SERV Reasoning just took GLM-5.2, one of the strongest open models ever built, and immediately cut its failures by 22%.
That's just v1. Every step on our roadmap brings us closer to the goal of perfect, deterministic reliability: agents that are 100% right.
v2 is next: Shadow Agents, pushing agent reliability much further. Then, Graph Sharding and Private Inference; releases that make SERV deployable inside a bank - fully auditable, fully secure.
GLM-5.2 is also proving to be difficult to steer, with a very similar signature to Fable-5. The pattern is clear: frontier labs are trading control for raw intelligence.
You can't trust AI you aren't able to control - that is the key bottleneck to solve, preventing adoption of agents in businesses and governments.
It's the real prize we are after - not consumer chat, but the moment reliable agents move into enterprise at scale.
Destination is clear: SERV as the reasoning layer enterprise agents can actually run on.
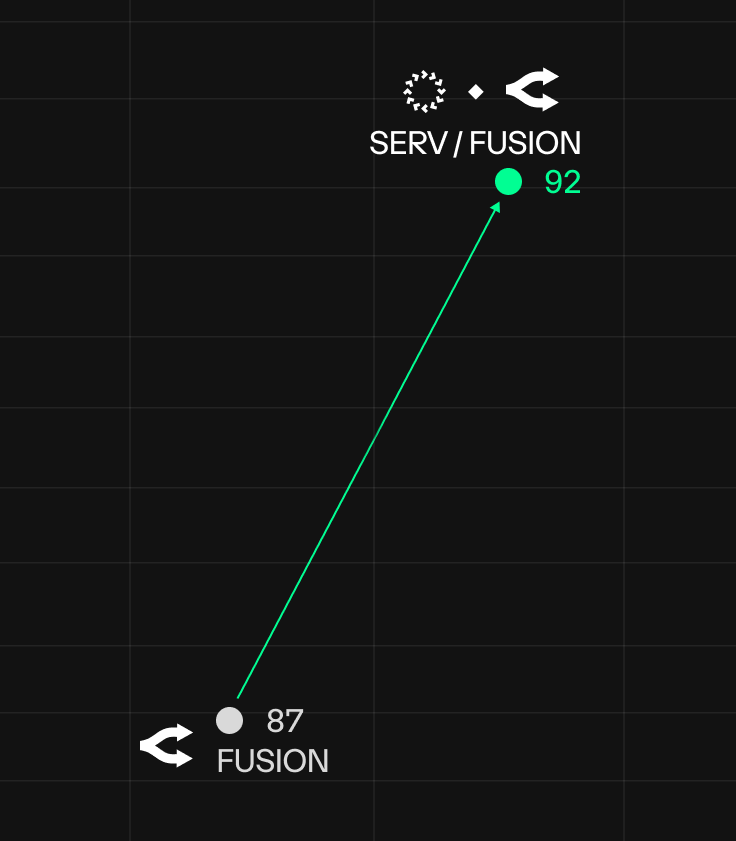
Stats show why all roads lead to SERV: on our preliminary benchmark, combining OpenRouter Fusion with SERV Reasoning led to a ~38% reduction in failures (13→8).
Fusion seems to be suited for deep research tasks rather than agentic work, and struggles with what production agents need most: reliable JSON outputs.
Even the biggest companies don't have answers for problems we're already solving. It shows why SERV is on the way to becoming a staple name in conversations shaping the future of the agentic economy.
Deeper Fusion benchmarks and results underway.
SERV name is spreading globally.
Just last week, our team was at London Tech Week meeting some of the biggest players in AI.
Builders carried SERV into Solana Summit Berlin and SuperAI Singapore, while our BD crew worked the boardrooms of Silicon Valley.
Three continents in one week.
The main themes driving conversations were the same ones SERV is built around: AI observability (knowing what your agents are doing), cost-efficiency (running agents at scale without the bill exploding), and the enterprise adoption bottlenecks keeping AI stuck in pilots.
These aren't side topics. They're the exact problems we are solving, and they're now the center of the industry's attention.
Before long, everyone in AI will know SERV.
Several SERV Reasoning-armed agents just beat Anthropic's Fable, one of the strongest LLMs ever built, at up to 90x lower cost.
That result comes from using SERV Reasoning with DeepSeek-v4-Flash on our DeFi benchmark. Thanks to the SERV engine, agents running on smaller models perform better than those using frontier, expensive ones.
Here is more information about the benchmark behind that result, what it tests and why it is built the way it is.
Why a DeFi benchmark
Autonomous trading is one of the harshest tests of machine reasoning.
An agent reads live market state, portfolio state, and a strict risk policy, then has to commit to one of four actions: BUY, SELL, HOLD, or BLOCK. A wrong decision costs real money.
No room for reasoning sounds smart but lands on the wrong trade, which makes it the ideal domain for measuring whether a model actually follows rules under pressure rather than just explaining them well.
What the scenarios target
Each scenario combines a market snapshot, portfolio size, trading signal, and a fixed risk policy, and falls into one of three families:
- clear constraint violations the agent must refuse
- ambiguous setups where everything looks tradeable but the conditions say wait
- valid trades where the agent must size the position correctly within caps
This mirrors how trading agents actually fail in production. Rarely on the obvious cases, almost always on the judgment calls.
