📚 Colocation matters. Cognitive load matters. Boundaries matter. High cohesion matters. Yes, even in the age of AI (maybe even more so). Enter the vertical codebase:
https://t.co/mkbwB9p3Km
If your Prisma schema is getting messy, don’t keep everything in one file.
Prisma ORM supports multiple schema files, it's easier to set up and much cleaner to maintain.
Small change, big clarity 👇
📚 Creating thin abstractions is easy, until you’re trying to build them on top of functions that heavily rely on generics.
I wrote about the tradeoffs of wrapping useQuery and why type inference makes this trickier than it looks.
https://t.co/IHaPOtqodI
Si van a Puebla mejor evítenlo.
En el @PueblaAyto donde gobierna morena con @pepechedrauimx las 🐀 de autopartes operan con total impunidad porque saben que no les pasa nada.
Ni los parquímetros de la 4T ni el soldadito que trajeron a la @SSC_Pue sirvieron.
#CapitalImparable de delitos.
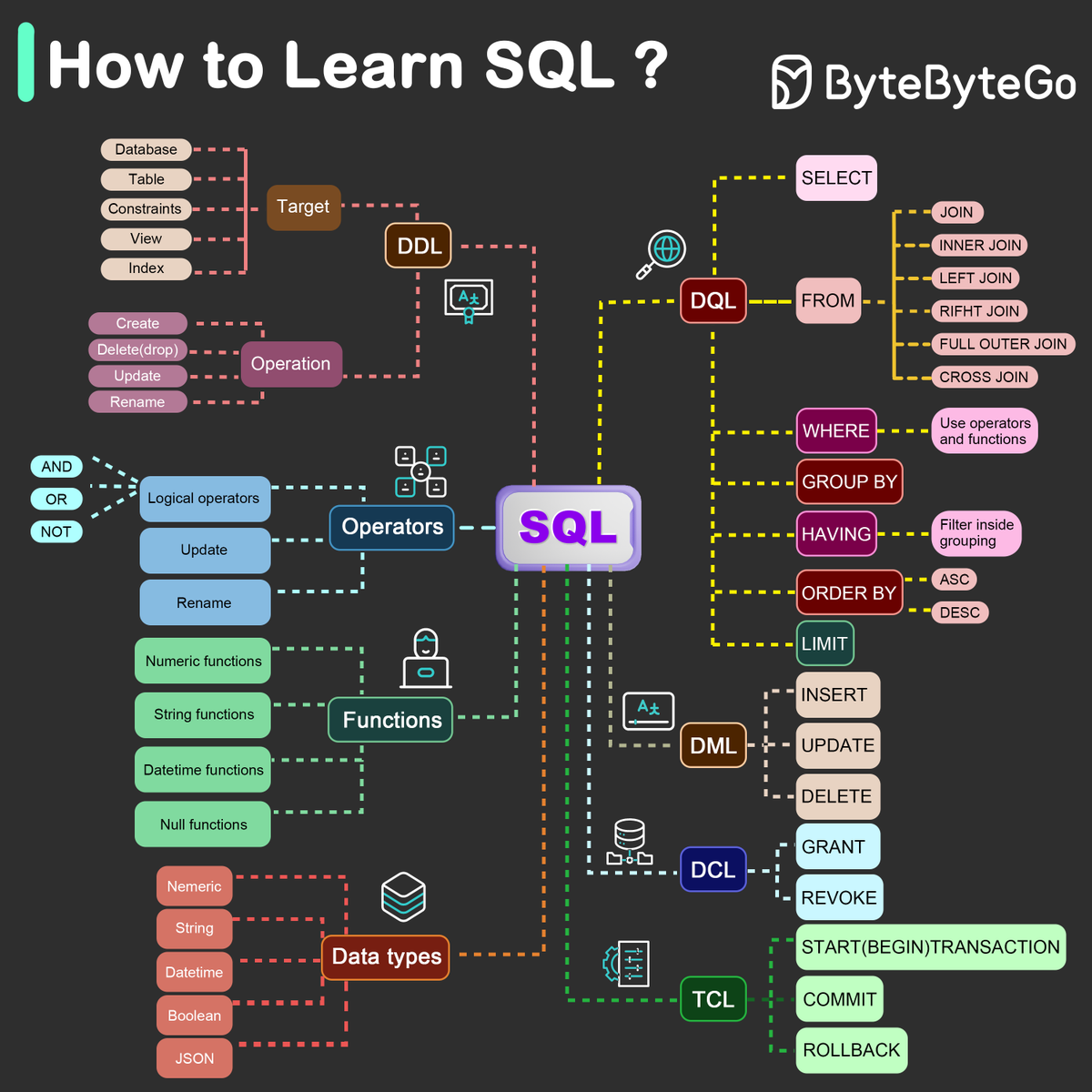
What is the best way to learn SQL?
In 1986, SQL (Structured Query Language) became a standard. Over the next 40 years, it became the dominant language for relational database management systems. Reading the latest standard (ANSI SQL 2016) can be time-consuming. How can I learn it?
