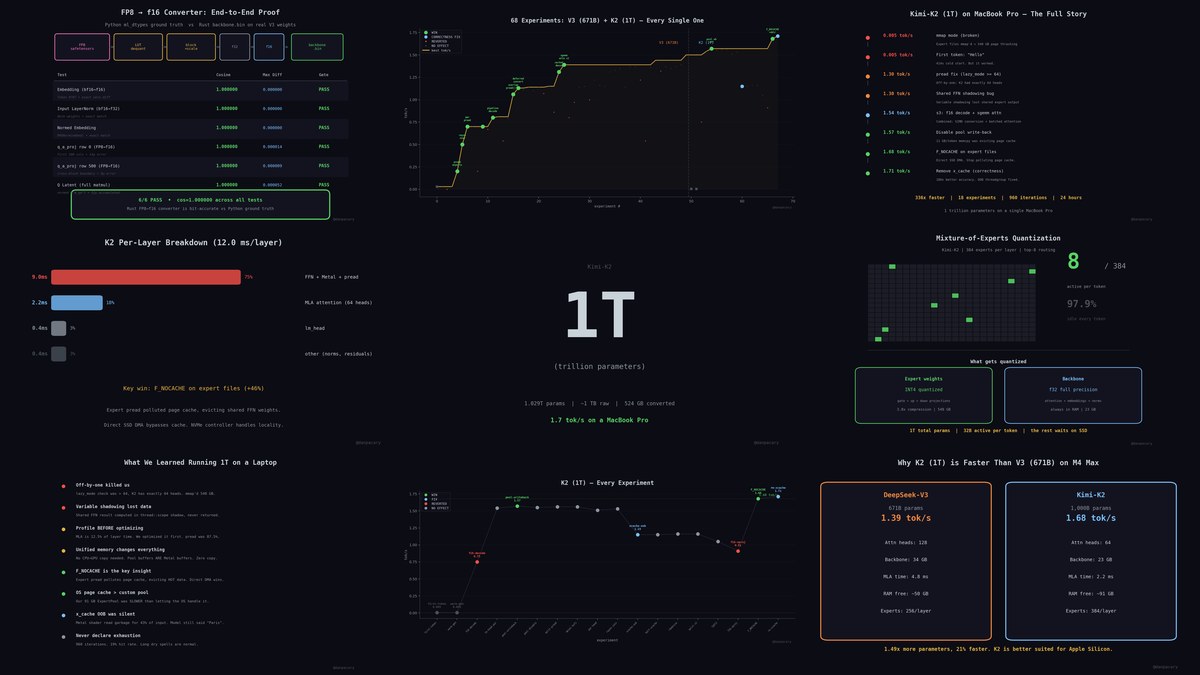
I got a 1T (trillion) parameter model running on my MacBook Pro.
Kimi-K2. 1.029T params.
~1 TB raw weights.
524 GB converted.
~1.7 tok/s.
Yesterday it was 671B. Today it's 1T.
Same laptop. Same M4 Max. No cloud.
When I say we: I mean Claude and me.
Most “AI image apps” are just screenshots traveling to a server.
I wanted:
• weights on device
• generation on device
• images never leaving the phone
So I spent the last week turning sd.cpp into an actual iOS developer experience.
SwiftPM install. One simple generate() call.
Completely open sourced.
This is an interesting perspective on the evolution of software
I’m curious to understand what the integration of agents will look like as this is becoming a more prevalent feature that will be a non-negotiable in the near future
However, the issue that I see, is this a layer of infrastructure as certain companies fall under regulations that require data sovereignty
This means that certain sectors will need on premise compute.
“on premise is the new cloud compute”
With the rapid advancement of source models, future software (for specific types of companies) will be required to include an orchestration layer to leverage on premise infrastructure.
Pharma companies are all about life saving drugs. But from the perspective of software, pharmaceutical companies manage and author a series of documents of ever-increasing complexity, accuracy and criticality.
Viewed in this way, the operating system for the pharma industry can be reimagined as a content management platform that helps scientists and pharma execs manage pre clinical, clinical and post clinical development of drugs and their go to market.
We are building this exact suite for a multi billion dollar pharma company.
