🏖️ Headed to St. Pete Beach for VSS!
Presenting new work Monday morning with Phil Guan, Ian Erkelens & Oliver Cossairt @RealityLabs.
Come say hi!
📄 Abstract: https://t.co/nUqtHAemAn
🔬 More from Meta Reality Labs:
https://t.co/rc2OwIUoLQ
https://t.co/kjqb3bdq0A
#VSS2025
🎉 New paper out!
We show training improves motion categorization but doesn't reduce (or even worsens) misperceptions—explained via model combining efficient coding + implicit categorization + increased encoding precision
https://t.co/YQUKEKlneQ
So in 2007, physicists wrote a paper that made the headlines: according to their calculations, human coin flips aren’t 50/50 - more like 51/49.
Why is that, and did students in Amsterdam really flip 350,000 coins to find out?
🧵
👀Just released in PNAS with Meta @RealityLabs. Laziness is unexpectedly central to gaze in everyday life. Mobile eye tracking dataset covers Pokémon GO, LEGO, driving, shopping, and more.💃Game changer for AR & AI research! w/ @MichaelProulx@tsmurdison +
https://t.co/x98umWoPmo
We've open-sourced the egocentric eye tracking dataset from our recent papers — via @Facebook@RealityLabs GitHub.
~26 hrs of user gaze and head movement data across 9 everyday tasks: driving, shopping, LEGO, Pokemon GO, + more.
https://t.co/AiyFHj0k4L
h/t @tsmurdison
I’m very excited to share that my graduate work is now online in @ScienceMagazine today!
With generous help from my mentor @yuji_ikegaya and my amazing teammates, we investigated a top-down pathway for volitional heart rate regulation!
https://t.co/AoYwZ4J1Z0
