With the help of #seedance 2.0, I’m finally able to bring the world of cyber knights and beasts to life.
The character designs were created back in 2023 using ComfyUI, and have been adapted to fit better together in this new world.
Merry Christmas! 🎄 #VibeCoding
This single-file web app is created and refined entirely with AI.
Download it and play with your own photos: https://t.co/1m6bI48C22
I originally built Lexigen for myself and it has worked pretty well, so I’m sharing it in the hope that it’s useful to others as well.
👉 Free download on the App Store:
https://t.co/9JOiaAUNNP
AI is great for language learning, but most AI chat apps don’t help you retain what you learn.
Flashcards work, but making good ones is tedious.
So I built Lexigen: an AI-powered flashcard app that automatically generates definitions and usage examples for the words you save.
Lexigen runs on Apple’s on-device Foundation Models instead of a cloud API
Pros:
• No subscriptions or accounts
• Better privacy by design
Cons:
• Limited supported devices and languages
• Strict safety guardrails prevents card generation occasionally
I'm noticing that due to (I think?) a lot of benchmarkmaxxing on long horizon tasks, LLMs are becoming a little too agentic by default, a little beyond my average use case.
For example in coding, the models now tend to reason for a fairly long time, they have an inclination to start listing and grepping files all across the entire repo, they do repeated web searchers, they over-analyze and over-think little rare edge cases even in code that is knowingly incomplete and under active development, and often come back ~minutes later even for simple queries.
This might make sense for long-running tasks but it's less of a good fit for more "in the loop" iterated development that I still do a lot of, or if I'm just looking for a quick spot check before running a script, just in case I got some indexing wrong or made some dumb error. So I find myself quite often stopping the LLMs with variations of "Stop, you're way overthinking this. Look at only this single file. Do not use any tools. Do not over-engineer", etc.
Basically as the default starts to slowly creep into the "ultrathink" super agentic mode, I feel a need for the reverse, and more generally good ways to indicate or communicate intent / stakes, from "just have a quick look" all the way to "go off for 30 minutes, come back when absolutely certain".
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).
o1 is the first model I tested that was able to solve this ‘world’s hardest logic puzzle’ correctly, albeit with a lot of guidance and steering from the human.
Tried @runwayml's Camera Control with a photo of me as a baby👶
The model failed to orbit around objects when I gave it artistic paintings, but it deals with photos of people relatively well. #AI#2Dto3D
3 ultimate questions:
1. Existence: why something instead of nothing? (Nature of substance)
2. Events and dynamics: how does anything happen? (Nature of space-time and quantum probability)
3. Emergence: complexity, awareness/feeling/consciousness, possible illusion of will …
There are only 3 great scientific questions:
1. What's the universe made of?
2. What's life all about?
3. What is intelligence?
There are interesting sub-questions:
1.1 What's dark matter and dark energy?
1.2 how do you get "it from bit" to paraphrase John Wheeler
1.3 what is the nature of time?
2.1 is the emergence of life an intrinsic property of the universe?
2.2 how does complexity spontaneously form?
3.1 is the emergence of intelligent behavior an intrinsic property of the universe?
3.2 how does intelligence spontaneously form? (which is why learning is so fascinating)
At the core of all of these questions is the nature of information and computation.
These 94 lines of code are everything that is needed to train a neural network. Everything else is just efficiency.
This is my earlier project Micrograd. It implements a scalar-valued auto-grad engine. You start with some numbers at the leafs (usually the input data and the neural network parameters), build up a computational graph with operations like + and * that mix them, and the graph ends with a single value at the very end (the loss). You then go backwards through the graph applying chain rule at each node to calculate the gradients. The gradients tell you how to nudge your parameters to decrease the loss (and hence improve your network).
Sometimes when things get too complicated, I come back to this code and just breathe a little. But ok ok you also do have to know what the computational graph should be (e.g. MLP -> Transformer), what the loss function should be (e.g. autoregressive/diffusion), how to best use the gradients for a parameter update (e.g. SGD -> AdamW) etc etc. But it is the core of what is mostly happening.
The 1986 paper from Rumelhart, Hinton, Williams that popularized and used this algorithm (backpropagation) for training neural nets:
https://t.co/f52IcDNitR
micrograd on Github: https://t.co/GaTd16jRnB
and my (now somewhat old) YouTube video where I very slowly build and explain:
https://t.co/EPGG6kd5Yz
I tried @LumaLabsAI's image-to-video AI with one of my old AI artworks, and this is what I got.