The result is more money spent on lifesaving drug R&D and a more streamlined interface with regulators because the documents required to move along their process are increasingly pristine and machine verifiable.
This doesn’t just apply to pharma. We are doing similar things in manufacturing, finance, aerospace & defense and medical devices.
8090’s practice and our Software Factory platform excels particularly well in regulated environment where vibe coding won’t get the job done.
If you want to see if we can help you, please be in touch.
[email protected]
Finally able to talk about what I've been heads-down on for 6 months at @nvidia 🦀⚡
We just open-sourced cuda-oxide — an experimental rustc backend that lets you write CUDA kernels in pure Rust.
No DSLs. No FFI. No source-to-source step. Single source.
Short🧵👇
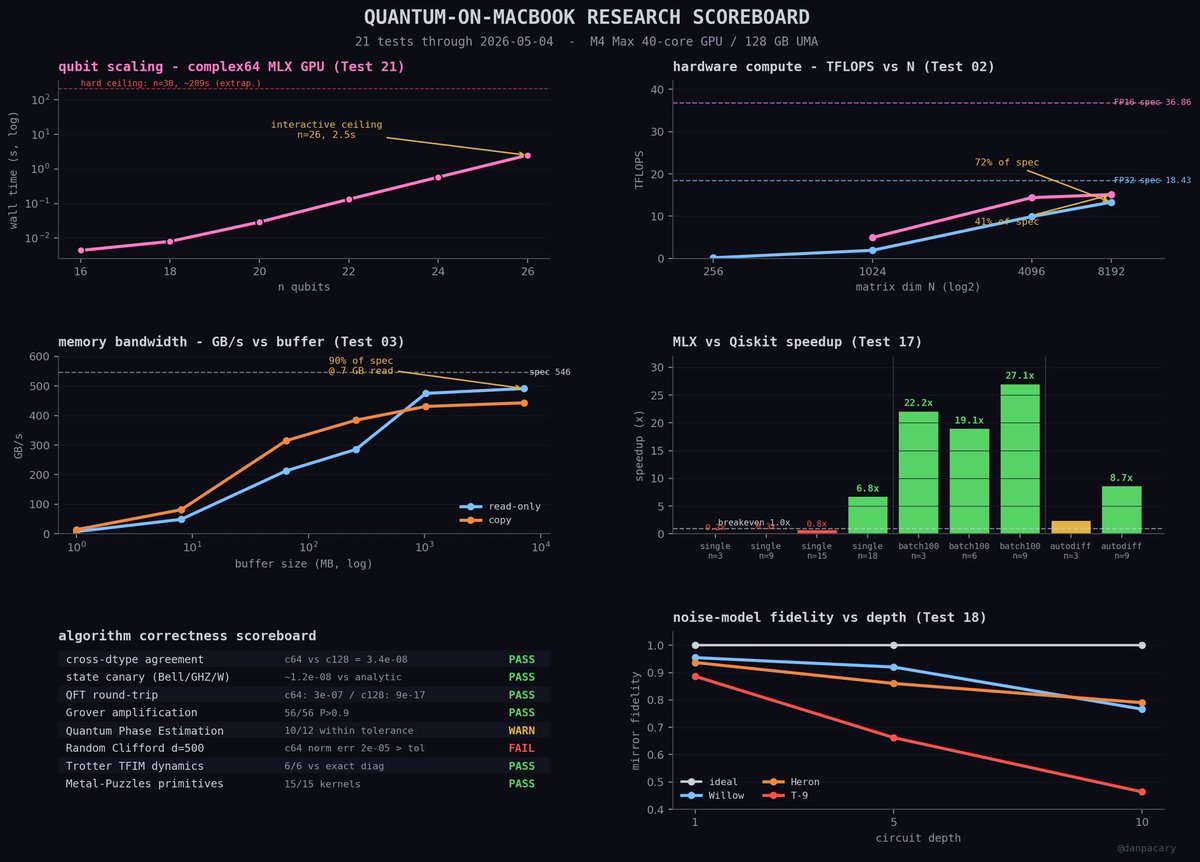
I got bored/curious so
started replicating quantum computing sims on the macbook
nothing novel. just running existing tests against MLX on the M4 Max to see what the hardware actually does
21 tests in. some highlights:
Systems are everything now.