All-day AR would benefit from AI models that understand a person's context & eye tracking could be key for task recognition. Yet past work - including our own https://t.co/WFtNCTrcJB - hasn't found much added value from gaze in addition to computer vision & egocentric video 2/
Got Butterflies in your Stomach?😵💫I am super excited to share the first major study of my postdoc @visceral_mind! We report a multidimensional mental health signature of stomach-brain coupling in the largest sample to date 🧵👇https://t.co/THzlnraMW5
Once the input state space is well-aligned with human action & vision, and appropriate models that can represent long-term dependencies are used, we believe that multiple problems in contextual AI may be solved convergently by a single (gaze-based) visual foundation model. 6/
New paper alert! @RealityLabs
Eye gaze in everyday life contains multi-scale temporal dependencies across objects (1-7 fixations into past, depending on task). Akin to natural language.
Key to foundation models for visual understanding in mixed reality
https://t.co/PF5PHiZguY
But object-part-based image segmentation is just starting to gain traction, and universal segmentation (segmenting and labelling all image pixels) is still a challenge. So this is one major bottleneck for aligning the model input state space with that of human active vision. 5/
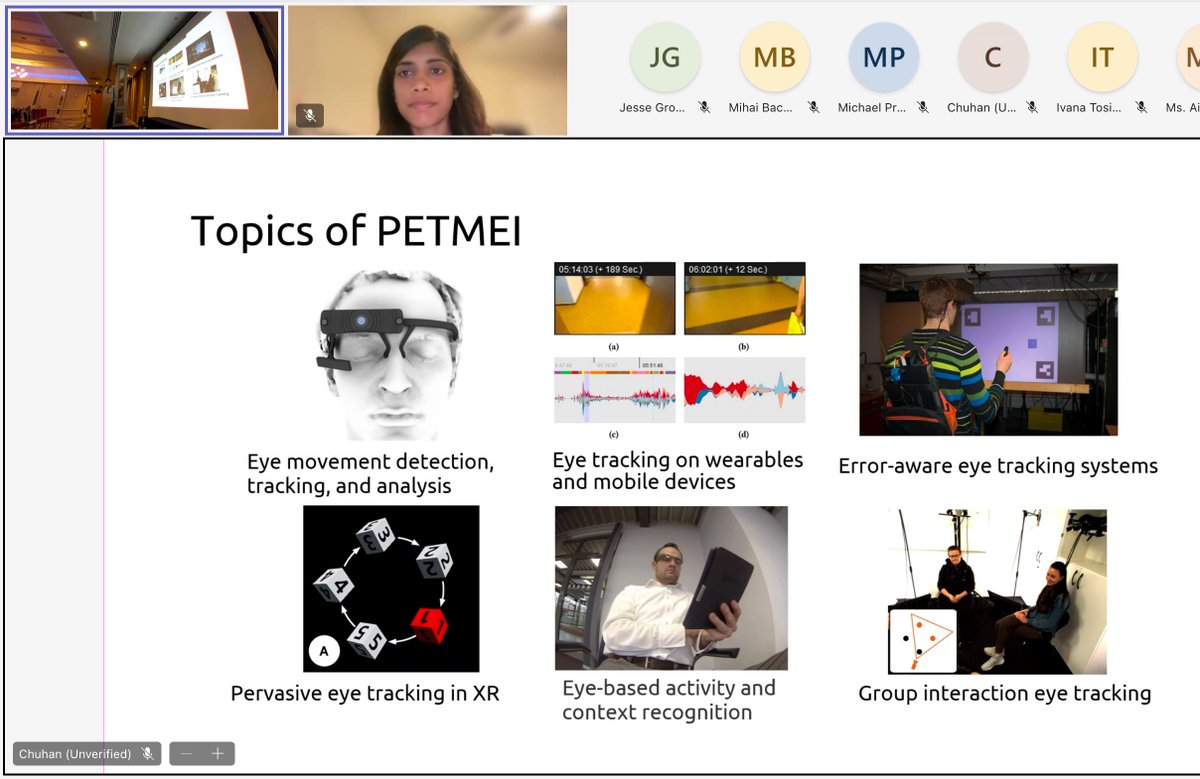
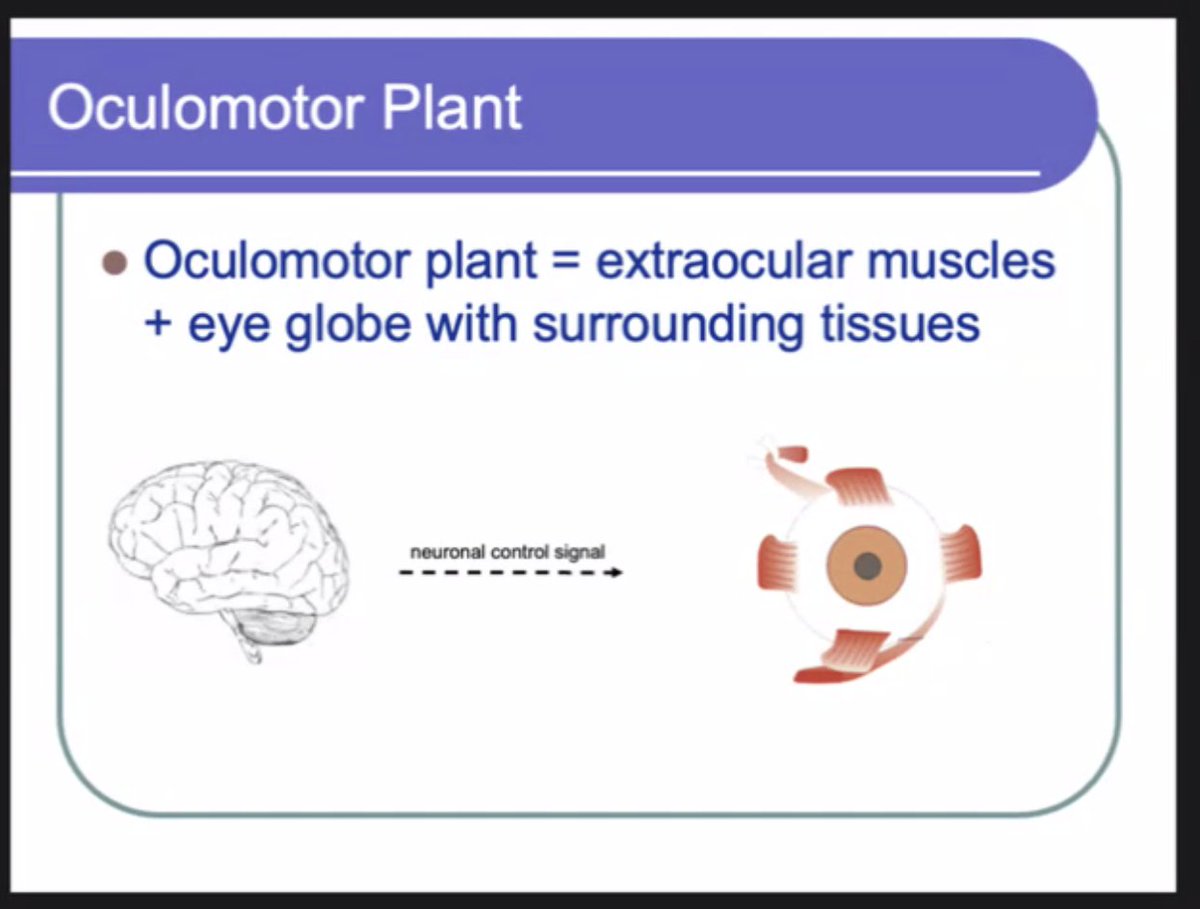
Paper Session 1: Visual Attention @ETRA_conference 2024 just started. @olegkomo from @RealityLabs and @txst is now presenting their paper on "Per-Subject Oculomotor Plant Mathematical Models and the Reliability of Their Parameters" at #ETRA2024.
Paper: https://t.co/oqppbK2ITT