Interesting.
There’s still lots of room for improvement, I would say.
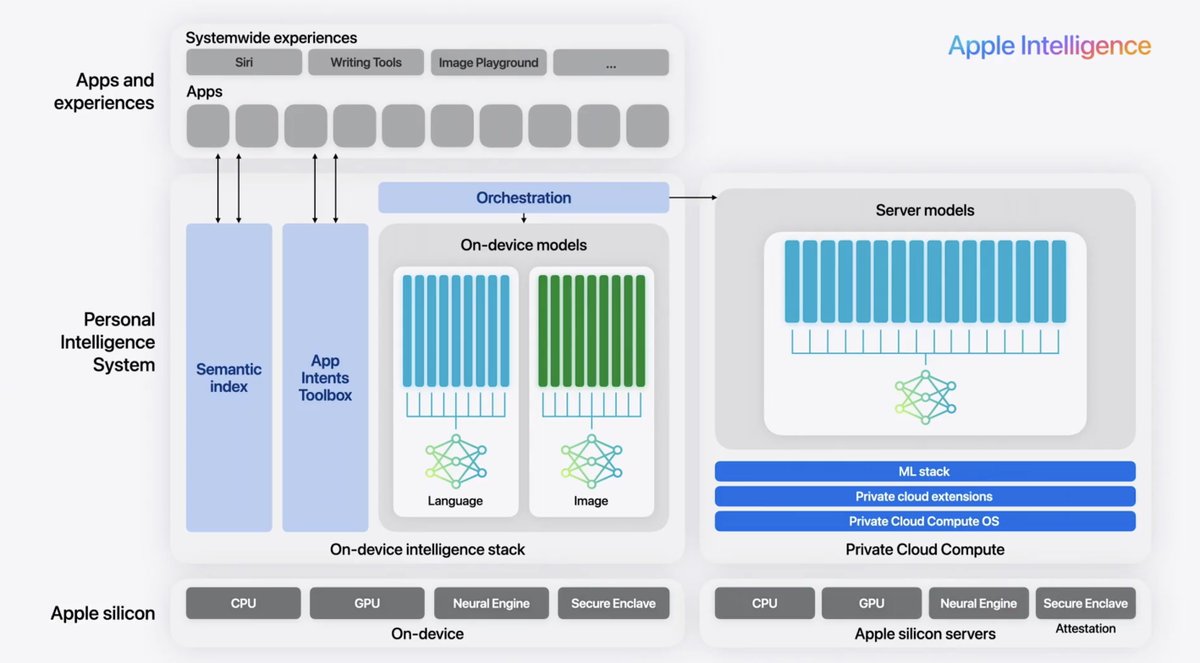
Marketing speak to terms you already know:
semantic index -> embeddings
app intents -> function calling
on device language model -> 3B fine tuned LLM w/ included LoRA adapters
on device image model -> diffusion model w/ included LoRA adapters
