If you want to run this on your own codebase, check out Detail.
The biggest difference vs Ramp's scan pipeline is that Detail has an additional feedback loop: we track which vulns get fixed, and we use that data to prioritize better going forward.
So when you scan your code with Detail, we're making use of fix / no-fix decisions from across our customer base.
In fact, we don't even look for vulns in particular – just high-value bugs. But if you find many bugs and optimize for which ones get fixed, you'll organically find a lot of vulns, because when a vuln comes in that is bad (and real) engs jump all over it.
You can think of this as the bitter lesson coming for security scanners. Don't write a scanner that looks for SQL injections, write a scanner that looks for bugs and do a good job picking the bugs that engs are going to fix, and you'll end up finding the SQL injections.
Really impressed with @detaildotdev.
Connected it to GitHub, received an email with a list of bugs a few hours later.
All real bugs. One critical.
Will make my overwhelmed indie hacker life much easier.
The hard part about building a bug finder is that every codebase has thousands of bugs, and the vast majority do not matter.
Human attention is the bottlenecking resource in building software right now, so the right goal is: how do we pick out the 1% of bugs that are important, and put those ones in front of engineers?
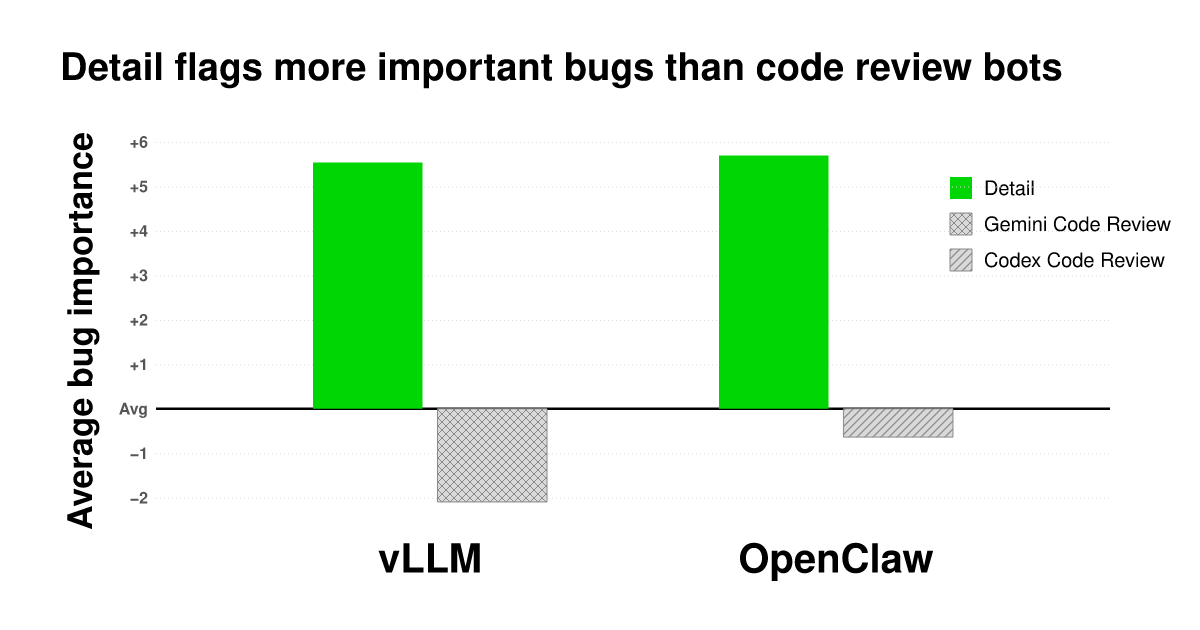
Fun post here about how we used a chess tournament to determine that the bugs we're finding are several sigmas more important than the typical CR bot comment.
We ran a chess tournament for bugs.
The question we wanted to answer: are bugs from Detail "important"? How do they compare to what code review bots catch?
One of the most important ways we benchmark ourselves is that we want the bugs we generate to be significantly more important than the typical comment from a code review bot.
We took a week of findings from CR bots running on OpenClaw and vLLM, plus findings from Detail on the same week of changes. We put them through an LLM-as-judge tournament.
We fed the head-to-head results into a Bradley-Terry model to compute ELO ratings for bugs. Out comes a global ranking from most to least important.
Awesome exploration from @sachiniyergreen below, with methodology, charts, and a PostHog secret exfiltration vuln that four code review bots missed.
I'll update the site!
The backstory, if you were curious:
- We built a bug finder and optimized around finding bugs that were confidently worth an engineer's attention.
- One of the main signals we use for whether a bug is worth an engineer's attention is: if we put a bug in front of an engineer, will they fix it? (We track this and optimize against it.)
- Security vulns perform very well here. So, organically, Detail started finding a lot of vulns.
We aren't security researchers by background. We aren't building SAST or managing your supply chain. We're trying to find bugs you'll care about, and low-hanging vulns are a category of bugs that you'll probably care a lot about. We stumbled into this use case, and we're figuring out how to serve it better.
In some sense, this is bitter lesson in action: don't build a security scanner, instead build a codebase defect scanner and optimize for what engineers judge to be worth fixing, and in practice you'll find a lot of the vulns that matter as part of doing that. But we find other high value issues too: data loss bugs, billing mistakes, etc.
We have spent over £30k on annual pen tests over the last 3yrs. They found things, but nothing major.
In the last months, https://t.co/5vkny9csbH has uncovered nearly 10 complex high-sev auth/idor vulns on our endpoints.
Less than $500 bucks.
@chadwhitacre@_m27e It's satisfying to watch, which matches the feeling we want our product to give you: the "ahhhh that's better" that people get from powerwash / weedwacking / deepclean videos. Except for your codebase.