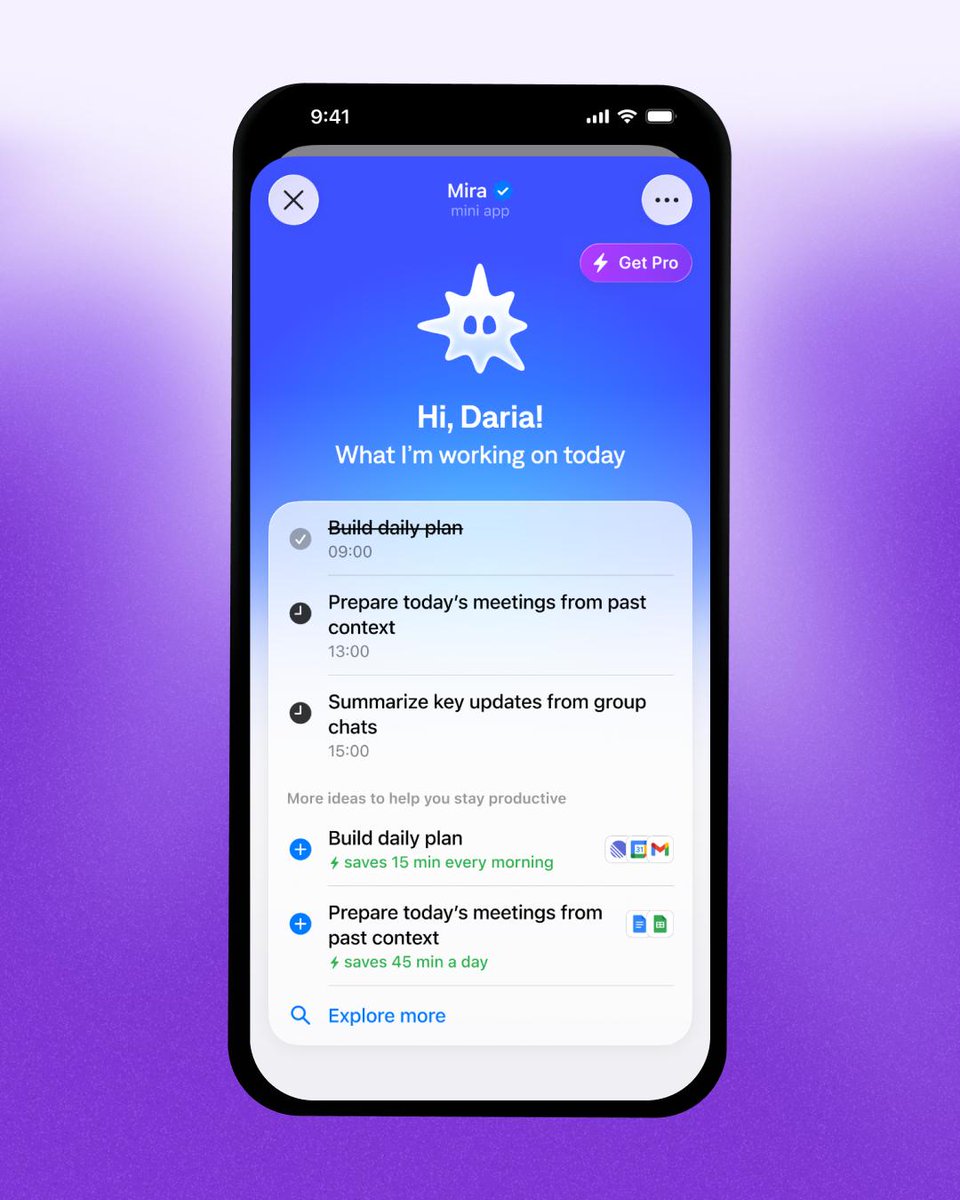
Mini Apps in @telegram is really great UX btw
We made @mira_t_me Agent Home Screen. Check current agent state, controls and results without leaving the chat.