orchestration -> Siri
Neural Engine -> Apple's GPU
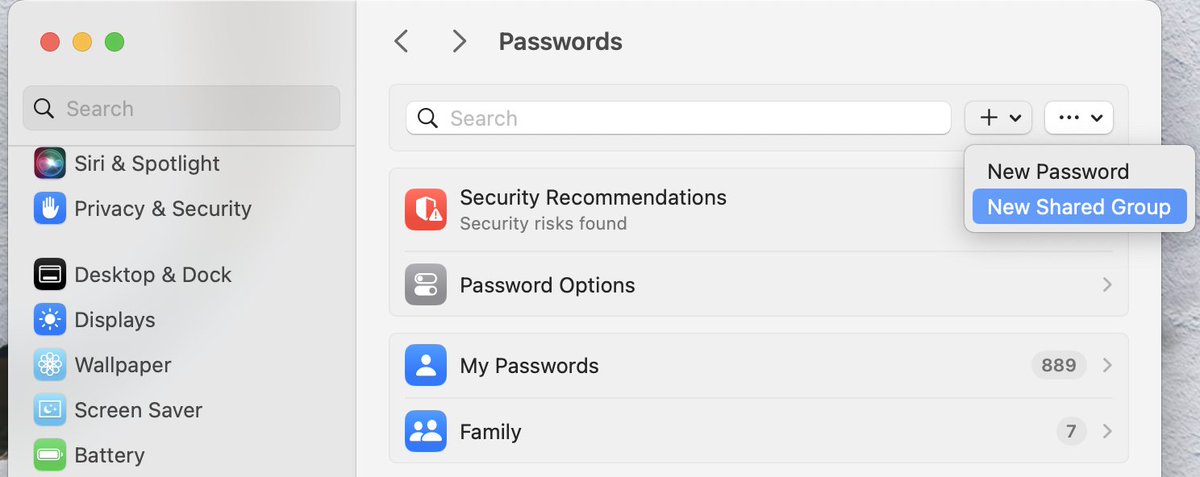
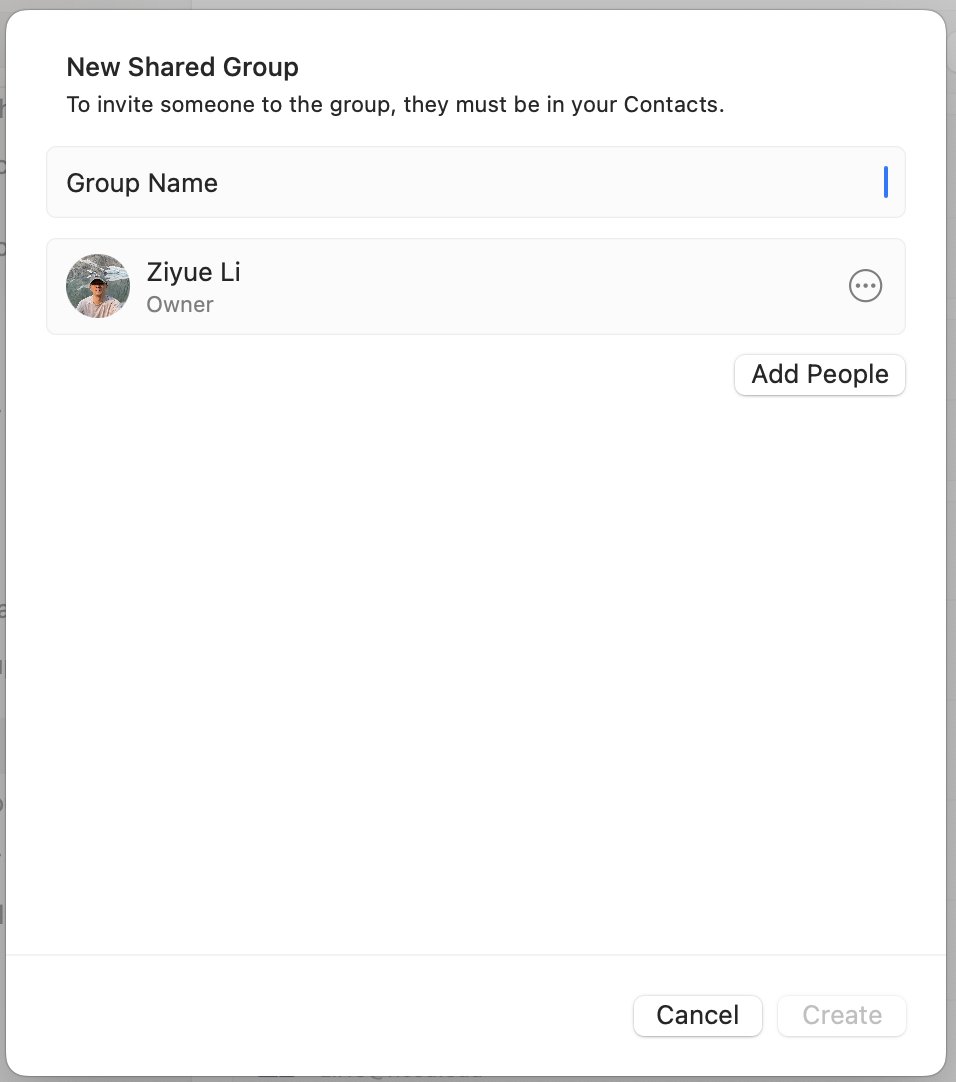
Just found out about this hidden feature today. Did you know that you can now share passwords with people on Mac?
It works with iPhone with #iOS17, iPad with #iPadOS17, or a Mac with macOS #Sonoma.
https://t.co/KPH4tnorPC