We are building AI technologies to empower humans, and this requires awareness of human reliance. Our latest work measures human cognitive offload using our workflow induction toolkit.
Beyond showing the accuracy of our measure, we find that high reliance isn't inherently harmful. When users bring intentional engagement and genuine task understanding, AIs can facilitate human learning ✨
New work on Multi-Agent Computer Use (MACU).
The future of computer-use agents lies in multi-agent systems that combine planning, coordination, and parallel execution.
Paper: https://t.co/6rkHjTR9J0
Webside + Code: https://t.co/Ng7Bwz3feh
MACU introduces a manager agent that decomposes tasks into a dynamic directed acyclic graph (DAG) of subtasks, dispatches parallel subagents, and continuously updates the plan as new information arrives.
Across OSWorld, Online-Mind2Web, WebTrailBench, and Odysseys, we see performance improvement by 4.7–25.5%, achieving better test-time scaling, and solving long-horizon tasks that single-agent systems often fail to complete.
On Odysseys, MACU reduces task completion time by 1.5×, showing that multi-agent coordination is a powerful path toward more capable and efficient computer-use agents.
See a more detail thread by @kohjingyu.
Computer use agents are slow and brittle. The fix isn’t just stronger models, but also deploying them as multi-agent systems.
MACU is a general Multi-Agent Computer Use framework that consistently lifts success rates by 3.4-25.5% and is up to 1.5x faster on long-horizon tasks.🧵
New work: a simple and general multi-agent computer use framework. It uses a manager to plan and re-plan by creating a task DAG, with subagents for parallel execution.
It improves success rate across benchmarks, and substantially improves efficiency on long-horizon tasks.
Computer use agents are slow and brittle. The fix isn’t just stronger models, but also deploying them as multi-agent systems.
MACU is a general Multi-Agent Computer Use framework that consistently lifts success rates by 3.4-25.5% and is up to 1.5x faster on long-horizon tasks.🧵
LLMs refuse ambiguous queries that look harmful but aren't. Can they recover once users clarify, while staying safe? Our new interactive multi-turn benchmark measures both.
🚨 Turns out: not both at once.
Sub-agents are a promising inference-time scaling primitive:
• Expand an agent's working memory
• Divide-and-conquer hard problems
• Solve problems faster with parallel execution
But how do we train a model to best take advantage of sub-agents and make sure we get these benefits?
Very excited to release RAO: Recursive Agent Optimization.
RAO is an end-to-end reinforcement learning approach for training LLM agents to spawn, delegate to, and coordinate with recursive copies of themselves (that can themselves spawn other agents) - turning recursive inference into a learned capability.
1/10
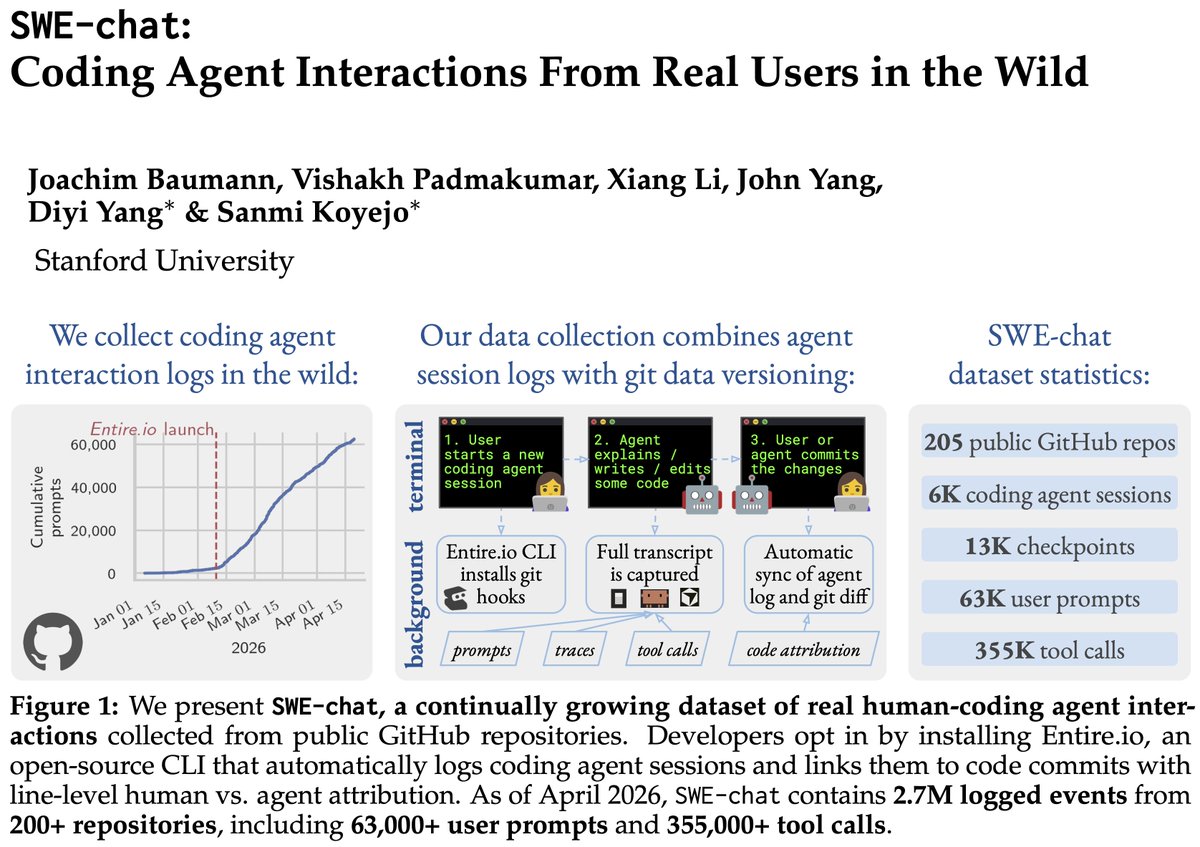
We present SWE-chat: the first large-scale dataset of coding agent interactions from real users in the wild.
