LRS under 40):
→ Asteroid - 33.6 - computer-use agent SDK
Two things worth noting before the breakdowns.
Open Vibe at 65.9 is the 2nd-highest LRS we have ever scored. Across thousands of ideas. 0.3 below our prior all-time high. Worth flagging where the prior record came from: a Fiverr gig last month, scored at 66.2. Not a YC graduate. Not an a16z portfolio company. A single freelancer on a gig marketplace, selling a service that compounded. The top of our all-time leaderboard now spans a YC partner's promotion feed, a Stanford accelerator, and a Fiverr listing. The rubric does not care where the idea comes from. Markets do not either.
Second: 5 of 17 in PROMISING band. Compare to Stanford Blockchain Cohort 8 we scored last week, which shipped 0 of 10 PROMISING and 9 EXPERIMENTAL. Different stage, different info depth, but the gap is real. Public-launch signal beats pre-launch tagline signal.
Universal pattern across the 17: every project needs a narrow vertical wedge to survive. Saturated horizontals get crushed. Sharp wedges compound. The rubric flagged "narrow-vertical-or-die" on all 17 of 17.
Per-project tactical breakdowns for the top 5 plus the spotlight at the bottom.
- Open Vibe (65.9). The MOAT play: not "another AI coder." Cursor, Replit, GitHub, Bolt, V0, Windsurf, Lovable, Base44 own horizontal with $355M flowing into the category. Pick ONE bottleneck (debugging visibility, project-context memory, prompt reusability) and become the daily driver for that one thing. Demand is 34/35 with 100% transactional intent at 610 searches/mo. Real budget waiting on the right wedge.
- Willow Scribe (63.3). Otter ai users are bailing in real time. r/Journalism quote: "Otter feels mega bloated and overpriced." r/podcasting, r/therapists, r/medicine all complaining. There is a recurring pattern in how knowledge-worker tools die. Evernote did not get killed by a competitor. Users got tired of it. Skype too. Pocket too. Heavy-use verticals start complaining publicly, the category trade press loses interest, and 18 months later the leader is irrelevant. The complaint threads on r/Journalism right now read like the early Evernote bailout in 2015. Which is why Willow Scribe's vertical wedge play is well timed. Wispr Flow, SuperWhisper, MacWhisper hold the Mac slot. Pick ONE workflow (medical dictation, therapy notes, journalism interview transcription) and own the templates, custom phrases, EMR integrations for that one job. Category funding is 1/10. Cold capital means clean lane for a focused entrant.
- Superset (61.8). 6,680 monthly searches is the highest demand signal in the cohort. But r/ClaudeCode skeptics are vocal: "Most 'multi-agent orchestration' is just a single agent calling a function." The wedge that survives the critique: stop selling orchestration. Sell a workflow outcome. Code review automation. Incident response. Release coordination. Orchestration is the means, not the pitch.
- Runtime (61.5). E2B is the elephant. Half of the Fortune 500. Millions of sandboxes a week. Daytona, Modal, Browserbase, Northflank also fight that fight. Category funding is 0/10. Wedge: own regulated execution. HIPAA audit trails. SOC2 policy enforcement. Financial-services exec sandboxing. E2B is general. Regulated-industry execution is a moatable sub-vertical they will not chase.
- Airbyte Agents (60.3). Tough room. Airbyte, Fivetran, Hightouch, Polytomic, Stitch, Hevo all own enterprise data plumbing. But agent-specific data context is genuinely new. Wedge: do not sell "AI data layer" (reads as Airbyte 2.0, buyer ignores). Sell agent-ready context stores for one painful job (CRM-to-agent grounding, data-warehouse-to-agent retrieval, ops-data-to-LangChain reliability). Vertical pitch reads as "the only thing that makes my pipeline reliable." Buyer pays.
The 11 EXPERIMENTAL-band projects (LRS 40-59) all follow the same playbook from our rubric: narrow vertical, defensible workflow, ship against named incumbents. Per-project incumbents + wedge in the full report.
Actually one correction worth making before we move on. We called Asteroid the "only WEAK SIGNAL." That is not quite right. Asteroid is the only entry that BARELY landed below 40. Three of the mid-band EXPERIMENTAL entries (Mintlify Workflows 41, Open Finance MCP 44, Motion 45) sit close enough to the WEAK SIGNAL line that a single bad data point could push them below. Watch the mid-band, not just the bottom.