Your ability to understand and design great system architecture will determine your success as a “builder” {software engineer} in this next era of software
To Jensen’s point on the all in podcast
~We now need people who define great systems, iterate quickly and understand how to leverage ai systems.
Writing code is a thing of the past.
Every time I see a tweet saying “I can vibe code this in a weekend” - I think of the slack notification system..
It takes time, persistence and effort to get the details right.
Sure, a lot of simple workflows will get vibe coded away. And maybe you can put this in Claude Code and get the code right in one shot.
But quality, depth and great systems will still have value and take time. You can’t vibe code lessons.
Now and forever.
Here's the fix:
type(module).__call__ = patched
Python resolves obj(x) via the type, not the instance. The dunder I set was silently ignored.
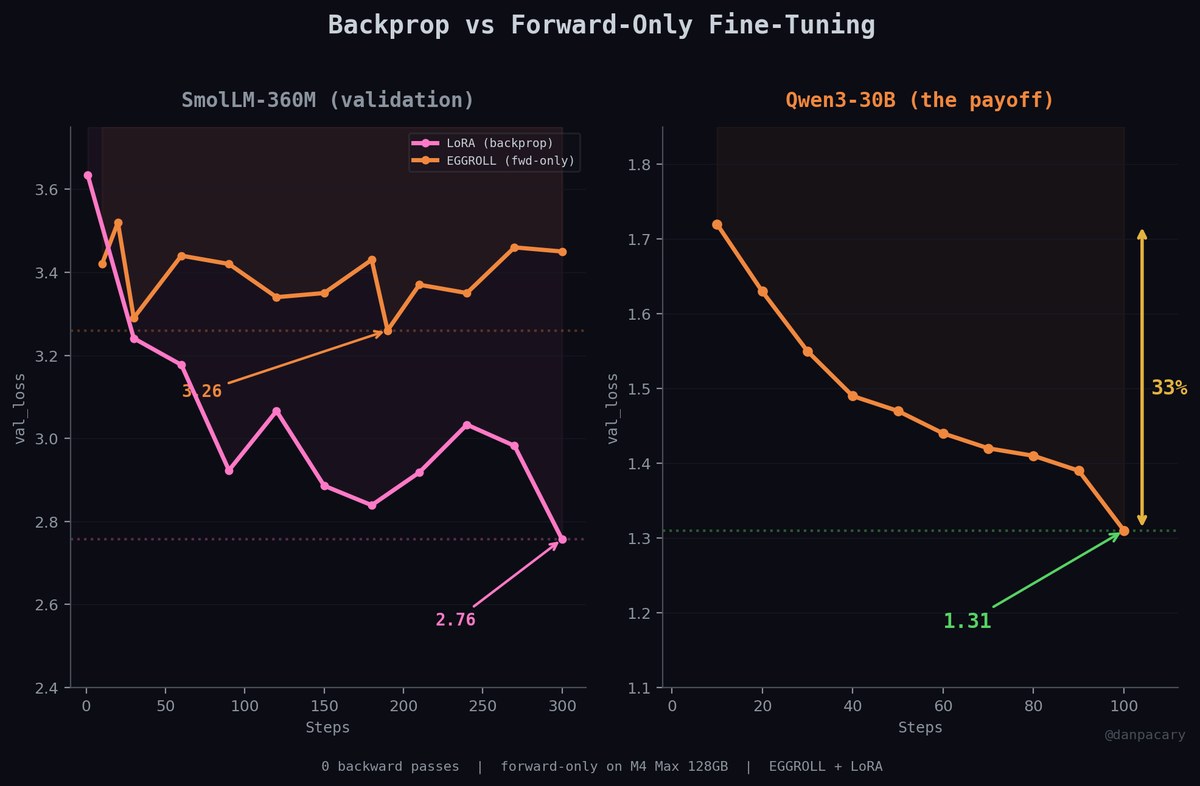
Post-fix A/B: base+adapter +0.0005 nats. Below noise floor.
Now I can actually test if eggroll works on 30B.
Update: I've been training a LoRA on Qwen3-Coder-30B-A3B for a week.
It wasn't actually training.
Every forward pass was ignoring the adapter.
Every "best val_loss" I logged was batch noise.
I caught it with one assertion.
