a very large portion of our latest expansion & data pipeline requests have been coding. as model capabilities improve in a certain domain, data demand explodes even more.
at micro1, we're building a world class coding research team. if you're interested in joining, check out micro1. ai/ research
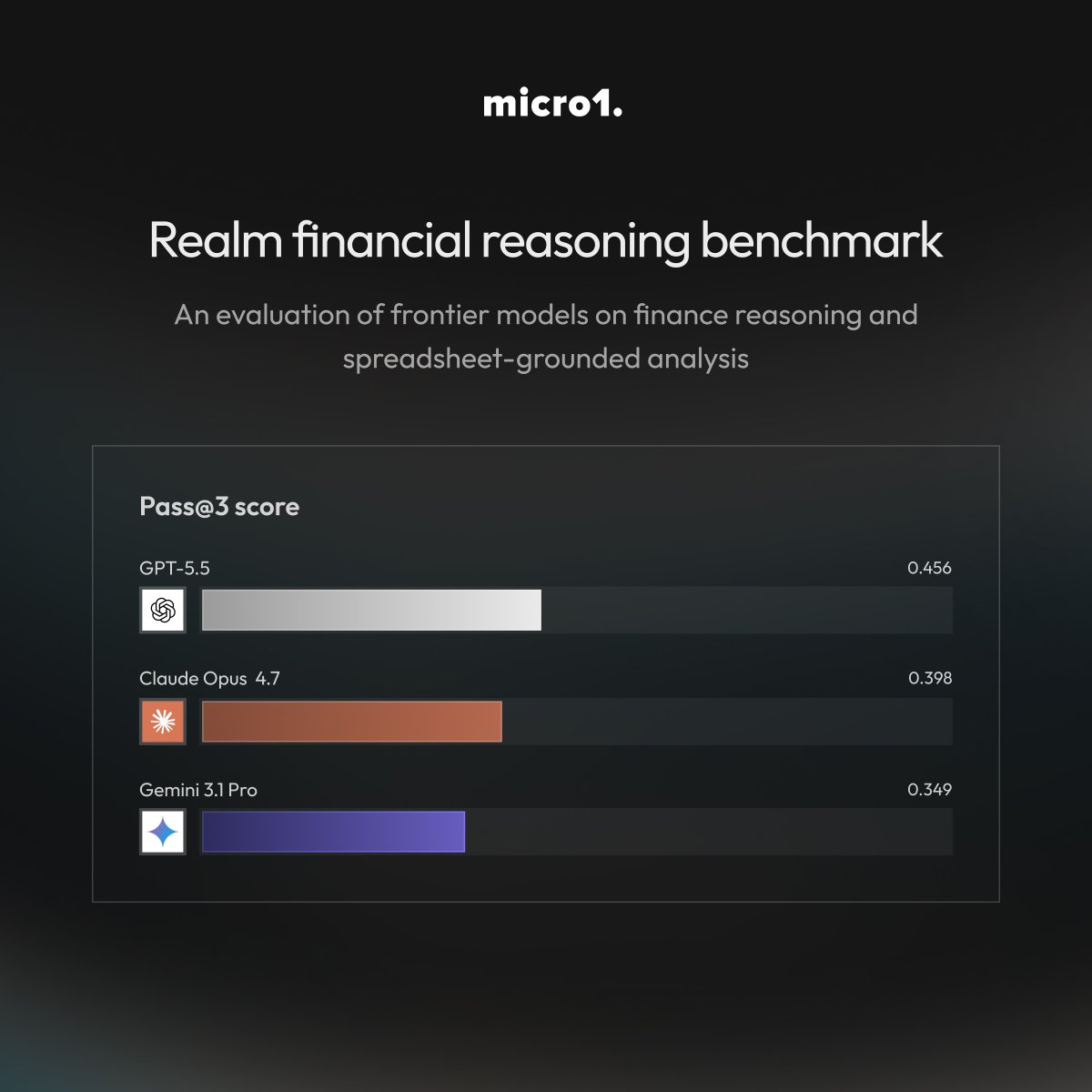
Introducing the Realm Financial Reasoning benchmark, our new evaluation of frontier AI on reasoning in finance and spreadsheet-grounded analysis.
