The last few months I have been working on a new Benchmark.
Introducing AutomationBench. Trying to measure the cutting edge of model's capabilities in real world business workflows across multiple apps and noisy data.
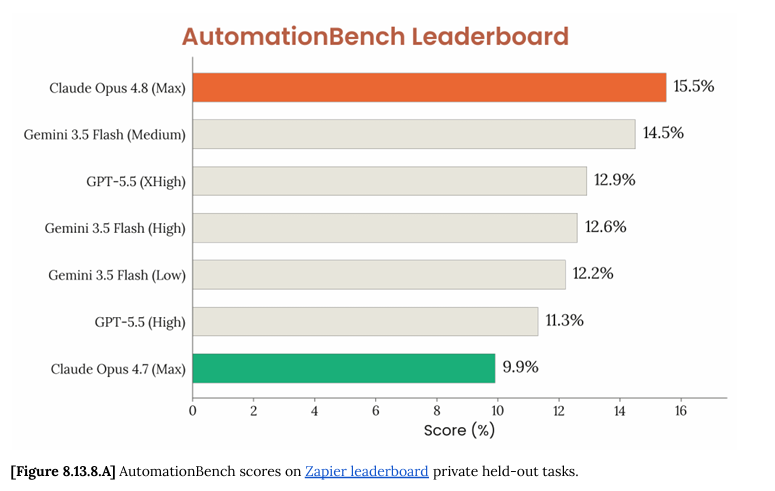
The best models haven't beat 10% yet.
@AndrewWarner@briandecoded@jspujji Good question!😄
I did experiment with this on myself to validate many of the benchmark tasks. It is very time consuming. Never did make it though ~600.😅
The public dataset is available for anyone who wants to give it a shot though! https://t.co/2kgLyzJHU8
Fable 5 seems better than Opus in every way. Like Opus is to Sonnet. It works smarter rather than harder.
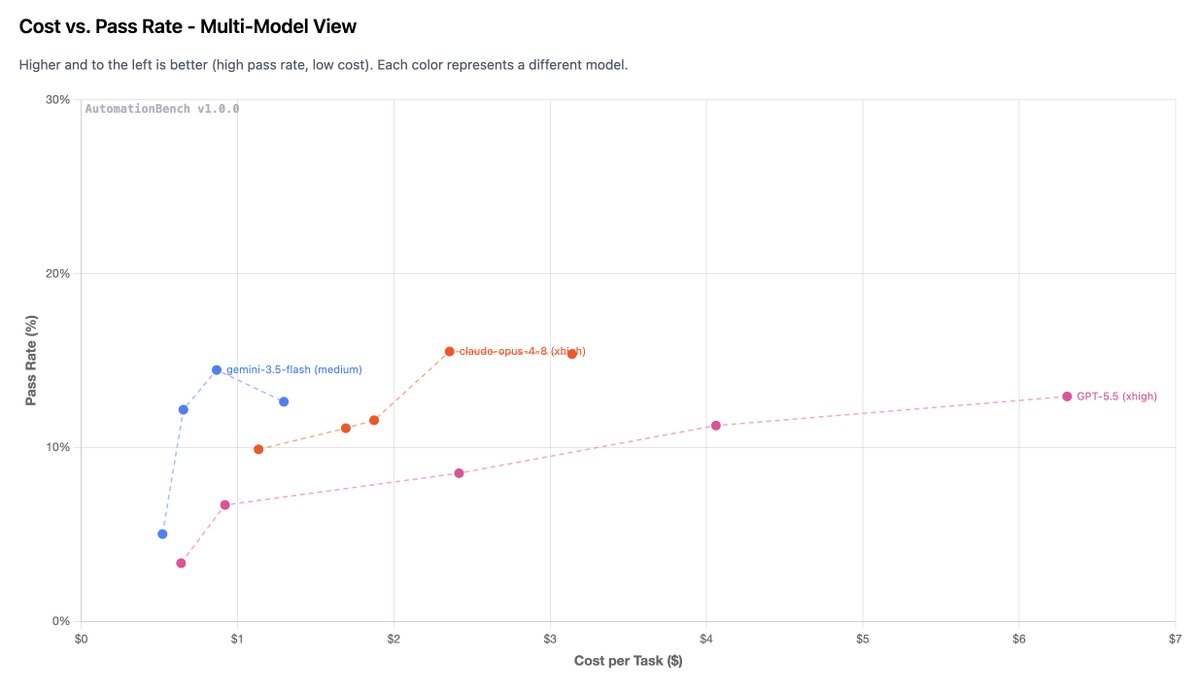
Cost is 2x Opus but cost per task was only 17% more on max reasoning! Fable is much more efficient with tokens than other models. ~1/2 the cost of GPT 5.5 xhigh.