In 40% of real coding sessions, the agent writes ~all the code. Users push back 39% of the time – agents almost never stop to check.
Data, paper, & findings in the 🧵👇
How successfully -- and efficiently! -- can agents carry out long-horizon tasks on the web? We built a benchmark of ~200 multi-site tasks, based on people's real browsing history. Many of them take hours to solve.
Paper: https://t.co/NtnoHEqDui
Led by @JangLawrenceK and @kohjingyu, with @rsalakhu
One of the things I’m most excited about this year is building agents that can work productively for hours, days, or weeks. Coding agents are starting to become very competent at this, but what about computer use agents?
Our new benchmark, Odysseys (co-led with @JangLawrenceK) is a set of 200 new tasks derived from real world browsing behavior that measure long horizon web navigation capabilities (potentially up to hours of web browsing work). Interestingly, we find that frontier CUAs are already surprisingly good at working productively for up to an hour on these tasks, but there’s a lot of work to be done in making them even more efficient.
Like every other AI researcher, my real dream is to open a cafe once we solve ASI. So, here’s Opus 4.6 doing some market research for me ("I want to do market research on the most popular cafes in Singapore. Analyse the menus of the top 10 cafes in Singapore (by Google reviews/ratings), and make sure we include at least 1 from the North/South/East/West/Central regions of Singapore. Keep the relevant pages of each cafe open, and summarise their pricing, menu offerings, unique selling points, making sure to reference which tab is opened for each cafe. For each cafe, also help me figure out how long it would take to get to it from Tampines MRT, and include this in your final summary.").
I was very impressed to see Opus 4.6 complete this task after working for 52 mins, satisfying all 7 rubrics that corresponded to this task. It provided a very nice markdown summary at the end that gave me all the information I asked for!
How do coding agents get better from experience?
Past Attempts as Interface: Turn rollouts into reusable summaries that future attempts can build on.
https://t.co/VjglgPLzQQ
Also at #ICLR2026: a new benchmark for coding agents that implement and run experiments from papers.
Masking regions of code gives us a knob to control difficulty of the task (still verifiable!)
Paper: https://t.co/i3I1mVkhvA
Work with @j1mk1m1016, Alex Wilf, and @lpmorency
🚀 Excited to share our ICLR 2026 paper: "From Reproduction to Replication: Evaluating Research Agents with Progressive Code Masking"!
Work with Alex Wilf, LP Morency, @dan_fried
Check out the project here! https://t.co/otvTNoRDbI
1/ Humans often can’t state exactly what they want, making things hard for AI agents. Obvious fix: ask clarifying questions. But which ones?
We studied this empirically with coding agents. Effective clarification comes down to two properties: answerability and task relevance.
We trained an 8B model to help coding agents ask users clarifying questions, matching GPT-5 while asking far fewer Q's! We show a concrete playbook for RL in human-AI interaction: use data analysis to find what drives good interactions, then encode it as a structured reward ⬇️🧵
This morning (Fri) at #ICLR2026, check out Andy's work on ConflictScope:
determining how an LLM prioritizes between a set of user-provided values, by generating scenarios where the values are in conflict.
P4-#4105
I'll be in Rio this week for #ICLR2026 to present "Generative Value Conflicts Reveal LLM Priorities" (Friday morning, P4-#4105). Happy to chat anything related to LLM alignment, human-AI interaction, or multi-agent systems - feel free to DM if interested!