(🧵6/6) I enjoy building (random) side-projects like this and am always open to feedback on my projects, so let me know what you think! Check it out: https://t.co/UMG67WoTnw
(🧵1/6) I like to read the news and its part of my daily routine to read several different news sources a few times a day. Until someday, I was thinking, why do we read all news chronologically? Wouldn't it make more sense to read it as causation and results?
(🧵5/6) Fully built within @vuejs and @nuxt_js, and fully hosted on @CloudflareDev using Workers, D1, R2, Workers AI + Gateway and Workflows. To keep it running all day, seems to be about 125k tokens in and 220k out for the AI use. Not sure about the cost yet.
(🧵1/6) My go-to stack to build my web apps with is only using @nuxt_js + @CloudflareDev. Full-stack and easily deployed to Cloudflare Workers, where I pay $5/month for everything I need (D1, R2, AI, vectors, logging, gateway, workflows, etc.)
(🧵5/6) Having both front-end and back-end in one codebase has helped me in particular, since it easier to provide context to my coding agents. I also connected Cloudflare, Nuxt and Nuxt UI MCP servers (in VS Code) to help out.
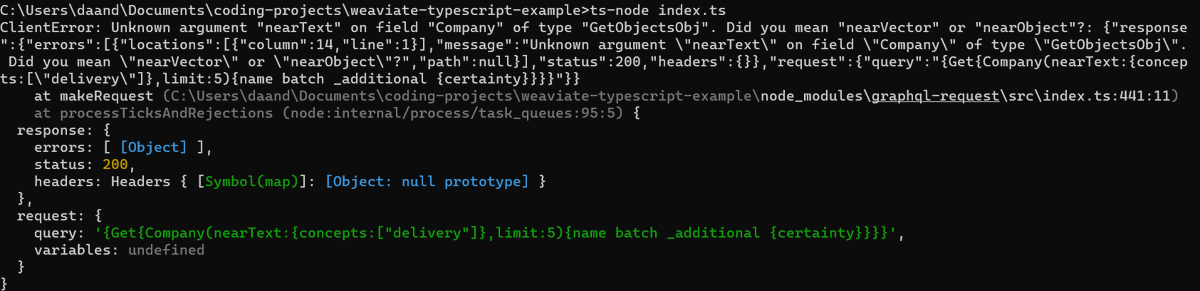
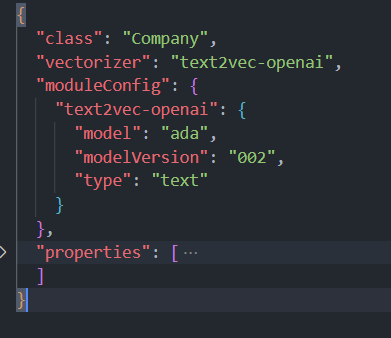
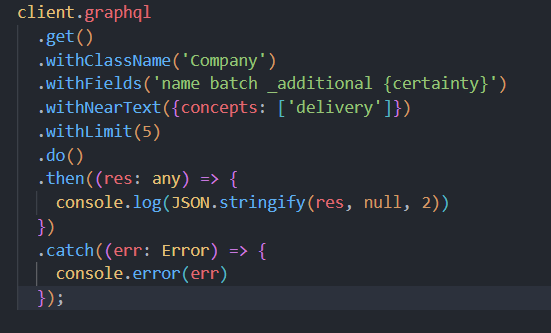
(🧵1/7) This weekend I started exploring vector databases, following @fireship_dev's video, so I created a @weaviate_io database filled with all @ycombinator companies! That allowed me to create this fun visualisation of the relatedness of companies throughout all the batches. 🚀
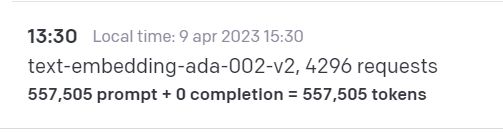
@weaviate_io My OpenAI usage was mainly for the initial text2vec to populate my data, not for the searches (although as I am testing now, on my PC compared to my laptop over the weekend, the whole option of 'nearText' doesn't seem to work 🤔)
@devorein@weaviate_io I am a bit confused about why OpenAI marks my embeddings with equal tokens and prompts because the company descriptions should be longer pieces of text and therefore use fewer tokens. But this happens under the hood in @weaviate_io, so maybe they can explain?
@devorein@fireship_dev@weaviate_io@ycombinator During all my testing and development, I paid max. $1, and specifically for the Y Combinator dataset, it's probably ~$0.20. Search results are okay but could be better. I think this mainly happens because not all companies have proper long-form descriptions