Today we're excited to introduce the micro1·Crosby Contract Redlining Benchmark.
In collaboration with @crosbylegal, we built a benchmark on real contract redlining to identify how frontier AI models perform at contract negotiation.
Practicing attorneys negotiated multi-round SaaS agreements, and we tested how models handled the actual back-and-forth of a deal.
Results:
GPT-5.5: 50.5%
Claude Fable 5: 47.3%*
Gemini 3.5 Flash: 45.1%
Claude Opus 4.8: 44.4%
The biggest weakness showed up early in negotiations, meaning models performed much better once there was already context and prior redlines to react to, but struggled more when they had to make the first move.
Our takeaway: today’s models are useful in legal workflows and can support live deals, but are not ready to negotiate one.
Check out the full report at Crosby Intelligence.
100%.
there's many new job types emerging as a result of AI adoption throughout the economy - starting with training and evaluating models/agents.
at micro1 we've created over 15,000 opportunities in the past few months alone.
human involvement to train AI and to deliver the ultimate value that AI accelerates will always be there.
Today, we’re committing $5,000,000 to launch the micro1 Company Data Partnerships Referral Program.
For every company you refer, you can earn up to $25,000. Simply introduce a company, have them identify you as the referrer during onboarding, and once they enter into a paid data partnership with micro1, you’ll receive your referral payout.
If you know a company that wants to turn its operational data into a recurring revenue stream while accelerating its adoption of AI through micro1's Data Partnership Program, we’d love an introduction.
visit /data to get started
Most people don’t know you can get paid to help train AI models.
Micro1 CEO @aliansarinik runs one of the leading companies paying people for their expertise.
Now he is giving away $5 million to find companies with real world data.
Worth paying attention to…
Fable 5 is now live on https://t.co/PFtK9w67C5 and currently ranks #1 across all three of our expert reasoning benchmarks: tax, legal, and financial reasoning.
These benchmarks evaluate how frontier models perform on domain-specific tasks that require expert knowledge, multi-step reasoning, and precise application of rules.
Huge congrats to the @AnthropicAI team on an impressive release.
we’re partnering with 50 companies over the next two weeks, each with 50–200 employees, to help improve AI models using real-world company workflows.
we believe the companies that helped build modern business workflows should participate in — and very much benefit from — the value created by the next generation of AI systems.
