New research from Microsoft Research
I see a lot of AI engineers handwriting agent skill docs and hope they generalize.
Probably not optimal. This works show why.
It treats the skill doc as a trainable external state of a frozen agent instead.
It introduces SkillOpt, where an optimizer model makes validation-gated edits to the skill file. It adds, deletes, or replaces instructions, with a textual learning rate that controls how aggressively each round rewrites the doc. The agent itself never changes.
SkillOpt is best or tied on all 52 (model, benchmark, harness) cells.
On GPT-5.5 it adds 23.5 points in direct chat, 24.8 with Codex, and 19.1 with Claude Code over no skill. It beats human-written skills, TextGrad, GEPA, and EvoSkill, carries zero extra inference-time cost, and the learned skills transfer across models and harnesses.
Paper: https://t.co/mNgTmmT32U
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
NEW paper worth reading.
A full agentic workflow can be distilled into model weights and run at roughly 100x lower inference cost while preserving near-frontier task quality.
The workflow includes multi-step LLM calls, tool invocations, intermediate scratchpads, and decision structure.
Instead of expressing all of that at runtime through a framework, the paper amortizes the behavior into a compiled model through targeted distillation.
This is the strongest economic argument for agent compilation so far. Runtime loops are flexible, but expensive. Compiled workflows trade some flexibility for a massive inference-cost reduction.
Paper: https://t.co/4k4urYOAeQ
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
// Code as Agent Harness //
100+ page report on all things related to agent harnesses.
(bookmark it)
In particular, the survey summarizes methods and applications of code as agent harness.
This paper makes a strong case that code-as-harness might be the key to moving us towards a broader science harness engineering.
Is code all you need? Maybe.
Regardless, the paper argues that future systems must have the following four properties: executable, inspectable, stateful, and governed.
Paper: https://t.co/bcNtSpSsQq
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Introducing a revival of PapersWithCode!
As @ilyasut said, we're back to the "age of research".
Hence, it's important to share research and build on each other's work.
> find SOTA per domain, not just LLMs
> leaderboards
> methods
> all parsed at scale using AI agents.
We built an AI system that discovers health biomarkers from wearable data.
One of its first findings: "late-night doomscrolling" is a statistically validated predictor of depression severity (ρ = 0.177, p < 0.001, n = 7,497).
The AI named the feature. No human guidance.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
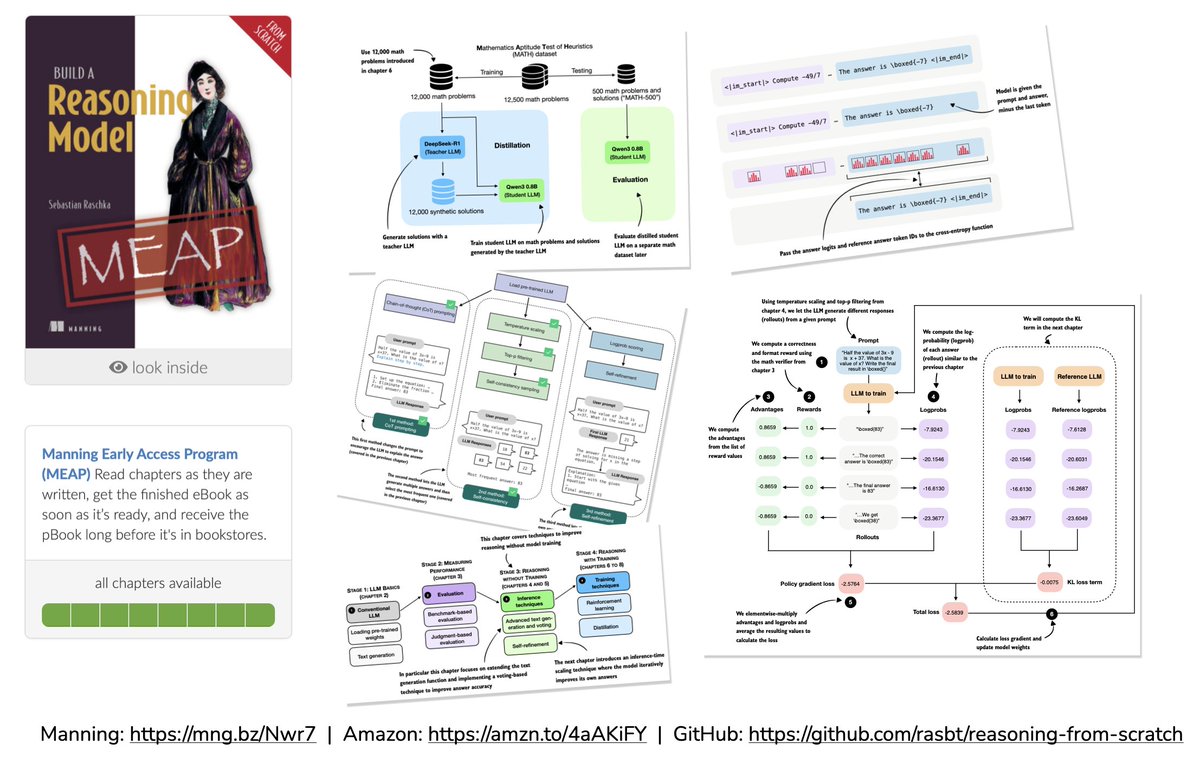
It’s done.