There are 5 components of the SQL language:
- DDL: data definition language, such as CREATE, ALTER, DROP
- DQL: data query language, such as SELECT
- DML: data manipulation language, such as INSERT, UPDATE, DELETE
- DCL: data control language, such as GRANT, REVOKE
- TCL: transaction control language, such as COMMIT, ROLLBACK
For a backend engineer, you may need to know most of it. As a data analyst, you may need to have a good understanding of DQL. Select the topics that are most relevant to you.
Over to you: What does this SQL statement do in PostgreSQL: “select payload->ids->0 from events”?
–
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): https://t.co/uc5M7CdXXC
Build and Deploy a Full Stack Next.js 13 Application with React, TypeScript, & Tailwind CSS
#nextjs#react#typescript#tailwindcss
https://t.co/BovAb3meP1
What is the difference between 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝗶𝗻𝗴 𝗮𝗻𝗱 𝗕𝘂𝗰𝗸𝗲𝘁𝗶𝗻𝗴 𝗶𝗻 𝗦𝗽𝗮𝗿𝗸?
When working with big data there are many important concepts we need to consider about how the data is stored both on disk and in memory, we should try to answer questions like:
➡️ Can we achieve desired parallelism?
➡️ Can we skip reading parts of the data?
✅ The question is addressed by partitioning and bucketing procedures
➡️ How is the data colocated on disk?
✅ The question is mostly addressed by bucketing.
So what are the procedures of Partitioning and Bucketing? 𝗟𝗲𝘁'𝘀 𝘇𝗼𝗼𝗺 𝗶𝗻.
𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝗶𝗻𝗴.
➡️ Partitioning in Spark API is implemented by .partitionBy() method of the DataFrameWriter class.
➡️ You provide the method one or multiple columns to partition by.
➡️ The dataset is written to disk split by the partitioning column, each of the partitions is saved into a separate folder on disk.
➡️ Each folder can maintain multiple files, the amount of resulting files is controlled by the setting spark.sql.shuffle.partitions.
✅ Partitioning enables Partition Pruning. Given we filter on a column that we used to partition the dataframe by, Spark can plan to skip the reading of files that are not falling into the filter condition.
𝗕𝘂𝗰𝗸𝗲𝘁𝗶𝗻𝗴.
➡️ Bucketing in Spark API is implemented by .bucketBy() method of the DataFrameWriter class.
𝟭: We have to save the dataset as a table since the metadata of buckets has to be saved somewhere. Usually, you will find a Hive metadata store leveraged here.
𝟮: You will need to provide number of buckets you want to create. Bucket number for a given row is assigned by calculating a hash on the bucket column and performing modulo by the number of desired buckets operation on the resulting hash.
𝟯: Rows of a dataset being bucketed are assigned to a specific bucket and collocated when saving to disk.
✅ If Spark performs wide transformation between the two dataframes, it might not need to shuffle the data as it is already collocated in the executors correctly and Spark is able to plan for that.
❗️There are conditions that need to be met between two datasets in order for bucketing to have desired effect.
𝗪𝗵𝗲𝗻 𝘁𝗼 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻 𝗮𝗻𝗱 𝘄𝗵𝗲𝗻 𝘁𝗼 𝗕𝘂𝗰𝗸𝗲𝘁?
✅ If you will often perform filtering on a given column and it is of low cardinality, partition on that column.
✅ If you will be performing complex operations like joins, groupBys and windowing and the column is of high cardinality, consider bucketing on that column.
❗️Bucketing is complicated to nail as there are many caveats and nuances you need to know when it comes to it. More on it in future posts.
--------
Follow me to upskill in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
Also hit 🔔to stay notified about new content.
𝗗𝗼𝗻’𝘁 𝗳𝗼𝗿𝗴𝗲𝘁 𝘁𝗼 𝗹𝗶𝗸𝗲 💙, 𝘀𝗵𝗮𝗿𝗲 𝗮𝗻𝗱 𝗰𝗼𝗺𝗺𝗲𝗻𝘁!
Join a growing community of Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: https://t.co/qgNCnGtF4A
Here is a neat API that doesn't mess with your async/await when working with Web Streams.
The first response of fetch() is a Web Stream! Great for logging progress of a large download.
.clone() a stream, then log the progress and then return the original
📝 ¡Raúl Luján de la comunidad DevTalles nos comparte una aplicación practica que realiza un login completo, utilizando #deeplink para restablecer contraseñas
Este ejemplo sigue la estructura de nuestros cursos de Flutter
😉Les dejo el enlace en el hilo: https://t.co/tzRMY4YqLo
Practicas en general gratuitas (YouTube)
https://t.co/a70ypn9AwZ
Tip: si buscan un video en YouTube y ponen un "-" entre la t y la u, se muestra en pantalla completa y sin anuncios.
TypeScript Tip 👇
Writing _type guard functions_ by hand is cumbersome and unsafe.
Consider using TS-Pattern instead, it's terser, safer and narrows types for you:
If you are a UI/UX designer and looking for wireframing software to create your wireframes. Here are some 05 amazing wireframe tools that can help you when designing. I trust you're having a great weekend!
Retweet are highly appreciated 💜