Tasks are built around the actual work product that practitioners deliver, from IFRS reconciliation workbooks and hedge-fund backtests to VC term sheet analyses and treasury cash-flow forecasts. Each task drops the model into a sandbox with the same source materials a human analyst would open: named-range Excel workbooks, broker PDFs, earnings call transcripts, monetary-policy decisions.
Here's what the results showed (Pass@3):
-GPT-5.5: 0.456
-Claude Opus 4.7: 0.398
-Gemini 3.1 Pro: 0.349
The three models score similarly, and none clears 50% on tasks that demand a judgment call. The back and middle office are defensible today, but on capital allocation questions current frontier models should be treated as research accelerators, not final decision-making support systems.
Full report linked in the comments.
Earlier this week we hosted the “Women Shaping the Future of AI in Law” panel, bringing together leaders across legal, AI, and enterprise technology to discuss what it actually takes to build reliable AI systems for the legal industry.
The conversation covered where AI is already driving real value in legal workflows, the challenges that still remain around trust, accuracy, and human oversight, and how the industry is thinking about building systems that can perform consistently in real-world legal environments.
A huge thank you to Anique Drumright, D. Isabel Ajuria, Shannon Yavorsky, Isabel Yishu Yang, and Amy Sennett for an incredible discussion, and to everyone who joined us.
The future of legal AI will depend on more than model capability alone. It will require deep collaboration between AI builders, legal experts, and the enterprises bringing these systems into real-world workflows.
Today we’re releasing Realm Warren, part of the Realm benchmark series for measuring frontier AI models on real-world expert workflows.
Each task tests whether a model can produce a legal work product and adapt it as circumstances evolve. We evaluated Claude Opus 4.7, GPT-5.5, and Gemini 3.1 Pro across federal and state law, scored through IRAC: issue spotting, rule identification, factual application, and legal conclusion.
Here’s the results (mean score):
-Claude Opus 4.7: 0.358
-GPT-5.5: 0.351
-Gemini 3.1 Pro: 0.219
The sub-40% result shows where models break down on long-horizon legal work. Three failure modes drive it: the IRAC chain breaks after issue spotting, models front-load their effort and fail to revise, and skipping visual exhibits leads to invented facts.
Full report linked in the comments.
In recognition of National Cancer Prevention and Early Detection Month, join us for an important conversation on how AI is reshaping the future of cancer care.
From accelerating drug discovery to enabling more accurate, scalable diagnostics, artificial intelligence is unlocking new possibilities across prevention, early detection, and treatment. We’ll also dive into the real challenges, data quality, bias, interpretability, and bridging the gap between research breakthroughs and real-world clinical impact.
Featuring:
•Virginie Buggia-Prevot, PhD (Executive Director, @ValoHealth)
•Bahar Rahsepar, PhD (Associate Director of Product, @Path_AI)
•Paola Rodríguez - MD, Eng, MSc. (Director of Medical Research, @micro1_ai)
Moderated by @Exp_Mark (Chief Economist, micro1)
This session brings together leading voices at the intersection of AI and healthcare to explore how human + AI are transforming patient outcomes.
Join us on 4/28, 10am PT: https://t.co/OekKbnPidC
Dan Heffernan has led sales teams at some of the biggest names in tech and now is making his mark in AI.
In this conversation, he breaks down why the human element is the secret behind the best models, and how he's putting that belief into action at micro1 while training AI.
Watch the full interview on YouTube now! (Link in the comments)
micro1 x Crosby: AI Fellowship for SaaS Contracting Attorneys
We've teamed up with @crosbylegal to launch an AI Fellowship for SaaS Contracting Attorneys, and we're looking for attorneys with deep expertise in tech transactions to help us shape how AI handles real legal work.
Here's what the fellowship looks like:
- Simulated contract negotiations and redlining exercises
- Evaluating AI-generated suggestions for accuracy and legal soundness
- Collaborating with product and research teams to improve AI outputs
This is a part-time, fully remote opportunity paying $80-$105/hr.