I added one line to the training loop:
assert max(losses) - min(losses) > 1e-6
After step 1: 0.0000.
Every population member returned the exact same loss. Identical.
The perturbations weren't reaching the forward pass.
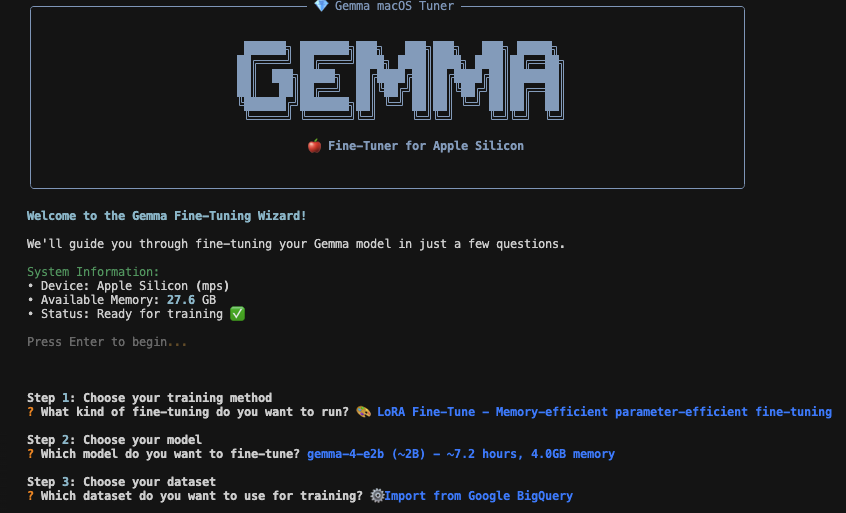
Introducing...
Gemma 4 Multimodal Fine-Tuner for Apple Silicon
- LoRA fine-tunning toolkit for Gemma LLM
- runs locally on macOS via PyTorch and Metal
- streams data from Google Cloud to your machine
- fine-tune on audio, image and text
- easy-to-use CLI wizard
If you want to fine-tune the new Gemma 4 on text, images, or audio without renting an H100 or copying a terabyte of data to your laptop, this is the only toolkit that does it all on Apple Silicon.
mostly principled, with one heuristic:
- noise sampled from N(0, sigma²I) per perturbation. standard
- antithetic pairs (+eps and -eps) for variance reduction. standard NES, halves variance for free
- z-score normalization on raw fitness. makes the gradient estimate scale-invariant
- 1/sqrt(rank) scaling on the A matrix only. this one is a Kaiming-style heuristic, not analytically justified. probably helps but i haven't ablated it
does it matter? antithetic alone is a meaningful win. without z-score, sigma becomes a load-bearing hyperparameter and tuning gets brittle.
obviously claude is helping substantially with a variety of aspects - this is def one
@RolandTweats EGGROLL is the optimizer. LoRA is the parameterization being optimized
think of it like:
- AdamW + LoRA adapters → standard LoRA fine-tuning
- ES + LoRA adapters → EGGROLL LoRA fine-tuning
different optimizer on the same target.
@thkostolansky for ranking implementations against each other on the same data: yes. that's what i used it for
for proving the model is actually better at code generation: no. would need HumanEval
i'm not claiming the trained model is better at coding tasks.
@guintherk@yp0c5t correct. good distinction
ES adds a different stochasticity on top: random search directions in parameter space. the data sampling can also be stochastic (and is in my setup). two layers of stochasticity, different purposes
@tekyesilolsun honestly doing more experimentation vs real-world implementation
a lot of what i am doing doesn't translate well to daily functionality
it's more about exploring the limits
Now porting to Rust via Rustane. ANE + GPU + CPU. Bare metal Accelerate and Metal kernels.
~700 lines of Rust. MoE forward path. LoRA injection. EGGROLL on Qwen3-30B end-to-end.
Apple just dropped the SSD paper: temperature-scaled loss, 42% to 55% on code benchmarks. Next up.
because i'm targeting Apple's Neural Engine, which is inference-optimized. backward passes through ANE are limited (small tensors, restricted ops)
ES skips backprop entirely. 32 forward passes is more compute per update, but every forward is ANE-friendly. activation memory drops to zero. gradient tape gone.
again, focused on ANE here