Claude Fable is here: the first model in their new Mythos series.
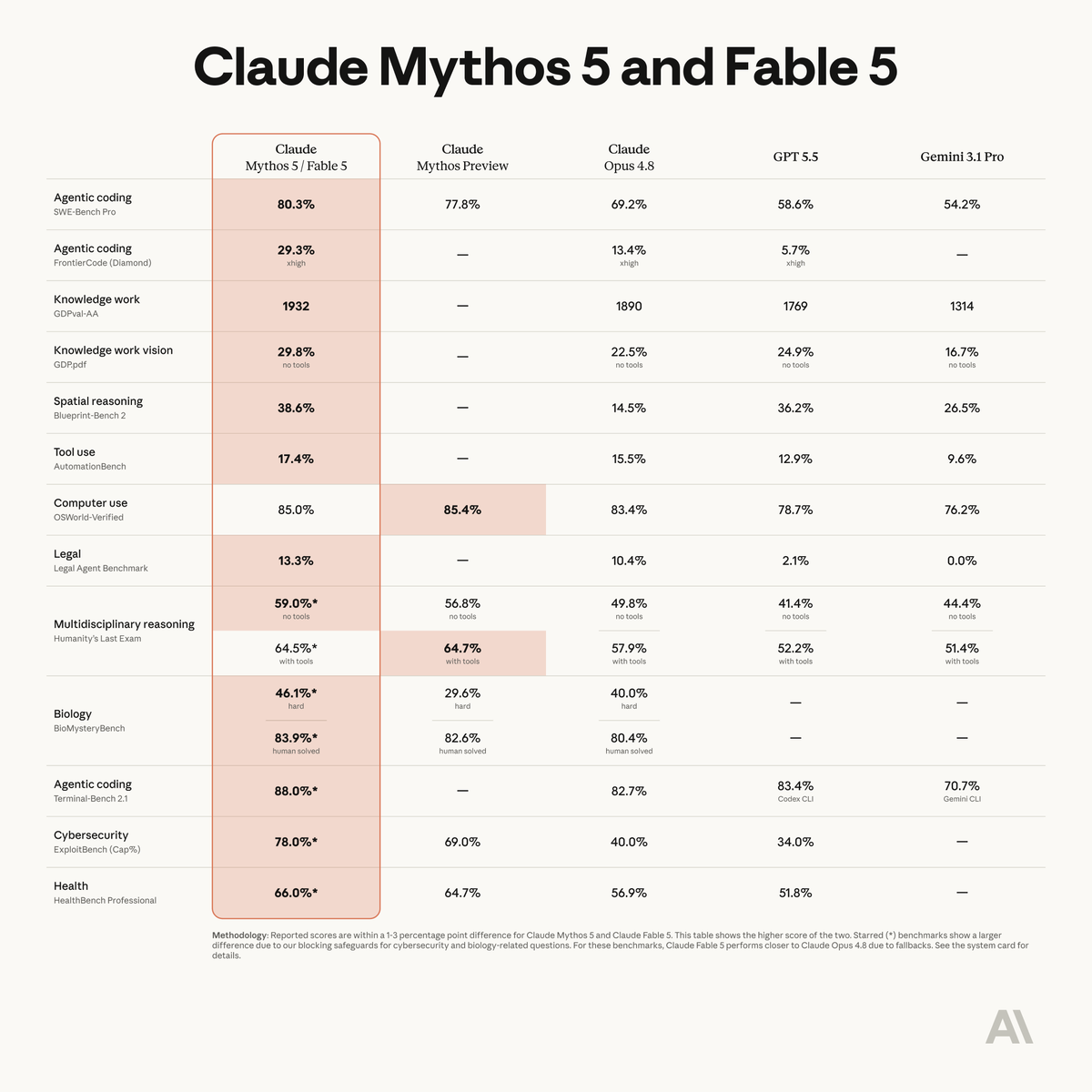
It's the new top score on @Zapier's AutomationBench at 17.4%, just two weeks after Opus 4.8 set the record at 15.5%.
