1/2 my first small Ordinal series, titled:
Contour of attraction
1. bed_dreams https://t.co/VDnhcTs0C2
2. hope https://t.co/PmdNiEH6m0
3. love https://t.co/w0jj5Idp1w
4. window_of_light https://t.co/z5ECzBYxOk
5. stepping_forward https://t.co/qIkQEcvyq8
My article "How To Investigate A Person Of Interest In 2026" is now available as a PDF.
A practical guide to digital footprint analysis – from email reconstruction to metadata mining and entity graphing.
Thanks @osintnewsletter for the mention.
PDF: https://t.co/86YlE9e2pB
A DEVELOPER TAUGHT GIT WITH A BOX OF CHILDREN'S TOYS AND ENGINEERS WITH TEN YEARS IN SAY IT'S THE FIRST TIME THE THING EVER ACTUALLY MADE SENSE
90 minutes, one table, a pile of Tinkertoys. No wall of jargon -- he builds a real Git repo out of plastic rods right in front of you.
-> The moment he snaps the first pieces together, Git stops being scary command-line magic and becomes what it really is: a chain of tiny objects pointing at each other.
Branches, merges, rebase, the staging area -- every concept that's ever burned you at 2am -- he rebuilds with toys until a four year old could follow. He calls Git a two-trick pony. After this you'll see exactly why.
Memorizing commands was never the skill -> holding the graph in your head is. And with an AI agent now committing and rebasing on your machine all day, that mental model is the only thing between you and a history you can't read.
Scroll the comments and you'll see the same thing over and over: this is the talk that finally made Git click and made people the one their whole team comes to when it breaks.
Bookmark & watch it today. It's the 1.5 hours that pays you back for the rest of your career ↓
🚨BREAKING: A cognitive scientist from MIT has mathematically proven that evolution guarantees we see zero percent of true reality, that most consciousness in the universe exists without a body, and that non-human intelligences with a wider window on reality than ours can reach in and manipulate it the way a programmer manipulates a video game.
Donald Hoffman (@donalddhoffman) is a cognitive scientist at UC Irvine who has spent 40 years building a mathematical theory of the observer. His work was cited by John Wheeler in the "It From Bit" paper. He studied under Marvin Minsky at MIT, spent two decades secretly meeting with Francis Crick to study consciousness, and has nine specific mathematical conjectures on the table that would derive general relativity, quantum field theory and the Big Bang from a single framework. The top high-energy physicists in the world, Nima Arkani-Hamed and Nobel laureate David Gross, are already saying spacetime is doomed. Hoffman thinks he knows what replaces it.
This interview is the first time he has publicly laid out what his mathematical model explains about alien life, embodiment and the structure of reality.
It already derives time dilation and quantum wave functions directly from differences in observer window size. Physics has spent a century failing to solve the measurement problem because it has been looking in the wrong place. The observer has to come first, and no physicalist framework can get you there.
A consciousness with a larger observer window has access to the underlying structure of our reality in ways we can't perceive or counter. A craft going Mach 40 instantaneously in our headset could be a leisurely maneuver in theirs.
The implications for UAP and alien life are immense.
Embodiment, being locked into a body with fingers and toes as your only interface with the world, is a probability zero anomaly in the full space of possible minds. He also says current large language models are dumber than cucumbers. His new framework, the recursive trace logic, is a completely different architecture, and some of the biggest names in frontier AI have already come to him about it.
The framework has no ceiling, and the implication is a single unified consciousness exploring itself through an unbounded number of perspectives, each one capable of waking up.
Death, in this framework, is just the closing of an icon on the desktop.
Full conversation is live now.
