To stretch the analogy further: your “landlord” can see everything happening inside your home. How you arrange furniture, what visitors you have, etc. And they have every incentive to use this info to commoditize your business advantage.
Own, don’t rent
GLM-5.2 is Fully Open, Frontier Intelligence Belongs to Everyone
Today, the sudden restriction of certain frontier models is deeply regrettable. At a time when access to frontier models is abruptly cut off for non-technical reasons, we are even more convinced of one thing: science should be global.
The path to AGI (Artificial General Intelligence) must never be enclosed by high walls. We have always believed that AGI should be the cornerstone for all of humanity to collaboratively explore the boundaries of intelligence and solve complex challenges, rather than a privilege monopolized by a few rules and subject to revocation at any moment. In the face of external blockades and restrictions, our attitude is one of radical openness. Frontier intelligence must remain open-source, accessible, and buildable, serving every dedicated developer.
GLM-5.2 is Zhipu's most capable open-source model to date. It not only supports a truly usable 1M context window but also maintains a continuous lead in the independent completion of long-horizon tasks, providing solid foundational support for building complex agent applications. It also continues to be our main engine for creating the strongest domestic coding model.
Tonight at 5:21—at this special moment—GLM-5.2 will officially be available to all GLM Coding Plan users (including Lite / Pro / Max). The API will also go live next week.
A step closer to frontier intelligence for everyone.
The future of AI is open, and it is for the people.
ModelKey: GLM-5.2
MiniMax M3 is live on Fireworks. Day-0, fastest endpoint for the MiniMax series.
→ Top open-weight model on the Artificial Analysis index
→ 512K context, native image + video input
→ MSA sparse attention: 9× faster prefill, 15× faster decode
→ Priced at parity with M2.7
Long-horizon agents, full-repo understanding, multimodal coding all in one model.
Learn more: https://t.co/j0RcJxgY8K
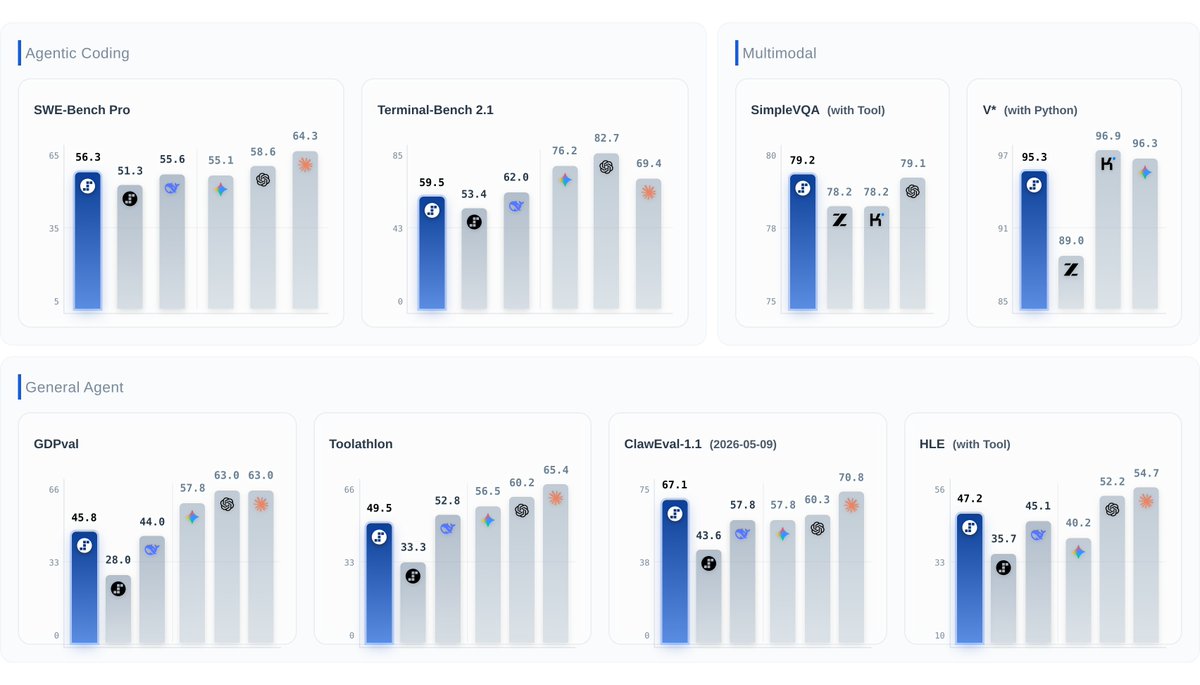
⚡️ Step 3.7 Flash is here: The new frontier is agent efficiency.
#1 ClawEval-1.1 (67.1), #1 SimpleVQA Search (79.2), #2 SWE-PRO (56.3), 95.3 on V* Python. Open weights under Apache 2.0.
Built for agentic, coding, search, and multimodal workflows — balancing speed, cost, and reliable execution.
- 400 TPS. 198B sparse MoE, ~11B active. 256K context, 3 reasoning levels.