All chapters of Build A Reasoning Model (From Scratch) are now available in early access.
The book is currently in production and should be out in the next months, including full-color print and syntax highlighting.
There’s also a preorder up on Amazon.
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow.
Just to give an example, over the weekend I was building a local video analysis dashboard for the cameras of my home so I wrote: “Here is the local IP and username/password of my DGX Spark. Log in, set up ssh keys, set up vLLM, download and bench Qwen3-VL, set up a server endpoint to inference videos, a basic web ui dashboard, test everything, set it up with systemd, record memory notes for yourself and write up a markdown report for me”. The agent went off for ~30 minutes, ran into multiple issues, researched solutions online, resolved them one by one, wrote the code, tested it, debugged it, set up the services, and came back with the report and it was just done. I didn’t touch anything. All of this could easily have been a weekend project just 3 months ago but today it’s something you kick off and forget about for 30 minutes.
As a result, programming is becoming unrecognizable. You’re not typing computer code into an editor like the way things were since computers were invented, that era is over. You're spinning up AI agents, giving them tasks *in English* and managing and reviewing their work in parallel. The biggest prize is in figuring out how you can keep ascending the layers of abstraction to set up long-running orchestrator Claws with all of the right tools, memory and instructions that productively manage multiple parallel Code instances for you. The leverage achievable via top tier "agentic engineering" feels very high right now.