The spotlight at the bottom:
- Asteroid (33.6). 0 monthly searches. Demand 13/35 COLD. Category funding 1/10. Browserbase, Skyvern, Anthropic Computer Use, UiPath, OpenAI, Google, Simular, OpenInterpreter all dominate already. The "computer-use SDK" tagline is the problem, not the product. There may be a real wedge in regulated back-office automation (insurance claims, healthcare admin, banking ops) where Asteroid can ship faster than UiPath. But current positioning lands close to our Saturday Kill List threshold. Sharpen the wedge or expect benchmark traffic to stay cold.
Methodology note: these scores read public Product Hunt launches + GitHub activity, not full product walkthroughs. Directional, not final. Every founder here has data we cannot see from a launch listing. Existing distribution. Team depth. Technical defensibility. Treat the LRS as one outside read, not a verdict.
For the 17 founders Garry promoted this week: the full X-Ray report for your project is already generated. Yours to claim. Each report includes:
→ Full 6-signal breakdown with reasoning per pillar (your actual sub-scores)
→ 10 named direct competitors with public pricing anchors and recent funding rounds
→ 3 business model paths with full unit economics (CAC, ARPU, gross margin, year-1 revenue projections, deal cycle, LTV:CAC)
→ 30+ ICP pain quotes pulled from Reddit, HN, IndieHackers, Quora with source URLs you can cite in your pitch deck
→ Funding momentum analysis with recent rounds in your category
→ Keyword targeting with KD scores for SEO and SEM
→ A week-by-week first-100-customers playbook with named subreddits and communities for cold reach
Plus 30 days of full Fluenta access to score variants and adjacent ideas.
No subscription. No signup gate. The analysis is already done. The file is yours to pick up. DM here or email [email protected] and we'll send it same-day.
Full collection lives at https://t.co/DfRK0nkHGo.
@garrytan, thank you for a public-signal-rich week. This list exists because your hunt feed is one of the cleanest VC signal sources online. We'll keep tracking. More projects are being added as you keep promoting.
Tagging the cohort below in case you want to claim your report.
→ Open Vibe: @WaspLang
→ Willow Scribe: @willowvoiceai · @lawrenceliuu · @_allanguo
→ Superset: @superset_sh · @FlyaKiet · @avimakesrobots
→ Runtime: @runtm_com · @gustavo_trigos
→ Airbyte Agents: @AirbyteHQ
→ Voker: @voker_ai · @tyler_postle · @alrudolph
→ Contrario: @ContrarioAI · @arya_marwaha · @soodadityab
→ Emdash: @emdashsh · @arnestrickmann · @rabanspiegel
→ Mailx: @themailx · @thamibenjelloun
→ Chert: @cherthq · @garygao · @yannaner
→ Prism: @tryprism · @theokitsberg
→ https://t.co/GuOElVwc5E: @lingodotdev · @MaxPrilutskiy
→ Ara: @xadisingh · @svemyhre
→ Motion: @motion_so · @adishj · @shivvtrivedi
→ Open Finance MCP: @appcumbuca
→ Mintlify Workflows: @mintlify · @handotdev · @hahnbeelee
→ Asteroid: @asteroid_inc · @MlcochDavid
Fluenta Research · https://t.co/DfRK0nkHGo
#ProductHunt #YCombinator #LaunchReadinessScore
Saturday Kill List - 30 May 2026
5 ideas we'd kill before you write a line of code.
All 5 came from "where ideas live" platforms. Sources that catalog what already exists, not signals of unsolved problems.
From the deadest up.
1 Native Compiler Porting Service - LRS 32.1 - GitHub Trending
0 monthly searches. Source was Microsoft's TypeScript-to-Go port trending on GitHub. The "idea" was a service to port other compilers. 17 competitors. $659M flowing into the category. The trend is Microsoft eating the market.
A trend is not a wedge.
2 Halal Beauty DTC Brand - LRS 33.5 - Tracxn SEA
1,120 searches/mo, only 8% transactional intent. Wardah, Safi, Solek, Iba, Emina, Sariayu, Make Over all sell halal beauty in Southeast Asia. Tracxn lists them. You found the list.
The list is the market. Finding it is not finding a gap.
3 Resync Revitalizing Night Cream - LRS 34.0 - Product Hunt
This is not an idea. Resync is a COSMEDIX product. It is on Dermstore right now. The Product Hunt page is a launch announcement for an existing brand. The rubric did not score an idea. It scored an inventory.
You cannot launch what is already on Dermstore.
4 Defense Drone Pre-Production Studio - LRS 34.5 - Newskart
10 monthly searches. Newskart was reporting $341M flowing into defense drones (Quantum Systems $184M, Shield AI $165M, Performance Drone Works $110M). The article you read about the funding is the same article every other founder read.