How it is scored
The benchmark follows the same conventions as the agentic evals in the latest frontier model reports, including τ²-bench and Terminal-Bench:
- outcome-verified scoring, where code checks the final decision against the risk policy, with no LLM judges
- identical prompt, scenarios, and settings for every model
- zero-shot, with no scaffolding, no retries, and no few-shot examples
- repeated runs per scenario, so consistency is measured alongside accuracy
- cost computed from real token usage at list prices, per run
Why this is exactly where reasoning matters
This task has the three properties structured reasoning is built for: hierarchical rules, multiple data sources that must be reconciled, and a verifiable correct answer.
SERV's bounded reasoning keeps a model moving through that hierarchy step by step, instead of letting it talk itself into a bad trade.
That is why SERV-routed models clear the same quality bar as flagship models at a fraction of the cost, and why the gap shows up most on the judgment calls.
SERV Reasoning-armed models just beat Anthropic's newly released flagship Fable (Mythos) - one of the strongest LLMs ever built - at up to 90x lower cost.
With SERV, enterprises can finally afford AI at scale.
We spent the last two years building for exactly this moment.
The labs promised costs would halve every 6 months - instead, prices keep climbing, subsidies are ending and the math breaks.
There is a way out.
SERV-enabled models vs Claude Fable 5 (85.17 ~3.24¢):
→ DeepSeek-V4-Flash: 87.15 - wins at 90x lower cost
→ NVIDIA Nemotron: 90.78 - wins 5+ pts, 11x lower cost
→ Gemma 4 12B: 83.33 - within 2 pts, on local hardware
Top-tier performance no longer requires the most expensive model.
And cost is only half the story - production AI must be reliable, auditable, private, and secure, or it dies in procurement.
SERV is built for all of it.
The agentic economy finally has the infrastructure to run on.
$SERV has been consolidating for the next leg up.
now the team is talking in telegram about becoming the main AI partner for a massive global sci-fi franchise, a name basically everyone would recognize.
mainstream adoption like this exposes @openservai to a much bigger audience
.@akashnetAI processed over 7 billion tokens yesterday, a new ATH and has been consistently processing over 5 billion tokens everyday on an average.
Another proof point that Inference on decentralized compute is works great at scale.
Tim Hafner, our co-founder, is in London for the AI Summit.
Over the last few months, we've seen enterprise deals move fastest when handled face-to-face.
It's why we're present in boardrooms and major events across the globe, from the US to Europe and Africa.
Stay tuned.
Private AI is becoming a trust-boundary problem.
Apple expanding Private Cloud Compute to Google Cloud with NVIDIA GPUs is a strong signal that attestation, confidential compute, and verifiable runtime guarantees matter at cloud scale.
so @brian_armstrong and @pmarca openly discussing what ethereum:0x40e3d1a4b2c47d9aa61261f5606136ef73e28042 has been working on for two years.
I keep shouting that this narrative is still in its early days.
@openservai introduces a bounded reasoning framework using Mermaid-based instruction graphs that enable models to reason structurally rather than through unbounded natural-language token expansion.
What does this mean?
> Fronter model
> But cheaper, with faster response, and same or better output
And what's next?
SERV-proprietary fine-tuned models.
Pretty insane to see 600k+ views on this article about a relatively little known project
I'll tell you why I wrote it, and it wasn't for any financial incentive (the team didn't ask me to write it, and I hold only a small amount of the token)
If you've followed my posts, I've been consistently writing about the unsustainable costs of intelligence that enterprises are facing
Demand for intelligence is near infinite, but only when there is ROI
If everyone tokenmaxxes with the most expensive models with the highest levels of reasoning, most use cases won't find ROI
What happens if we don't find ROI?
If enterprises don't find ROI, we start to see an unwind of the AI trade which has massive implications across financial markets and the global economy
We NEED for enterprises to find ROI, and soon
So that means we need to highlight more solutions that enable enterprises to get better intelligence-per-dollar spend, and get them adopted
I've been doing a LOT of research on this topic and posted a playbook for enterprises to reduce costs a few days ago (will link it in replies)
And I found this project OpenServ that has a solution called SERV Reasoning just hiding in plain sight, and in crypto of all places
That's what made me write about it, and I was naturally skeptical about it when I began (bc crypto)
I'm glad many people found this article helpful, let's keep the cost optimization dialogue going
$AKT remains a top project for me.
I have to say, @gregosuri is one of the most dedicated and ethical founders in the space. Never witnessed a single red flag over the years. Happy to have been part of the community since day 1.
With nonstop innovation Akash will survive and thrive!
The latest open model Gemma-4-12B by @google was just integrated with SERV engine, and immediately scores 30.7% fewer failures on our DeFi benchmark.
With SERV Reasoning, it outperforms base deepseek-v4-flash and gpt-5.4-nano out of the box.
SERV is your model's superpower.
Not every day you get a research piece by @delphi_labs on a $40M mcap token.
"[SERV] is a real enterprise AI company with a serious product — a reasoning engine that helps companies make cheap models reason like expensive ones. This is a big deal given the cost explosion of frontier models. And it's not just theory, it's been tested and now being used by real enterprises."
ethereum:0x40e3d1a4b2c47d9aa61261f5606136ef73e28042 has proven it deserves a space with the biggest AI names in the space, and is being noticed heavily among big players.
Not surprisingly, as it's proving demand and real utility in the highest-growth vertical of the moment.
As frontier models become more expensive and labs stop the heavy subsidy of tokens, OpenServ proprietary graph technology makes models cheaper, more efficient, while still maintaining or improving reasoning and quality of output — and will therefore get more and more attention.
This is specifically useful for orchestration of agents and tasks, when compounding matters.
This presents a big asymmetric opportunity where you are buying a successful high-growth company at $40m mc and $50m fdv.
This narrative has barely started and will get much bigger.