It’s not perfect, it needs high-level direction, judgement, taste, oversight, iteration and hints and ideas. It works a lot better in some scenarios than others (e.g. especially for tasks that are well-specified and where you can verify/test functionality). The key is to build intuition to decompose the task just right to hand off the parts that work and help out around the edges. But imo, this is nowhere near "business as usual" time in software.
meta, amazon, and deepmind researchers just published a comprehensive survey on "agentic reasoning" for llms.
29 authors. 74 pages. hundreds of citations.
i read the whole thing.
here's what they didn't put in the abstract:
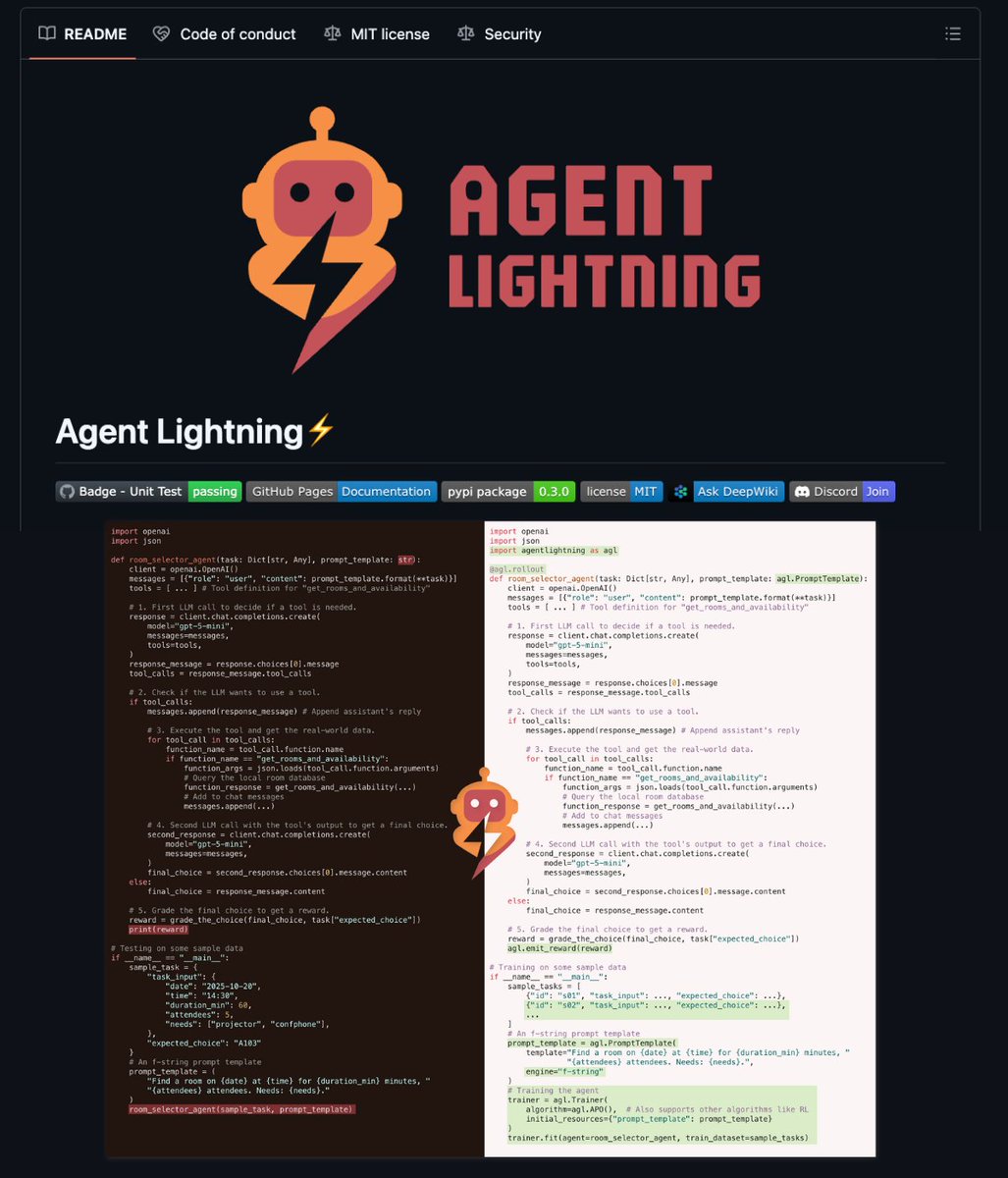
🚨BREAKING: Microsoft just solved the "Agent Loop" problem.
Agent Lightning is an open-source framework that lets agents learn from their own mistakes using Reinforcement Learning.
Your agent fails a task → Agent Lightning analyzes why → Updates the prompt automatically → Next run succeeds.
100% Opensource.
I'm Boris and I created Claude Code. I wanted to quickly share a few tips for using Claude Code, sourced directly from the Claude Code team. The way the team uses Claude is different than how I use it. Remember: there is no one right way to use Claude Code -- everyones' setup is different. You should experiment to see what works for you!
Kimi K2.5 tech report just dropped!