- Understands UIs, charts, docs, images — then writes code or calls tools to act on what it sees.
- Web + visual search reaches further: more sources, deeper follow-up.
- Reliable tool use — less drift, fewer broken toolcalls. 98%+ on τ²-bench across all difficulty levels.
- Works with Claude Code, KiloCode, Hermes Agent, OpenClaw, and protocols like MCP.
- Runs locally on Mac Studio M4 Max, DGX Spark, AMD AI Max+ 395.
GitHub: https://t.co/kqlZkVIRHv
HuggingFace: https://t.co/qqceCrgPiw
GGUF: https://t.co/rR6XrnymWG
ModelScope: https://t.co/wney6Tzvqy
API: https://t.co/RvHWzRG7Fu
Blog: https://t.co/BxDiajiQ5G
Deep dive into how Composer 2 & 2.5 was cooked, and the cool infra @cursor_ai and @FireworksAI_HQ built together to power RL for it
Huge thanks to maestro @ellev3n11 and @sonyatweetybird for a fun conversation. Available on your favorite podcast platform
Nathan's @cursor_ai team didn't prompt-engineer their way to Composer 2.5. They trained it. The massive RL program runs RL rollouts on Fireworks, alongside production inference.
"Comment 🔥 to see my prompt" → may work for influencers (in 2025)
Training your own model → the only way to sustain a competitive moat in 2027+
Learn more → https://t.co/ezpDabw8mS
I’m often asked why fine tune in 2026:
1) Precise control over your product UX not achievable with just prompting
2) Better cost/speed/quality tradeoff: pay fraction of Mini price while getting Pro quality for your use case
Frontier labs heavily do 1&2 for their own apps. But they want you to pay $ for the most expensive API
We believe everyone should have access to customization at frontier. https://t.co/W3dkEoCTSn
Why are four of the top 10 trending vendors AI inference platforms?
Companies are getting selective about which model handles which task, and routing tokens accordingly.
Read more from @arakharazian at @tryramp: https://t.co/E5MAJQfsES
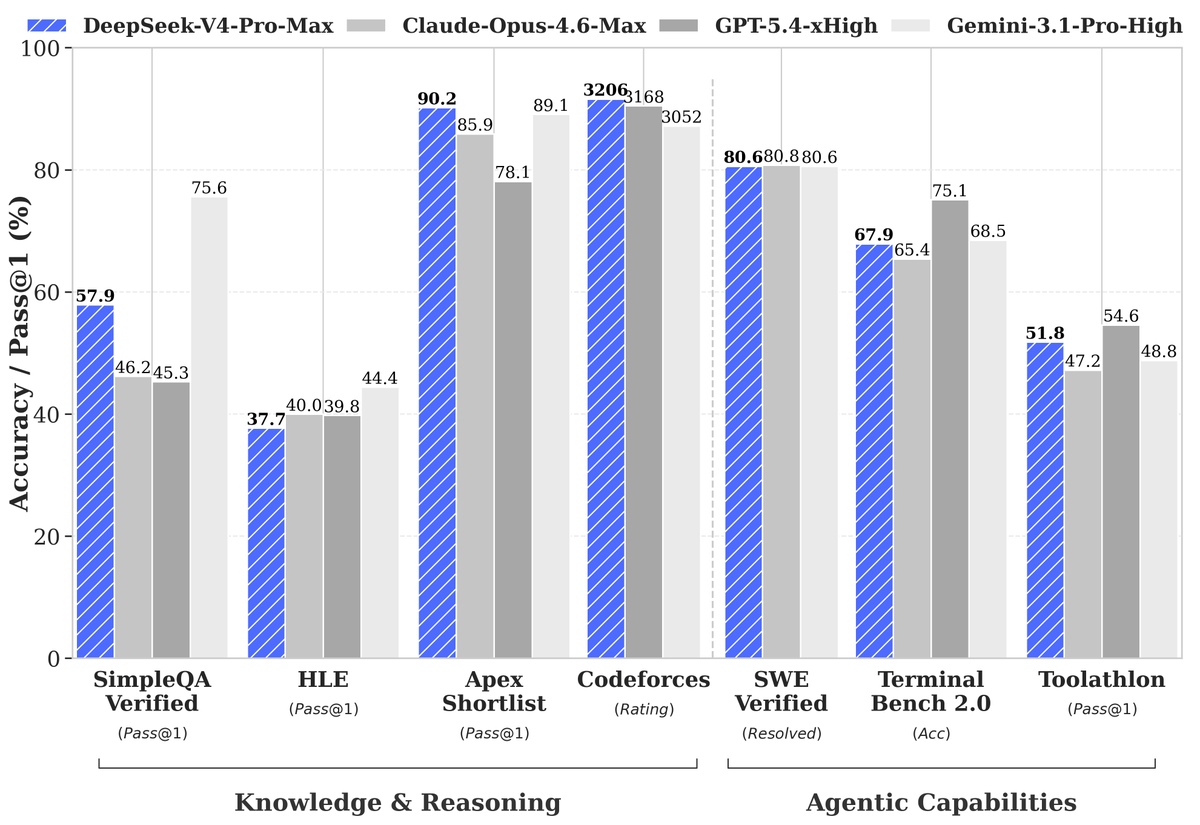
We didn’t ship DeepSeek V4 on Day 0 like we always do. Why? We love speed at @FireworksAI_HQ , but quality >> speed.