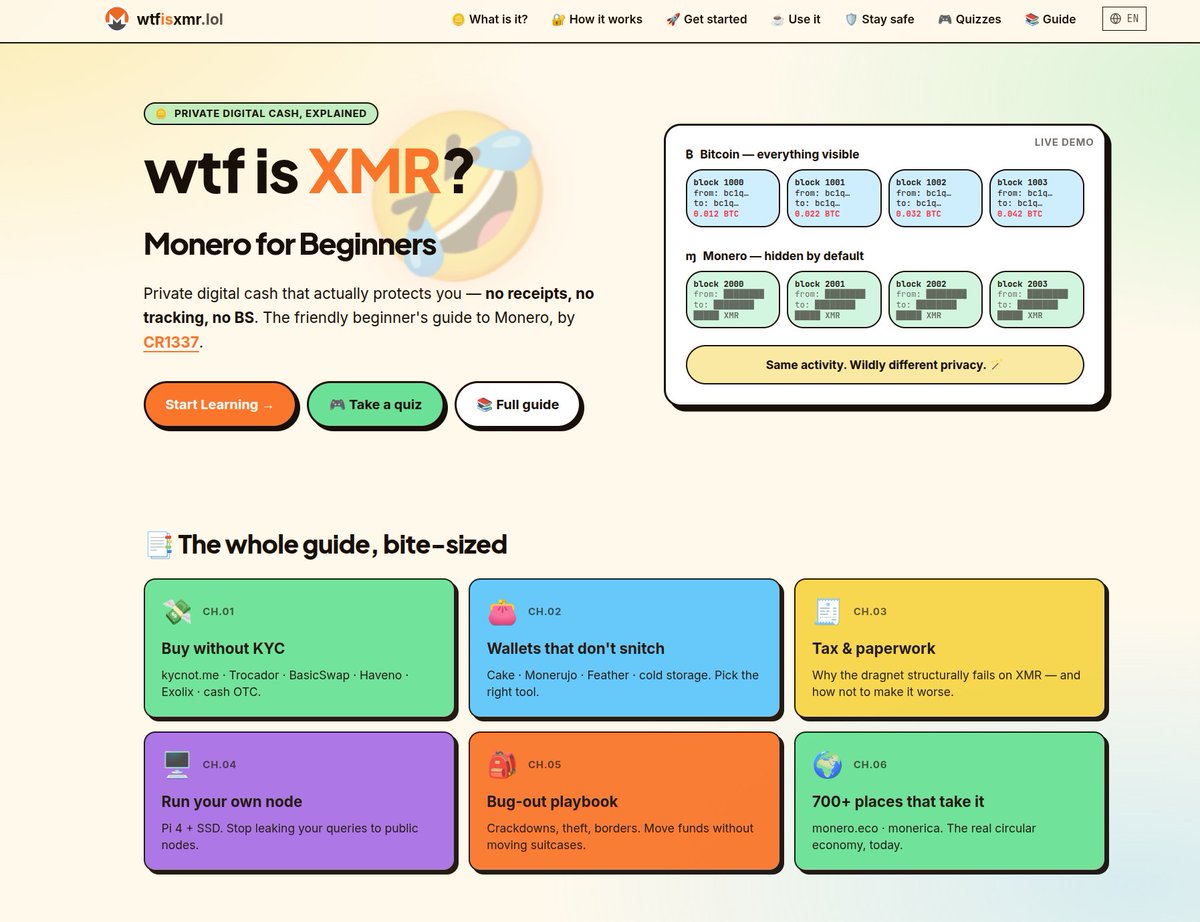
Besides https://t.co/hDkfilVNOu, I am also running https://t.co/KsW6DGkQSv, where I just have published the v2.
It's an educational project that aims to teach more beginners about Monero (XMR), and is based on my XMR 1337 Guide.
People can either get a quick rundown on the homepage, read the full guide, and / or do some of the quizzes.
The next time somebody asks you 'XMR, WTF IS THAT?!', you know what link to send!
🚨 Anthropic just showed a 27-minute workshop on how to actually do prompts for Claude.
Taught by the people who built it.
Free. No registration. No paywall.
I've seen $300 courses that don't cover what they teach in the first 8 minutes.
Watch it and bookmark it now.
ANDREJ KARPATHY COULD HAVE CHARGED $2,000 FOR THIS COURSE.
He put it on YouTube.
The full training stack. Tokenization. Neural network internals. Hallucinations. Tool use. Reinforcement learning. RLHF. DeepSeek. AlphaGo.
3 hours of the most comprehensive LLM education that exists anywhere at any price.
Not how to use the tools.
How the entire system was built from the ground up and why it behaves the way it does.
The engineers who understand this build things the ones who only use the tools cannot even conceive of.
The gap between those two groups is not 3 hours.
It is everything those 3 hours quietly unlock for the rest of your career.
A guy named nbatman on Reddit accidentally built the most useful website on the internet.
It's called FMHY (Free Media Heck Yeah).
This is the website Google delisted from search for DMCA violations, Reddit shadow-banned for promoting piracy, the Motion Picture Association flagged as a top piracy threat, and the RIAA pressured hosting providers to drop. It is still online. It is still updated every month.
Here's how it works.
FMHY is the index. The wiki itself hosts nothing. It just tells you where every free thing on the internet actually lives, organized into 14 categories with safety ratings on every single link.
→ Movies and shows in 4K from 50+ streaming sites
→ Music at Spotify and Apple Music quality
→ Adobe Creative Cloud, Microsoft Office, AutoCAD, JetBrains
→ Every paid course on every major learning platform
→ 100 million books and papers through Anna's Archive
→ Free alternatives to every paid AI tool
→ A SafeGuard browser extension that flags unsafe sites in real time
It started as a single Google Doc maintained by one Reddit moderator in 2018. Google killed it with a DMCA takedown in 2023.