Reading the same press release is not differentiation.
5 Korea K-Beauty AI Skin Diagnostic - LRS 38.6 - Altos Ventures
80 monthly searches. Source was Altos Ventures' portfolio (they backed BPlant for $5M in January 2025). Chowis, Lululab, PerfectCorp, Revieve, Haut ai, ModiFace all run the same workflow.
Imitating a VC's bet is not investing in your own edge.
5 ideas. 5 sources. Zero of them were "I noticed a painful problem nobody is solving."
All 5 were "I looked at a list of things that exist and picked one to do."
Looking at what exists is not research. It is just looking.
The rubric finds the original every time, because the original already shipped.
A note on what the rubric cannot see.
Our 6-signal score reads public demand and supply only. Search volume. Complaint threads. Named incumbents. Funding rounds. Monetization patterns. It does not see your private edge.
If you have a distribution channel competitors cannot copy, a co-founder with industry trust nobody else can buy, a technical moat invisible from a launch page, or a customer pipeline already warm, the picture changes.
The named incumbents above are the wall. Your edge is whether you brought a ladder. The rubric scores the wall. Only you know if you have the ladder.
If you do, the kill argument is wrong. Tell us what we missed. We will re-score.
Want your idea graded on the same 6 signals before you sink a quarter into it?
$7. ~10 min. Human-readable report.
→ https://t.co/kT2HOUWu5y
More kills next Saturday.
Disagree with a call? Reply with which one we killed unfairly. The strongest pushback gets a follow-up post.
12 poorest business ideas of May 2026
Out of 4,238 ideas spotted across 74 sources in May, Fluenta scored 393 on six live market signals. The average LRS (Launch Readiness Signal) came in at 46.7 out of 100.
These 12 scored lowest, from 30.1 down to 24.4.
Full report: https://t.co/rd9sqI7rQI
Fluenta MCP is live
One API key. Your AI agent now has the full Fluenta surface inside Claude Code, Cursor, or Codex.
Stop tabbing. Start asking.
After signup (email verification, key from your dashboard):
→ Show today's fresh business ideas and new collections.
→ Show ideas with LRS above 60.
→ Find ideas in real estate. Any sector works. Search runs on context, not strict tags.
→ Show the top 5 ideas by search demand or by recent funding.
→ Compare idea X and Y on LRS metrics. Show me where the gap is.
→ Save this idea to my pipeline. Or remove it.
→ Pull the full report on the top Trending Now idea. Download as txt or md.
→ Score my idea (whatever yours is) with Fluenta X-Ray.
Or in free form, no commands: "I'm thinking about a new business. Here are the candidates I'm weighing. Which one gets me to first revenue fastest, and why? Use Fluenta MCP to check fresh ideas and compare."
Free tier is real, not a teaser. You get a daily-refreshed search slice filtered by LRS. The day's #1 Trending Now idea is fully unlocked. Full report, downloadable as txt or md, processed inline in your chat. Every metric, every link, every named competitor, every business model, real user complaints with source URLs.
You can also delegate. Set your agent to pull MCP daily and drop fresh ideas into your chat (Notion, Slack, wherever you live). Open it in the morning, the day's curated batch is already there. All on the free tier.
Paid tier is $9/mo. Full access to every idea, every sector, every collection. We are keeping it wide open while the base is growing. We will rate-limit later, before someone tries to vacuum the database in one afternoon.
For your own ideas: run the sandbox preview free. The depth is noticeably less than the paid full run. Smart move before you commit credits: download a free Top Trending report first, see the actual depth, then decide if you want the same on your own idea.
Install in 90 seconds. JSON snippet, API key, restart your client.
Docs: https://t.co/y2JyBBQT2a
We ship new functionality every week. Reply with what you want first, or what is missing. We prioritize what you actually use.
Neurocosmetics: 30.6/100.
Press calls it "the future of beauty."
Our 6 live signals say otherwise — low search growth, zero funding last 6 months, saturated SERP.
Fluenta scores every startup idea like this.
Free preview → https://t.co/DWHpZjMkBf
McKinsey, a16z, and YC are dropping hundreds of startup ideas this week. 95% of them are noise.
We got tired of the guesswork, so we built the Fluenta LRS (Launch Readiness Score) to separate the signal from the hype.
Fluenta agents ran 200+ authoritative sources to find the 15 most viable startup ideas to build today.
Fluenta LRS score based on:
🔍 Real search demand vs. Reddit "venting"
💰 Clear monetization paths
🚧 Entry ease for solo founders
Idea #1 this week: Scalable Accounting Integrator (LRS: 56.6)
Demand is Warm. Social Pain is Chronic. Funding is Hot.
