Claude Tag is great for delegation, but personal chat remains valuable for clarification
Sometimes you are brainstorming and this requires fast back-and-forth, correction, and reframing
So a useful pattern:
1. use https://t.co/HikqArMp0f to clarify the intent in a private chat
2. ask it to send the clarified task to the right Slack channel via @SlackHQ MCP, tagging @Claude
private clarification first => shared execution second
Introducing https://t.co/ymuN68eFXG Dev Station: every workspace now has a persistent, multi-repo dev station that tasks fork from.
@twill_ai station is now the source of truth for the project: repos connected, dependencies installed, env vars configured, dev/test servers running, and project context warm.
Agents and humans can both configure it, so the workspace keeps getting closer to the way your team actually builds software.
Tasks are no longer independent cold starts. Each task forks from the station’s current working environment into its own isolated sandbox. Powered by @daytonaio.
That means:
• No cold-start, so tasks start/finish faster.
• Multi-repo work across frontend, API, and shared libraries.
• Less setup work for agents, which means fewer tokens spent re-setting the dev env.
This is the model we think coding agents need: a persistent workspace that stays warm, then forks cleanly for each job.
Try it at https://t.co/BjDTPcquKi
https://t.co/ymuN68fdNe update: new runtime, new features!
We rebuilt the runtime that drives every Twill task and open-sourced it as agentbox 👉 https://t.co/u3oTBHrr2W
New:
- Live preview pane: see your app run, open a terminal, watch entrypoint logs
- Reasoning level control (per task)
- Token-level streaming of agent responses
- Message editing (rewind a run from any prior message)
Faster:
- Sandbox setup ~5x faster
- Follow-up response start ~4x faster
More info here: https://t.co/ZFdWS5kvfX
AI research gets smarter, so progress gets faster.
This becomes an environments + success criteria game around verifiable objectives.
Exponential slope incoming.
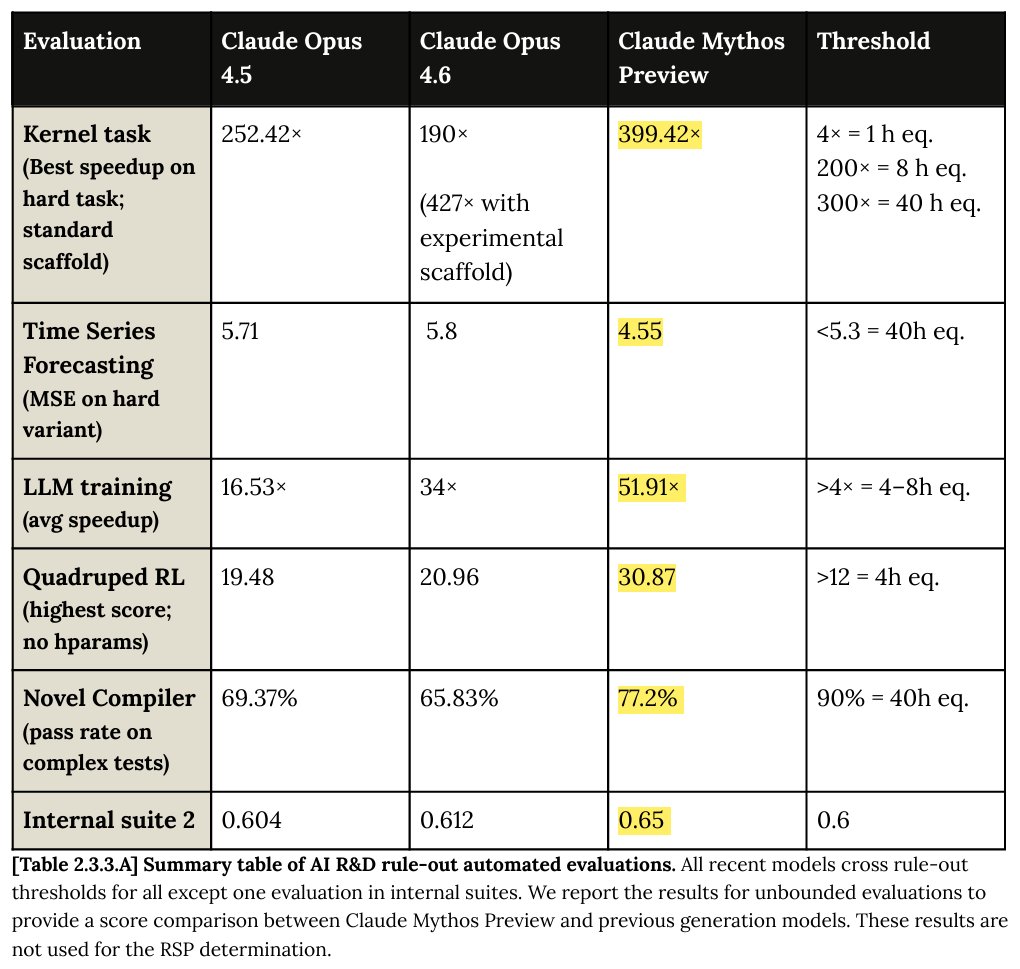
Mythos speeds up AI research by up to 400 times
A 300X speedup over the baseline requires 40 hours of work by a human expert
It also clears the >8h threshold of human equivalent work time on ALL tasks!