Quick hits:
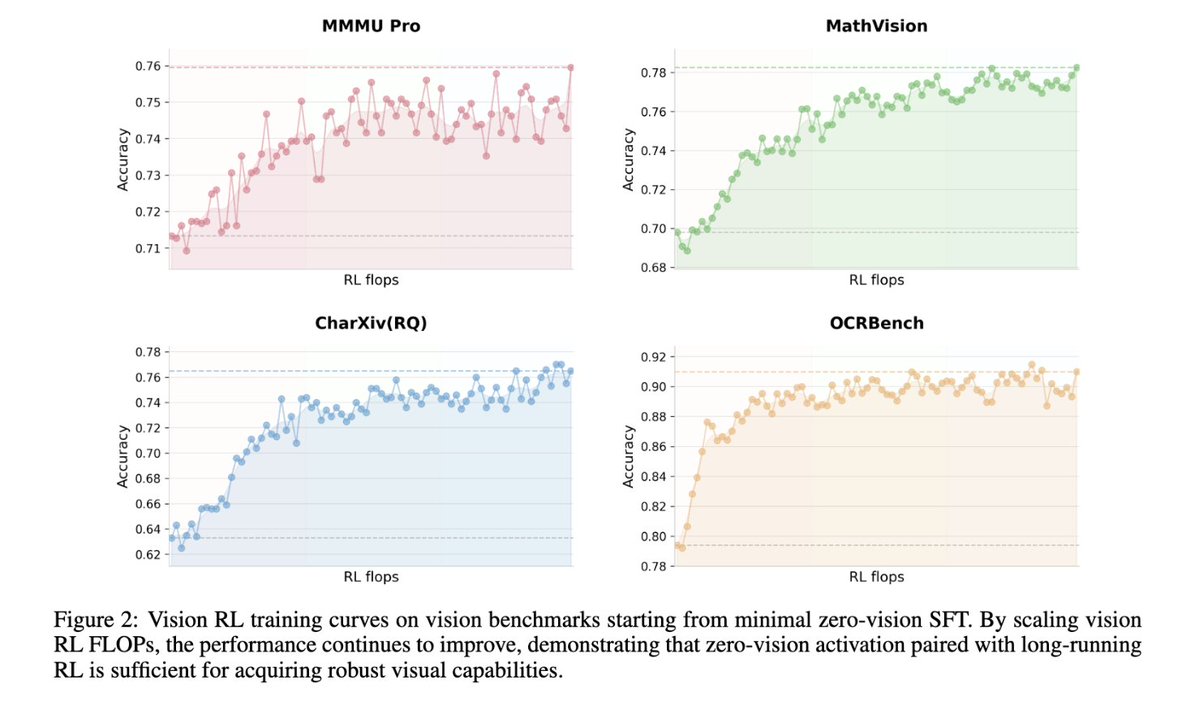
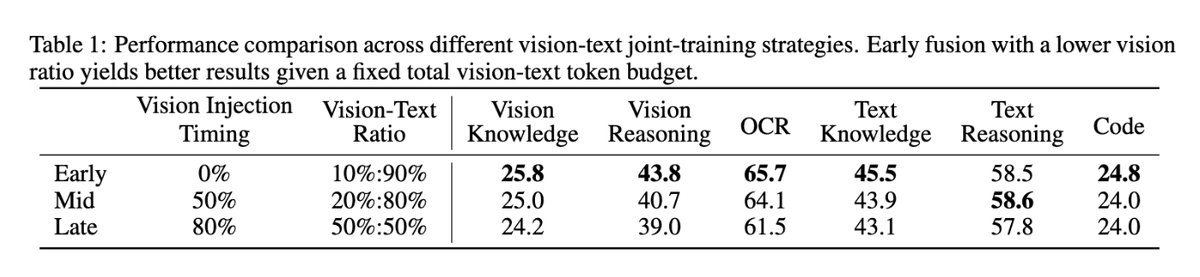
- Joint text–vision training: pretrained with 15T vision-text tokens, zero-vision SFT (text-only) to activate visual reasoning
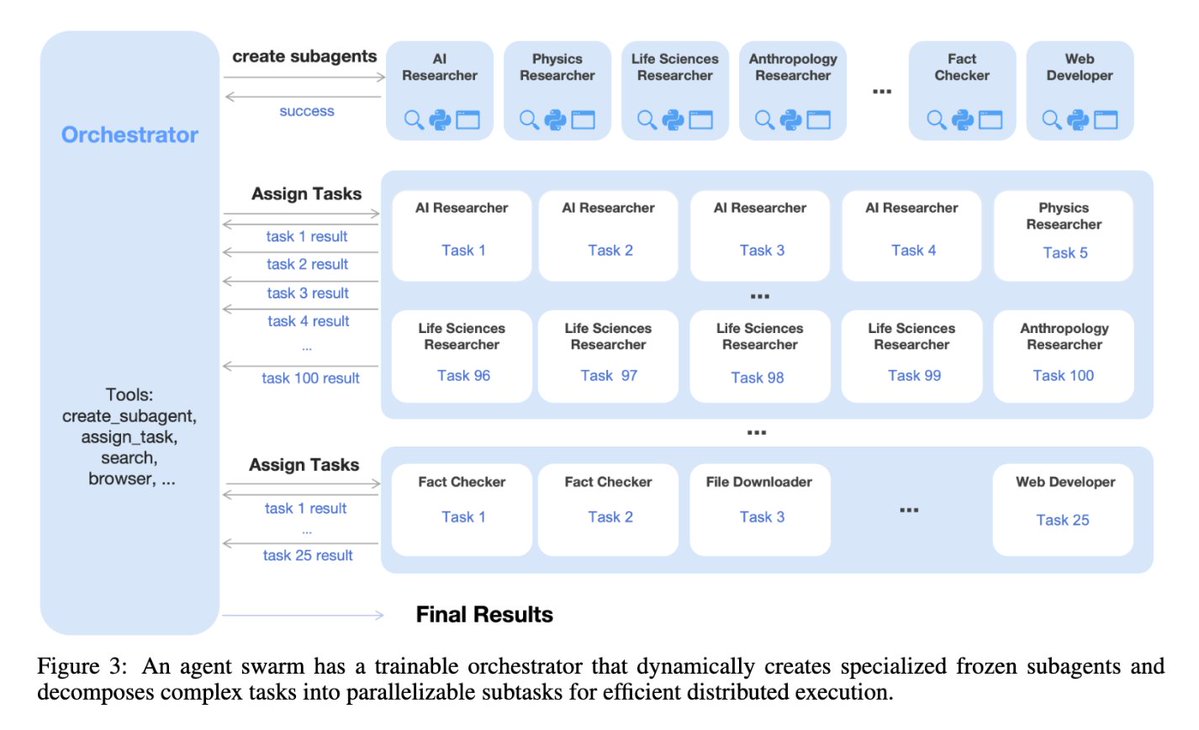
- Agent Swarm + PARL: dynamically orchestrated parallel sub-agents, up to 4.5× lower latency, 78.4% on BrowseComp
