This might be the funniest card I've ever been given, but when I received it, it was only partially true—I was serving as interim ED initially. Delighted to share that Georgetown has now converted my role to permanent, and psyched to get to keep leading this awesome team!
Anthropic now has a team dedicated to AI and the rule of law — and we've just opened our first role.
@AnthropicAI has studied what AI means for the economy. This team asks a different question: what will it mean for executive power, for courts and elections — and for the public deliberation that constitutional democracy ultimately rests on?
We're looking for someone with real depth in both AI and the law — a legal scholar, political scientist, or experienced government hand who can reason about frontier systems and the institutions they will affect.
If that's you, or someone you know: https://t.co/668HDz1lhf
New paper: We identify a new class of reward hacking caused by mitigations, which we call reward bias substitution. We prove no standard benchmark detects it, even with oracle access to the true reward. We find it active in GRPO, in SOTA reward models, and published methods.
More big news from Mathlib:
# The Formal Frontier Project
The Mathlib Initiative is launching Formal Frontier — a new project focused on responsible, scalable, and open-source AI-driven autoformalization of mathematics.
The primary goal of Formal Frontier is to bring formal mathematics closer to the research frontier in a way that is scalable, composable with Mathlib and its ecosystem, aligned with community standards, and genuinely useful for researchers.
The Mathlib Initiative, a program of Renaissance Philanthropy, is funded by generous donations from Alex Gerko and XTX Markets.
Why now? Autoformalization is advancing rapidly, and the choices made now will shape the foundations that the next generation of formalized mathematics is built on. We think getting this right matters, and that it should be done in the open, in close coordination with the communities who will actually use and extend these artifacts.
What will we do? Formal Frontier will help establish standards and set a positive example for what formal mathematics in the age of AI should look like, both in the technical artifacts produced and in how projects at this scale engage with the wider community.
The initial phase of the project will have three components:
We will develop and release an autoformalization specification, in coordination with the community. This specification will articulate what a valid autoformalization looks like, covering how formal code should relate to its informal source, what counts as adequate coverage and faithfulness, and how artifacts document their relationship to Mathlib. It will also address the broader lifecycle of an autoformalized artifact, including expectations around human oversight, maintenance, licensing, coordination with related projects, and paths to eventual upstreaming. We expect this to happen quite soon, and will make follow-up announcements in the next couple of weeks.
We will develop and release open-source autoformalization tooling, so that inference cost, rather than access to tooling, is the main limiting factor for researchers who want to autoformalize at scale.
We will release autoformalized artifacts that embody the standards this project promotes, demonstrating in practice what responsible autoformalization at scale looks like while providing material that researchers can readily build on.
New essay for @TheFP on searching for God in Silicon Valley.
"They are building something that has brought them, unexpectedly, to the edge of where He would be."
Our report focuses on claims that are (1) solidly defensible and (2) generally agreed within METR. Here I’ll give some personal opinions on how we should feel about the state of AI risk, and the IMO most important limitations of the report.
The questions posed by AI are bigger than the AI community. We urgently need the world – religions, civil society, academics, governments – to participate in creating a positive outcome.
I'm glad the Catholic Church is engaging, and honored to speak at the presentation.
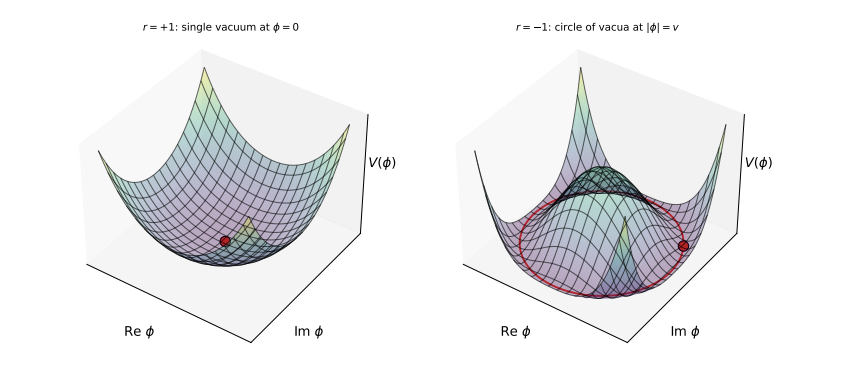
We have a new paper out on spontaneous symmetry breaking, Goldstone modes, and deep learning!
This is work with the amazing team of @t_andy_keller@YueSong48287250@takeru_miyato@wellingmax.
A brief thread on a marriage of physics and ML. (Link at end).
A bittersweet announcement! For family reasons, I will be leaving AISI soon to move back to the Bay Area. I will be starting a new nonprofit alignment research org (more to come).
I will miss this place! Here are some reflections about my time at AISI. 🧵❤️
@sethlazar This seems very important to me, especially if it can used as a tool for "philosophical engineering" i.e. if we can reason our way towards using language (the environment in which the training processes take place) to shape this endpoint for the abstraction of goodness
This is cool, and bears on something we've been thinking about too (cc @danielmurfet). I think there's probably a third kind besides convergent and natural (or perhaps it's a subset of convergent), which would be some sort of socially-constructed/constructionist conception of good. So, not a natural kind in the sense of not in some sense really there in the world (reducible to naturalistic properties), but also not a merely convergent representation that the models happen to arrive at--something of genuine normative significance.
Worth saying that all these possibilities have technical names in metaphysics that I'm ignorant of but would probably be quite useful to give a little scaffolding to the discussion. I wonder if @LedermanHarvey could do a bit of translation/parsing.
Super excited to have been part of preparing and delivering teaching materials for the Singular Learning Theory day. Thanks to Iliad and my coauthors @FurmanZach and Kai Ogden for making this intensive happen.
New paper arguing that AI automation of AI alignment research could fail due to AI mistakes, even if the research agents are intent aligned (not trying to cause harm).
Arguably this is obvious: AIs make mistakes all the time (as do humans). But it is useful to go into detail.🧵
We just released the full course materials of the Iliad Intensive — a month-long, full-time AI alignment course for mathematicians, physicists, and theoretical computer scientists.
~20 contributors, 19 modules, at a depth that doesn't exist elsewhere for most of these topics. 🧵