Chat = intent, Mini App = interface 🔥
i think we found the missing UI for AI agents in iMessage.
and it's been staring us in the face this whole time...
the challenge is you constantly have to ask what the ai is doing.
so i started experimenting with live updating the Dynamic Island while you chat:
Introducing Memory Stargraph, an AI memory Visualizer for GBrain 👏
Memory Stargraph is a local web service for exploring a GBrain knowledge base through an interactive star-cloud entity graph.
I built it because my local agent clusters now share the same GBrain-backed memory infrastructure across multiple hosts and agent runtimes. Instead of each agent carrying more context forever, they can rely on a shared, evolving knowledge graph that stays compact, searchable, and useful over time.
Memory Stargraph makes that shared memory visible.
You can see what agents have created in GBrain, inspect entities, explore relationships, create new nodes, connect them, modify links, attach media, and follow the map as it loads new neighborhoods on demand.
It is part debugging tool, part knowledge browser, and part “wait, the agents remembered all this?” moment.
It’s also surprisingly mesmerizing.
Many thanks to @garrytan for his GBrain work, and I am very happy to be among the serious users of #GBrain!
If you’re interested in setting it up for your own agents:
https://t.co/67RqdkCDre
#AI #AIAgents #KnowledgeGraph #LocalAI #OpenSource #BuildInPublic #Codex #OpenClaw
AI usage can grow exponentially, but your infrastructure costs don’t have to. We think about this a lot at @mira_t_me
At 1M+ users, even a tiny inefficiency gets multiplied fast. One extra model call or oversized context window may look harmless for a single user, but at consumer scale it becomes real infrastructure cost.
So the goal is not to make people use less AI. It’s to make every AI action smarter: better routing, leaner context, stronger caching, and the right model for the right job.
How to keep AI spend flat while token usage grows exponentially: Not with friction and spend alerts. With better defaults, routing, and caching.
Better Defaults (not Usage Caps) – Engineers can choose any model they want, but defaults matter. We’re experimenting with defaulting to open weight models like GLM 5.2 and Kimi 2.7 through our LLM gateway, while still encouraging engineers to choose the right model for the task. 91% of our employees were never hitting their usage caps, so instead of lowering caps and driving up alerts, we're moving to cheaper defaults. Note that code reviews use a diversity of models, so they can check each other's work.
Better Routing – In our custom harnesses, we preprocess prompts and route to the best model for the job, considering cache hits and model pricing. For instance, you may want a frontier model for planning, but not for execution where they can be overkill. Ultimately, humans shouldn't be choosing models - AI can automate this task.
Better Caching – Cache misses are the easiest way to drive your cost up. All of our requests are cache aware, so we’re reusing a warm cache wherever possible. For example, our cache hit rate went from 5% → 60% in LibreChat once properly implemented.
Keep Context Lean – Start fresh sessions when switching tasks. Scope file context narrowly. Disconnect unused tools. Don't just compact. The goal isn't fewer tokens used, it's fewer tokens wasted.
Better Visibility – Our engineers can use as many tokens as they want, from whatever model they want, but we’ve made usage visible – and the more you spend on AI, the more impact we expect.
The goal isn't to suppress usage. It's to build the infrastructure that makes exponential growth sustainable.
Putting this into practice has cut our AI spend nearly in half, while our token usage continues to grow.
Introducing Claude Tag, a new way for teams to work with Claude.
In Slack, Claude joins as a team member with access to the channels and tools you choose. Tag Claude in and delegate tasks to it while you focus on other work.
New market map: AI assistants in iMessage 📱
The next major interface for consumer AI? Text messages.
People don’t want to open an app every time they need help - they want a contact they can text like a friend.
My roundup of the assistants + infra providers below 👇
Going live today with Daria (@ykvlv_ai), CEO of Mira.
We’ll talk AI agents, why Telegram is becoming a natural home for them and how @mira_t_me turns messaging into an AI-powered execution layer.
Plus, we’re giving away 3 Mira Pro.
6PM UTC.
Live on X @giooton
Live on Telegram https://t.co/rQNNiFFpCc
PULL UP.
🚨 BREAKING: @telegram just shipped native rich text support for AI agents!
Tables, slideshows, LaTeX, real-time streaming, guard bots — all in one update 🔥