Apply now at the link in the comments.
This Tuesday at 11:00 AM PT, micro1 is hosting a conversation on The Human Foundation of AI in Healthcare on the micro1 Forum.
Moderated by @Exp_Mark (Chief Economist at micro1) this session brings together Paola Rodríguez - MD, Eng, MSc. (Director of Medical Research, micro1), Sam Hashemi (VP at @prenuvo), and David Q. Sun (VP of AI/ML at @eightsleep) to explore how human intelligence shapes the future of healthcare AI.
As AI systems evolve from static tools to more agentic, decision-supporting systems, one thing is clear: the future of healthcare won’t be defined by automation alone, but by how effectively humans and machines work together.
This session is based on their recent co-authored research paper: https://t.co/Eho1gqch6s
Register for the live event to hear from the authors themselves: https://t.co/Q5Wkt3I2Rb
Human-first AI ❤️
Last Friday we hosted an after office in Buenos Aires with 100+ experts from the micro1 community. A great chance to step away from the screen, connect in person, and spend time with the incredible people contributing to AI training projects across our platform.
Thanks to everyone who joined and made it such a great evening!
Most enterprises think non-deterministic AI outputs mean they can't trust agent workflows.
Andrew Maas, VP of AI at @micro1_ai, disagrees and explains exactly how to engineer reliability into agentic systems on the latest Partner Podcast with our CTO @BenAtBox.
Timestamps
02:54 What micro1 does and the role of human experts in AI systems
04:13 Rise of multi-step agentic workflows and domain-specific AI capabilities
07:48 Limits of current models and the need for deeper domain expertise
08:12 One-shot vs multi-step AI reasoning and why it matters
10:07 Composing multiple LLM steps to create reliable enterprise workflows
13:22 Variability in LLM outputs and concerns about enterprise reliability
18:54 Files as the new interface between humans and AI agents
22:24 Using evals and human review to improve AI systems in production
26:30 Experiment and challenge assumptions about AI limits
This Friday at 9:00 AM PT, Chief Economist at micro1, @Exp_Mark will be joined by Victoria (Tori) Westerhoff (Principal AI Security & AI Red Team at @Microsoft) and Liu Zhang, Member of Technical Staff at micro1) on the micro1 forum to explore red teaming for agentic AI systems.
We’ll dive into how agentic systems fail in practice, from prompt injection and tool misuse to complex multi-step breakdowns, and how leading teams are advancing red teaming with continuous testing, expert evaluation, and large-scale adversarial simulations.
Register here: https://t.co/WBwDM2HKb2
Every breakthrough in healthcare AI is built on a foundation of human expertise.
We collaborated with our friends at @eightsleep and @prenuvo on a write-up exploring where medical AI is heading. The article covers three angles:
1) How human expertise shapes reliable clinical AI
2) What continuous biosignal data from sleep can tell us about long-term health
3) How imaging is evolving from a one-time diagnostic into a longitudinal health map
Full article linked in the comments.
The micro1 referral program has now surpassed 1,000,000 referrals 🚀
We're hiring experts in medical, legal, finance, STEM, coding, and more to help train AI models.
Know someone who might be a good fit? Send them our way and earn $100–$3,000 per successful hire.
Link to register in the comments.
Introducing Prospera: a benchmark that tests AI agents on real federal tax returns, designed by our research team in collaboration with CPAs and industry-leading tax professionals.
A complete federal return requires dozens of source documents, hundreds of interdependent calculations, and no room for errors. We evaluated GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro with no hints on which forms to file, scored against 20+ expert-authored criteria per return.
Here’s the Results (Pass@3):
-GPT-5.4: 28%
-Gemini 3.1 Pro: 18%
-Claude Opus 4.6: 16%
To put those numbers in context, the tasks in Prospera weren't obscure edge cases. Filing a federal tax return is something millions of Americans do every year, yet 44% of evaluation criteria failed across all models.
Full report linked in the comments.