We’ve unlocked the full front-to-back breakdown for Idea #1 (including the 30-day execution roadmap and CAC sanity checks) for free.
Stop reading 40-page VC reports. Go look at the data.
Link in the comments below 👇
P.S. What niche should our agents analyze for next week's report?
Why most startups don’t die from competition
There’s a myth we hear from founders all the time: “There are already too many competitors — it’s too late to enter.”
But when you actually look at real market data, the opposite is often true.
Most startups don’t fail because of competition.
They fail because there isn’t enough pain in the market.
When a problem is truly painful:
• people actively search for solutions
• companies are willing to pay
• new products start appearing
• investors begin entering the space
In that situation, competitors aren’t a red flag.
They’re proof that the market is alive.
You can often see this clearly in Fluenta idea cards.
Inside each idea there’s a Reality Check → Competition section.
At times you’ll see something like:
– 20+ competitors
– Social Pain: Burning
– Monetization: Workable
– Funding Momentum: Hot
That usually means one simple thing: the market already hurts — and it already pays. 🔥
The most dangerous ideas usually aren’t the ones with competitors.
They’re the ones where the card looks like this:
Demand: Cold
Pain: Low
Funding: None
That’s when there simply is no market. 🥶
The real risk isn’t competition.
The real risk is building something nobody actually needs.
Inside Fluenta idea cards, these signals are laid out clearly:
Pain → Demand → Monetization → Funding
Come and check out each trending idea for yourself:
👉 https://t.co/DfRK0nkHGo
Enjoy 👌
#startups #entrepreneurship #startupideas #founders #marketresearch
McKinsey, a16z, and YC are dropping hundreds of startup ideas this week. 95% of them are noise.
We got tired of the guesswork, so we built the Fluenta LRS (Launch Readiness Score) to separate the signal from the hype.
Fluenta agents ran 200+ authoritative sources to find the 15 most viable startup ideas to build today.
Fluenta LRS score based on:
🔍 Real search demand vs. Reddit "venting"
💰 Clear monetization paths
🚧 Entry ease for solo founders
Idea #1 this week: Scalable Accounting Integrator (LRS: 56.6)
Demand is Warm. Social Pain is Chronic. Funding is Hot.
We’ve unlocked the full front-to-back breakdown for Idea #1 (including the 30-day execution roadmap and CAC sanity checks) for free.
Stop reading 40-page VC reports. Go look at the data.
Link in the comments below 👇
P.S. What niche should our agents analyze for next week's report?
I just unlocked a @BLAST_L2
Not only I have earned $5 for staking $2k for half a year, but my staked 0,5 eth became 0,45
Yield is a bi**ch ����😂😂
Well f***ng done $BLAST
And it’s live
Try to check prices, funding rounds, or even add SecondLaneBot to your community to prompt and share data right in the middle of your discussions
I just joined @wen_exchange Early Access to claim $WEN Pre-Token Airdrop 👀
WEN is the No.1 NFT marketplace on @Blast_L2 with native yield and zero trading fee.
Use this ref link for extra tokens👇:
https://t.co/ECWuZ5de24
https://t.co/d2Fx584Lbe
Lastly, Wen Early Access is now LIVE 🎉
This is only for real early comers before the mainnet launch 👀
Join the early access and be eligible for the $WEN Pre-Token.
Early Access🔗: https://t.co/zLYu8ZeS3J
𝗢𝗻𝗹𝘆𝗕𝗹𝗮𝘀𝘁 𝗶𝘀 𝗯𝗼𝗿𝗻 𝘁𝗼 𝗽𝗿𝗼𝘃𝗲 𝘆𝗼𝘂𝗿 𝗲𝗮𝗿𝗹𝘆 𝗰𝗼𝗻𝘁𝗿𝗶𝗯𝘂𝘁𝗶𝗼𝗻 𝗼𝗻 𝗕𝗹𝗮𝘀𝘁 𝗟𝟮 💥
Go to our website to check if you are eligible for “Proof-of-contribution” NFT collection mint and upcoming $OB airdrop.
Blaster goes Pew Pew Pew! 🔫 The first and only place to trade, earn, and launch tokens on @Blast_L2!
Join the @BlasterSwap Early Access to instant claim $BLSTR Pre-Token Airdrop!
https://t.co/1m3i2KciA4
https://t.co/SbfsQZlbST
Blaster is ready to Blast!
We are stepping into the @Blast_L2 Big Bang Competition and announcing the Early Access Airdrop - Phase One!
https://t.co/9sq2m3CLI0