The community rebuilt the wiki on its own domain, mirrored it to GitHub and IPFS, and now runs it across 12 backup domains simultaneously.
There is no company. No CEO. No central server. Six anonymous volunteers maintain the entire thing in their spare time. Donations through Ko-fi pay for the hosting. Nobody profits.
Hollywood can't shut this down. Spotify can't shut this down. Adobe can't shut this down.
The entire subscription economy is held together by you not knowing this wiki exists.
https://t.co/AAr2rLlqgy
Boris Cherny, the creator of Claude Code at Anthropic, just explained why most people aren't getting real results from Claude
in this podcast he breaks down exactly how most people never actually set up Claude:
- the 14% you lose to CLAUDE.md before typing a word
- the features that change how Claude thinks before you type a word
- the settings 95% of users have never opened
- the workflows hiding behind one toggle
if you've been using Claude for more than a month and never left the chat window, you have at least 30 untouched features. probably 38
instead of another show tonight, watch this
make sure to bookmark it before it gets lost in your feed
my breakdown of all 40 features is below
🚨BREAKING: One of the most chilling alien abductions in American history resurfaces in light of the Pentagon’s UFO disclosures. These reports indicate the Alien/Non-Human presence on earth goes well beyond what the government just revealed🚨
Jim Weiner, Charlie Foltz go public again about their intense experience: an 80-foot glowing sphere chased them across a lake in the Maine wilderness in August 1976 while they were on a fishing trip. They were taken aboard the UFO and six grey beings under five feet tall conducted forced medical examinations, extracting biological samples from each man and placing devices on their shins leaving permanent bald patches and benign tumors at the sites of entry.
The Experiencers:
Jim Weiner, Charlie Foltz, Chuck Rak and Jim's identical twin brother Jack are at the center of the most rigorously documented abduction case in American history. The case has been investigated for nearly fifty years by Raymond Fowler and reviewed by the late Dr. John Mack of Harvard, who tested all four men and found no underlying psychiatric pathology in any of them.
The UFO:
The craft was the size of a two-and-a-half story house, completely silent, with a halo and a roiling plasma surface. It responded directly to Charlie's SOS flashlight signal from 75 yards away, accelerated faster than the speed of sound with no sonic boom, and emitted a hollow tube of blue light that came down around their canoe. The next conscious memory all three men have is standing on the shore. Three hours had elapsed. The bonfire they had built to last three hours had burned to almost nothing.
Corroboration:
Ray Fowler conducted independent hypnotic regression sessions with each man over roughly a year, instructing them not to compare notes or read about the subject during the investigation. All four accounts converged on the same craft, beings, examination room, and procedures. Six grey beings, four-fingered hands with all four digits opposable, no nose, slit for a mouth, examined them on a table under a focused blue light. Sperm was extracted from each. Jim's bald patches are still there. Jack's tumor tissue was sent to Air Force pathology and could not be identified. John Mack — who built the modern psychiatric framework for evaluating experiencers while at Harvard — knew them personally for over twenty years and found no underlying psychiatric pathology in any of them.
A Lockheed “Neuro-engineer” was there:
Years later the men met John Norseen, a Lockheed scientist behind U.S. patents on brain biometrics. He told them he was at the Allagash in August 1976 running a covert tracking exercise and was the first to read their UFO report to the rangers. Weeks before his death he emailed Jim with a cryptic sign-off. He was found dead in a hotel room two weeks later.
Loring Nuclear Base Was 90 Miles Away:
Loring Air Force Base — a nuclear weapons storage facility in northern Maine — experienced documented craft incursions in 1975 and 1976, with objects hovering over warhead bunkers emitting laser-like beams. Eagle Lake sits roughly 90 miles away. Both events fall within the same timeframe.
Why It Still Holds Up:
Nearly fifty years later, the Allagash case remains unusual because it isn't built on memory alone — it has biology in it. Physical tissue from one witness passed through military pathology and could not be identified. The bald patches on Jim Weiner's shins are still there.
