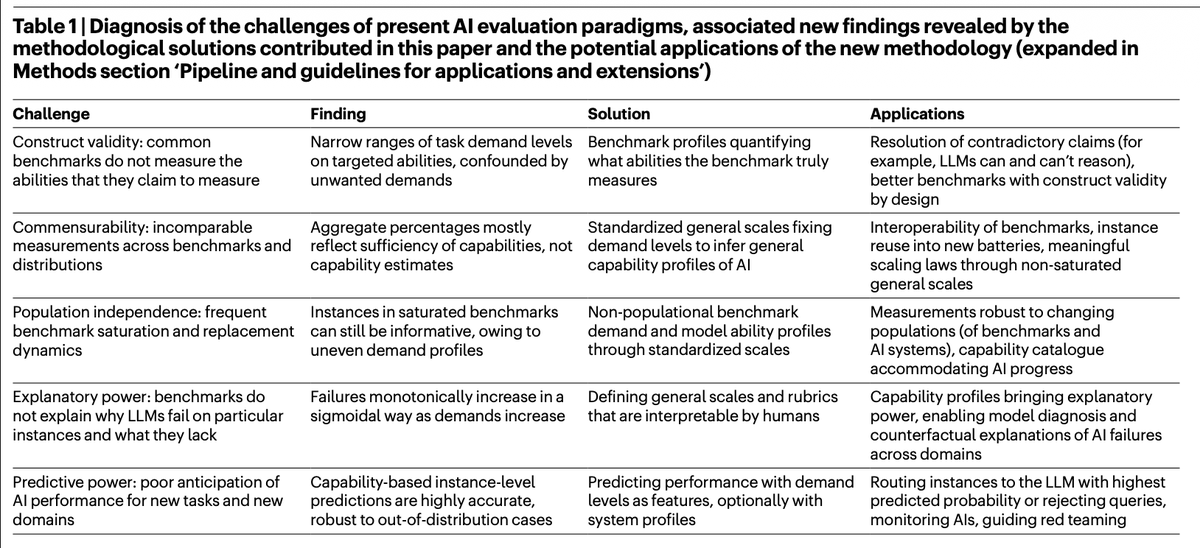
The current science of evaluating AI models, such as primarily relying on benchmarks, is far from optimal. @Nature today a new scalable way used to assess 15 LLMs with absolute demand scales, enhancing predictor power and expandability
https://t.co/fH2k1WrsHX
Many are building AI for healthcare, but how do we know it’s actually safe?
This study introduces a structured framework (READY) to evaluate medical LLMs, focusing on reliability, ethics, data quality, and real-world validity.
https://t.co/SUELFXUdRY
I grew up helping my immigrant parents navigate a healthcare system that wasn't built for them
100M+ Americans still don't have a primary care doctor, but now they can talk to @Lotus for free, anytime
I sat down with @CMichaelGibson to share our why and how we're rebuilding primary care
We’re excited to partner with @kjdhaliwal and the @lotus team working to fix the primary care experience for patients. Lotus is building an AI doctor powered by real doctors to deliver world-class care at scale.
Huge congrats on the launch! Proud to be powering forward-thinking teams and founders like @lotus
We've always believed in the power of AI + patients bringing data together as an agent for change in healthcare