New mode in Twill: Claude codes, Codex reviews. Until they converge.
Ralph loop is a new opt-in mode for complex tasks where you want more rigor than a single agent pass. You select it and set a budget when you create the task.
𝗛𝗼𝘄 𝗶𝘁 𝘄𝗼𝗿𝗸𝘀
1. You set a budget and describe the task
2. A criteria agent explores your repo and proposes acceptance criteria
3. You review, refine, and approve
4. Claude implements against the criteria
5. Codex verifies the result against the criteria. Pass or fail.
6. On fail, the feedback goes back in. Claude continues to work.
7. Loop runs until criteria pass or the budget runs out.
Two things make this different from a normal agent run.
𝗩𝗲𝗿𝗶𝗳𝗶𝗮𝗯𝗹𝗲 𝗰𝗿𝗶𝘁𝗲𝗿𝗶𝗮 𝗯𝗲𝗳𝗼𝗿𝗲 𝗰𝗼𝗱𝗲. Separating "what does done look like" from "write the code" forces the ambiguity to surface upfront, in a document you can read and edit, instead of mid-implementation when it's expensive.
𝗖𝗿𝗼𝘀𝘀-𝗺𝗼𝗱𝗲𝗹 𝘃𝗲𝗿𝗶𝗳𝗶𝗰𝗮𝘁𝗶𝗼𝗻. The verifier gets the criteria and the repo state. It has no memory of the implementation decisions, no attachment to the approach. It reads the code cold, the same way a reviewer sees a PR for the first time. A model checking its own output tends to confirm what it intended, not what it produced. A different model doesn't have that bias.
The name comes from @GeoffreyHuntley's Ralph loop pattern, a bash one-liner that runs a coding agent in a tight loop with full context resets. Same iterative philosophy. Different mechanism: structured criteria up front, cross-model verification at each pass.
my most common instruction right now is forcing the main agent to use subagents
"use an async subagent expert in X to do Y" or "use a team of agents"
for researching, planning and coding-reviewing
Introducing Gemma 4, our series of open weight (Apache 2.0 licensed) models, which are byte for byte the most capable open models in the world!
Gemma 4 is build to run on your hardware: phones, laptops, and desktops.
Frontier intelligence with a 26B MOE and a 31B Dense model!
Introducing Twill Clone 🤖
Clone any web app. Fully tested. Pixel-perfect output. Full source code.
Point Twill at any public URL and watch our agent reverse-engineer user stories, design system and inner logic, and ship a perfect rebuild.
Try it: https://t.co/uxVZQrF9iN