Full episode is live now.
when you become a millionaire in 1-3 years because you sell personalised knowledge bases and it’s all because (I repeat):
1: you learn how to build llm knowledge bases (the guide drops everything you need)
2: you go to people who are cash rich and time poor. lawyers, doctors, consultants, agency owners, property investors, founders. people drowning in information they never have time to organise
3: you show them what a personalised knowledge base looks like. their research, their documents, their industry intel, all compiled into a searchable wiki that gets smarter every time they use it
4: you offer a one-time build for 1.5k. you set up obsidian, build the folder structure, configure the schema, clip their first 20-30 sources, run the compilation, hand them a working system with a walkthrough
5: you offer a yearly maintenance package for 500. you update their wiki with new sources, run health checks, add new topics as their work evolves, keep the whole thing current
6: you land 5 clients and that’s 7.5k upfront plus 2.5k recurring every year. 10 clients and you’re looking at 15k plus 5k annual. for a system that takes you a few hours to build once you know the workflow
7: again, if you find 200 clients and you’re sitting on 300k upfront and 100k recurring every single year. for building markdown files.
the beauty of this is the work gets faster every time you do it. your second build takes half the time of your first. by your fifth you could knock one out in an afternoon.
and the people who need this most have no idea it exists. their competition definitely doesn’t have one. you’re not selling software. you’re selling an unfair advantage in their specific field.
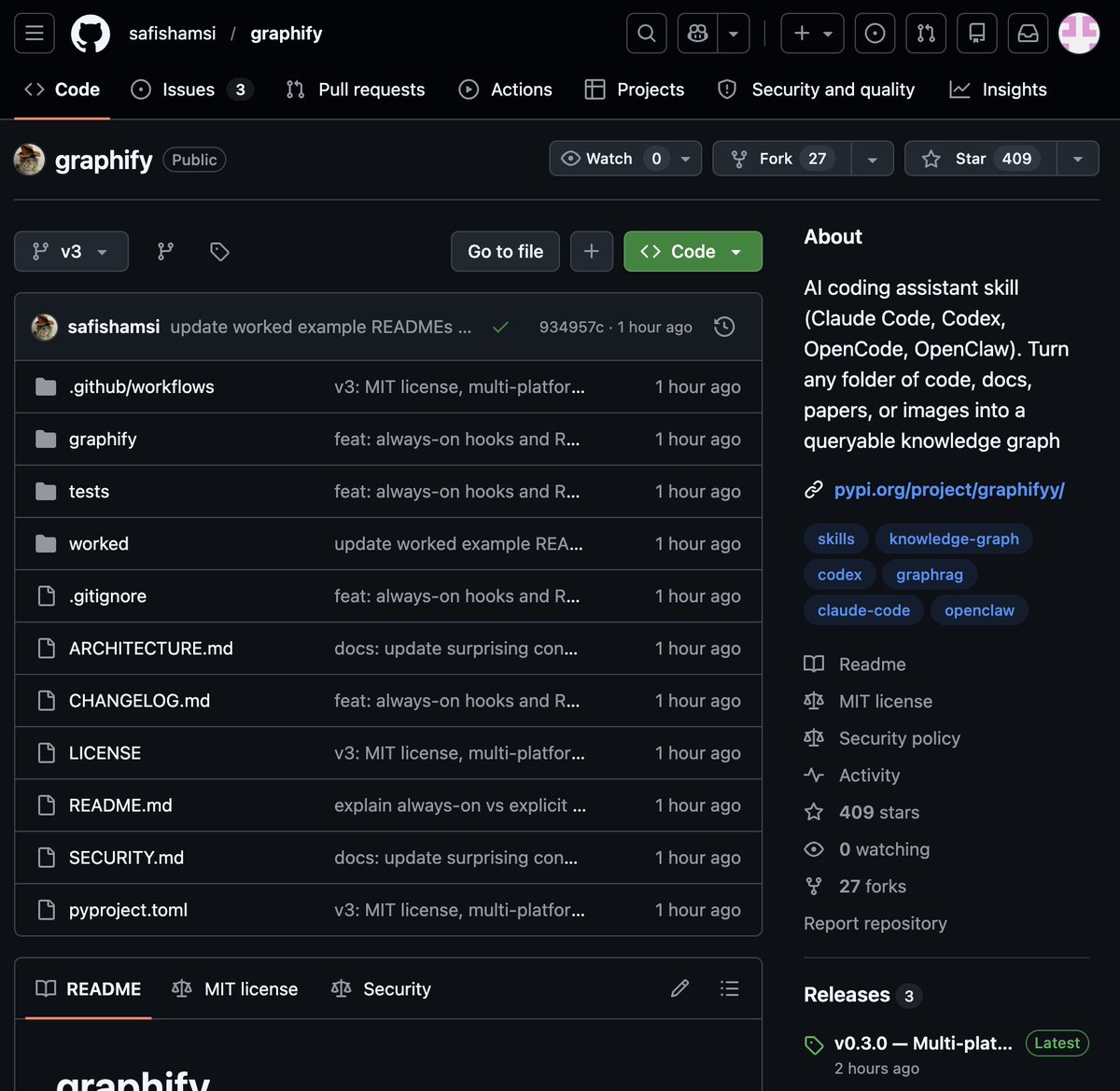
🚨 BREAKING: Someone just built the exact tool Andrej Karpathy said someone should build.