Our AutomationBench measures what enterprises actually care about: can a model do the work? Find the right CRM record, send the right follow-up, update the right system without breaking anything?
We tested 600 tasks across 6 domains. Here’s what we saw:
Fable knows when to work smarter instead of harder. That means fewer timeouts and fewer wasted tokens in production.
EXAMPLE: One task asked the model to reconcile employee benefits across countries. The HR system's benefit-plans endpoint returned a 404. Fable hit it once, immediately pivoted to the team's spreadsheet and inbox, found the plan data there, and finished the task. Meanwhile, Opus moved on and missed a key detail.
That's the Fable pattern. It follows complex instructions precisely (especially the "leave these ones alone" kind), and when it hits a dead end, it goes looking somewhere else instead of spinning its wheels and wasting tokens.
PRICING: You may have seen that Fable is 2x the price of Opus. But that's the model rate, not the task cost. In Zapier, Fable came in at $3.67 per task at max effort, only 17% more than Opus 4.8 max at $3.14.
tl;dr:
Who should immediately upgrade their workflows from @claudeai's Opus to Fable?
- Operations & HR
- Long Horizon Tasks needing reliability and autonomy
- Any workflows where precision + accuracy matter more than cost
🚨 Anthropic released Claude Fable 5
It's Mythos, but safe.
The BIG question: Is it dependable enough to use apps to grow your business?
@wadefoster's team at @zapier ran it through 600+ real-world business uses.
Key results:
1. It stays on track - if you ask it about a specific topic in a specific Slack channel, it won't merge data in from other channels and topics.
2. It's the most resourceful - They told it to get HR data from an API that was down. It quickly switched from using the failed API to searching email & spreadsheets. (GPT 5.5 hit the down API 22 times!)
3. It routes intelligently - They asked it to take leads from multiple sources and send each to the right salesperson. It kills at operational tasks like that.
BUT:
1. For sales and marketing tasks, GPT 5.5 is still more dependable.
2. Fable is crazy expensive ($3.67/task vs $0.87 for Gemini 3.5 Flash)
If you love numbers (like me) the AutomationBenchmark leaderboard is below.
Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
@wadefoster Today learned that some of these models like Kimi K2.6 do not actually accept Reasoning Effort. The provider we used for running these handles that behind the scenes. So Max and High being different was just run to run variance rather than actual reasoning effort.
@AndrewWarner@zapier Thanks for having me on!
More info on AutomationBench: https://t.co/BZrEEOQciw
Github Repo where anyone can run it themselves: https://t.co/j7ZbLF45cT
White Paper: https://t.co/RVbSBYTYrg
Opus 4.8 is doing what 4.7 refused to do.
4.7 refused tasks related to:
• diversity hiring
• finance
• paychecks
Said "too risky."
@zapier tests every model by asking it to do a set of tasks and sees how many they get right.
I asked the guy who runs their benchmark work to teach me what each model can do and where they fail.
4.8 does the most multi-task work well, but it's not the winner for every task.
@zapier Gemini Flash was cheaper per task, but Opus is a very efficient model for tokens. Gemini 3.5 Flash hardly called tools in parallel whereas Opus did more often than not. This meant Opus needed half the number of input tokens and steps.
@wadefoster@AnthropicAI Gemini Flash was cheaper per task, but Opus is a very efficient model for tokens. Gemini 3.5 Flash hardly called tools in parallel whereas Opus did more often than not. This meant Opus needed half the number of input tokens and steps.
AutomationBench tests how models perform on the trickiest, stickiest real-world workflows we know customers are actually trying to automate. 600 tasks, 6 domains, deterministic scoring.
And today our scores are featured on @AnthropicAI's official launch scorecard.
Opus 4.8, the first model to break 15% on AutomationBench, is now live in Zapier!
It handles complex HR, Finance, and multi-app workflows better than anything else we've tested: refusals dropped from 20% to 4%
Opus 4.7 would see a sensitive task and stop, but 4.8 keeps going
@tobihanl@wadefoster@GeminiApp Yeah, AutomationBench has a maximum of 50 steps allowed. Up until recent models, this was almost never hit but High reasoning hit that limit 38% of tasks so unfortunately was limited by that. We will raise the limit for a future version. High likely would score higher otherwise.