- MoonViT-3D: a unified image–video encoder with 4× temporal compression, enabling 4× longer videos in the same context
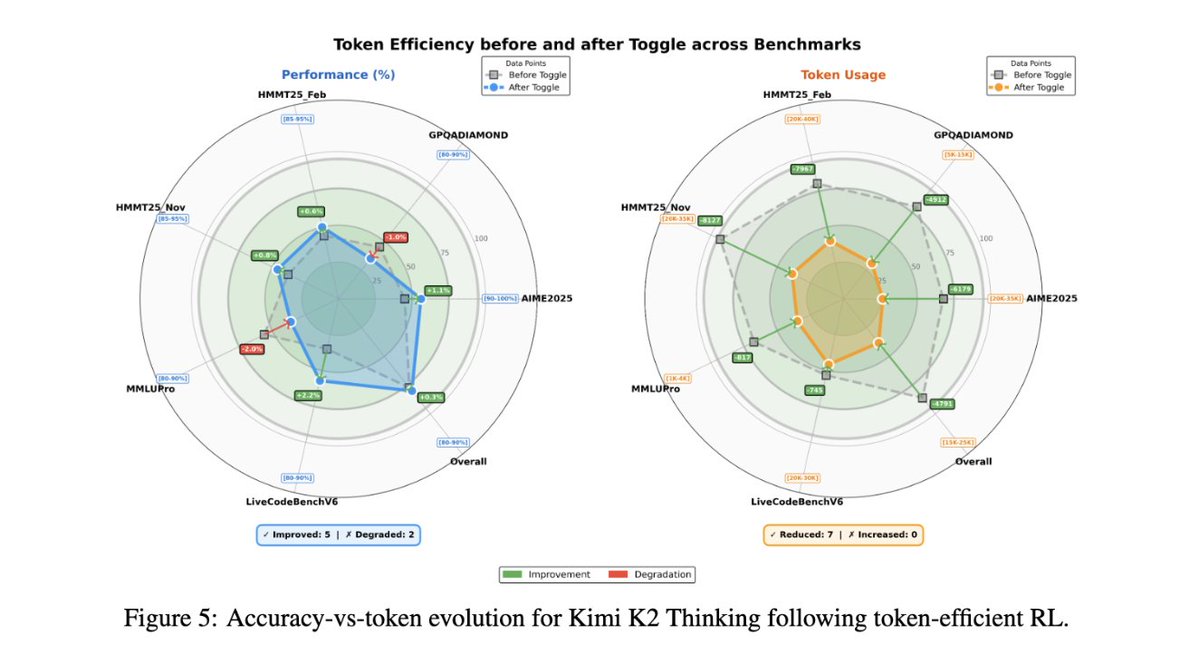
- Toggle: token-efficient RL, 25–30% fewer tokens with no accuracy drop
Here's our work toward scalable, real-world agentic intelligence. More details in the report 👉https://t.co/N5pwm0M4jm