Running our extensive evals, we found even the official reference model code producing corrupted outputs. When we tested over the weekend, all endpoints except official DeepSeek API had these issues.
After 2 days of extensive debugging with @deepseek_ai , @sgl_project and @vllm_project communities, the issues are fixed and we’re proud to serve DeepSeek V4 Pro in all its glory.
Check the full story 👇
DeepSeek V4-Pro is live on Fireworks:
→ Frontier-class coding and reasoning, open-weights
→ 1M context standard, MIT licensed
→ $1.74 / $3.48 per 1M tok
Get started now → https://t.co/BKrdxniuyR
🔥 I'm thrilled to welcome George Hu as President of Fireworks AI! 🔥
When George and I first met a year ago, I said to him – we are too small for you. But today, we are ready! We have come a long way to build out the next phase of our company.
When the seven cofounders started the company, we wanted to honor our roots in PyTorch; torch carries the fire. We want the fire of AI to serve people everywhere. We named our company Fireworks to move the industry forward to be AI-first.
Three and a half years in, we have grown substantially. Today, we process 30 trillion tokens a day, the biggest inference provider outside of the frontier labs’ APIs. We got to this impact by relentlessly defining what frontier inference is. It is the control we give to all application developers to customize their own model, deliver magically fast experience, and scale with maximum efficiency. We have built multiple product lines with Fireworks Training, Fireworks Inference and the best open models on one platform.
We are accelerating to the next phase of scaling – enabling customers everywhere to experience the power of their own private models on Fireworks. This growth demands a world-class business leader, a unicorn, a one-of-a-kind. George is this leader. He is one of a very small number of people who have scaled not one but two iconic software companies. He worked alongside @Benioff at @salesforce , where he helped grow revenue from $100M to $5B+, and then did it again with @jeffiel at @twilio , driving nearly 10x growth in five years.
George, thank you for your trust in me and the Fireworks team. I admire the conviction he brings to @FireworksAI_HQ , the same conviction I've had with the other cofounders since Day One. Let's build something generational!
We're still early. The companies winning with AI are the ones who own their intelligence and their differentiation. Our job is to make that possible for every company in the world.
And if your conviction is as strong as George’s and mine, we're hiring.
Let’s bring the 🔥!
When I saw our team's evals of Kimi 2.6, I thought "ok, things are gonna get interesting now".
This is the first open-weight model that plays like a top-class agentic model. Watching it go through ambiguous and meticulous chained tool work successfully puts it squarely in the wheelhouse of Opus 4.6. We're looking at an open weight model, but with much cheaper direct inference provider pricing. For a subclass of our eval set, it's outperforming GPT 5.2. We're about to undergo a gigantic industry shift.
Open weight is no longer for those who fine tune, those who want on-prem. It's an actual, reliable option for it's quality/price/latency profile for difficult agentic work.
It's not perfect. It's token hungry, relatively slow, and can get stuck in “thinking loops". But those are things we can engineer around. For value it is, and how it positions itself against major labs, this is a dramatic day for open weight models.
We sprinted as a team and worked closely with @FireworksAI_HQ to get this to our customers on day 0. No one should wait to try out a change like this. Try it yourself and tell me where it's working for you.
We're delighted to announce that MiniMax M2.7 is now officially open source.
With SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%).
You can find it on Hugging Face now. Enjoy!🤗
huggingface:https://t.co/ApWrahIl3o
Blog: https://t.co/gAxeFsNdW4
MiniMax API: https://t.co/1dgbMx0Q7K
Your data is your moat. Build best AI. Let us handle the infra
8B or 1T params
1k or 1M context
LoRA or full param
SFT, DPO, GRPO or custom
Fully managed or composable SDK
Fireworks Cloud or BYOC
It’s Fireworks Training: full flexibility, no compromises
What will you build?
GLM 5.1 is live on Fireworks!
SOTA for agents and coding:
→Plans and executes multi-hour workflows without falling apart
→Planning, executing, testing, and refining over hundreds of rounds to deliver real, production-grade results.
Go build something: https://t.co/zwmsd1g4tT
Introducing GLM-5.1: The Next Level of Open Source
- Top-Tier Performance: #1 in open source and #3 globally across SWE-Bench Pro, Terminal-Bench, and NL2Repo.
- Built for Long-Horizon Tasks: Runs autonomously for 8 hours, refining strategies through thousands of iterations.
Blog: https://t.co/hmyDe4Nel3
Weights: https://t.co/CuUjXcPKJD
API: https://t.co/fz6reja4fb
Coding Plan: https://t.co/Nk8Y98HNhU
Coming to https://t.co/WCqWT0qCQb in the next few days.