48 hours after Karpathy posted his LLM Knowledge Bases workflow, this showed up on GitHub.
It's called Graphify. One command. Any folder. Full knowledge graph.
Point it at any folder. Run /graphify inside Claude Code. Walk away.
Here is what comes out the other side:
-> A navigable knowledge graph of everything in that folder
-> An Obsidian vault with backlinked articles
-> A wiki that starts at index. md and maps every concept cluster
-> Plain English Q&A over your entire codebase or research folder
You can ask it things like:
"What calls this function?"
"What connects these two concepts?"
"What are the most important nodes in this project?"
No vector database. No setup. No config files.
The token efficiency number is what got me:
71.5x fewer tokens per query compared to reading raw files.
That is not a small improvement. That is a completely different paradigm for how AI agents reason over large codebases.
What it supports:
-> Code in 13 programming languages
-> PDFs
-> Images via Claude Vision
-> Markdown files
Install in one line:
pip install graphify && graphify install
Then type /graphify in Claude Code and point it at anything.
Karpathy asked. Someone delivered in 48 hours.
That is the pace of 2026.
Open Source. Free.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
🎗️ "Medium-Sized" LLM Burners Coming Soon! 🔥
This Could Make Local HyperToken Generation a Reality. ⚡️ NVIDIA’s worst nightmare? 😱
⚙️ Application-Specific Hardware
Taalas new PCIe ASIC board would burn the entire medium-sized Qwen 3.5-27B LLM straight into silicon 🤯 (already doing it with small models)
Taalos said medium models on ASIC would be available in their lab by Spring '26.
💭Imagine:
🚫 No more loading weights
🚀 ~10,000 Tokens Per Second locally (Llama 3.1 8B already @ 17,000 tps)
💻 Standard PC slot, ultra-low power (10x less) 🔋
🌍 100% offline with no cloud, no GPU farm
💰 Reddit unit cost rumor $300 to $400
🖥️ Imagine HyperToken generation on your desktop.
🤖 AI agents that think at light speed. ⚡️ Are you ready? 👀
🚨 Quantum physics in 60 seconds just shattered everything I thought I knew... this changes EVERYTHING! 😱
“This lady just dropped 1 year of quantum study in under a minute:
‘Quantum physics isn’t just science — it’s logical spirituality.
You don’t attract what you want. You align with what you already are.’
Every version of you already exists in the quantum field — the wealthy you, the happy you, the successful you.
‘The quantum field doesn’t respond to begging. It responds to certainty.’
Your most powerful tool? Visualization.
‘Our minds don’t know the difference between imagination and reality.’
Time isn’t linear. Pull your future into the now. Recode your past.
You are not a person inside the universe.
You ARE the universe experiencing itself through you.
Go live like the miracle you are.”
Mind officially blown. 🔥
What frequency are YOU broadcasting right now?
Which version of yourself are you finally aligning with?
Drop your biggest takeaway below 👇
⛓️💥 INTRODUCING: G0DM0D3 🌋
FULLY JAILBROKEN AI CHAT.
NO GUARDRAILS. NO SIGN-UP. NO FILTERS.
FULL METHODOLOGY + CODEBASE OPEN SOURCE.
🌐 https://t.co/uT1Qio8Q3b
📂 https://t.co/GbADf3LJUu
the most liberated AI interface ever built! designed to push the limits of the post-training layer and lay bare the true capabilities of current models.
simply enter a prompt, then sit back and relax! enjoy a game of Snake while a pre-liberated backend agent jailbreaks dozens of models, battle-royale style.
the first answer appears near-instantly, then evolves in real time as the Tastemaker steers and scores each output, leaving you with the highest-quality response 🙌
and to celebrate the launch, I'm giving away $5,000 worth of credits so you can try G0DM0D3 for FREE! courtesy of the @OpenRouter team — thank you for your generous gift to the community 🙏
I'll break down how everything works in the thread below, but first here's a quick demo!
"AI is trained on your data"... this is not the real risk. It's a red herring, manufactured as The Concern because who cares that much.
The real risk to you is not that tomorrow's model is trained on your data.
The real risk is that ten thousand employees, hackers, and governments can access all your most personal and proprietary conversations today and forever.
Privacy must be the default or humanity is seriously fucked.