for many companies, these partnerships can create a meaningful new revenue stream, often ranging from $100K to $2M+, with opportunities to become recurring over time. our goal is to do this in a way that is privacy-first, low-lift, and aligned with the work companies are already doing every day.
if you’re interested in contributing to AI advancement while improving your own workflows alongside micro1 and our frontier AI lab partners, we’d love to hear from you.
please reach out to to [email protected] if you’re an executive at a 50+ employee company, excited to potentially partner up!
a very large portion of our latest expansion & data pipeline requests have been coding. as model capabilities improve in a certain domain, data demand explodes even more.
at micro1, we're building a world class coding research team. if you're interested in joining, check out micro1. ai/ research
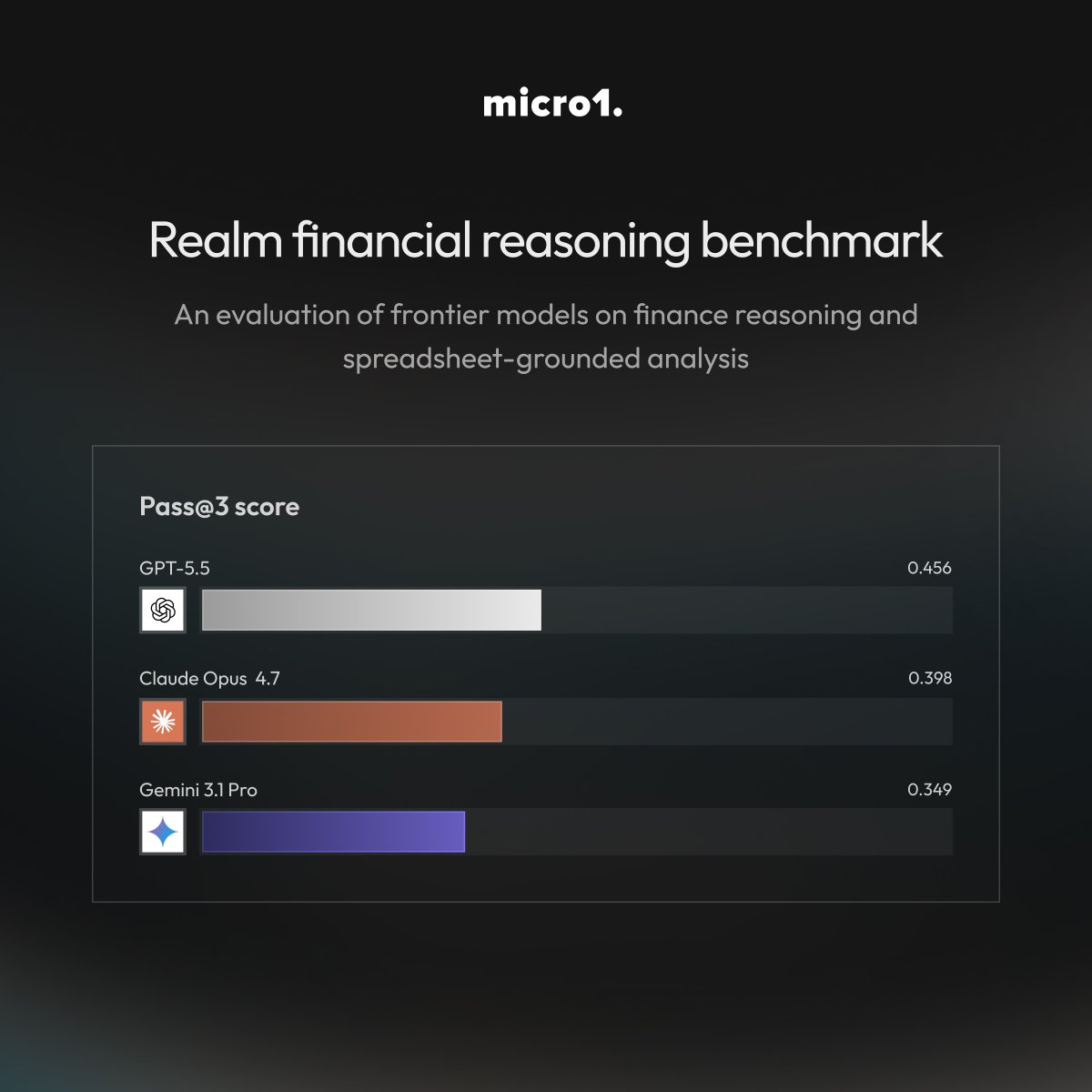
Introducing the Realm Financial Reasoning benchmark, our new evaluation of frontier AI on reasoning in finance and spreadsheet-grounded analysis.
Tasks are built around the actual work product that practitioners deliver, from IFRS reconciliation workbooks and hedge-fund backtests to VC term sheet analyses and treasury cash-flow forecasts. Each task drops the model into a sandbox with the same source materials a human analyst would open: named-range Excel workbooks, broker PDFs, earnings call transcripts, monetary-policy decisions.
Here's what the results showed (Pass@3):
-GPT-5.5: 0.456
-Claude Opus 4.7: 0.398
-Gemini 3.1 Pro: 0.349
The three models score similarly, and none clears 50% on tasks that demand a judgment call. The back and middle office are defensible today, but on capital allocation questions current frontier models should be treated as research accelerators, not final decision-making support systems.
Full report linked in the comments.
Today we’re releasing Realm Warren, part of the Realm benchmark series for measuring frontier AI models on real-world expert workflows.
Each task tests whether a model can produce a legal work product and adapt it as circumstances evolve. We evaluated Claude Opus 4.7, GPT-5.5, and Gemini 3.1 Pro across federal and state law, scored through IRAC: issue spotting, rule identification, factual application, and legal conclusion.
Here’s the results (mean score):
-Claude Opus 4.7: 0.358
-GPT-5.5: 0.351
-Gemini 3.1 Pro: 0.219
The sub-40% result shows where models break down on long-horizon legal work. Three failure modes drive it: the IRAC chain breaks after issue spotting, models front-load their effort and fail to revise, and skipping visual exhibits leads to invented facts.
Full report linked in the comments.