Local AI hardware = capacity × bandwidth × software stack
- Capacity tells you what fits
- Bandwidth tells you how hard the box can breathe
- The software stack tells you how much of the spec sheet you can actually cash out.
Hardware by Memory Bandwidth
- Mac Studio M3 Ultra: up to 512GB @ 819 GB/s
- RTX PRO 6000 Blackwell: 96GB @ 1792 GB/s
- RTX 5090: 32GB @ 1792 GB/s
- RTX 4090: 24GB @ 1008 GB/s
- RX 7900 XTX: 24GB @ 960 GB/s
- Radeon PRO W7900: 48GB @ 864 GB/s
- AMD Radeon AI PRO R9700: 32GB @ 640 GB/s
- Intel Arc Pro B65: 32GB @ ~608 GB/s
- Tenstorrent Wormhole n300: 24GB @ 576 GB/s
- Tenstorrent Blackhole p150: 32GB @ 512 GB/s + 800G
- MacBook Pro M5 Max: 460-614 GB/s
- MacBook Pro M5 Pro: 307 GB/s
- DGX Spark: 128GB @ 273 GB/s (coherent + CUDA)
- Mac mini M4 Pro: 273 GB/s
- Ryzen AI Max / Strix Halo: ~256 GB/s (~96GB usable GPU)
- MacBook Air M5: 153 GB/s
- Snapdragon X2 Elite: 152-228 GB/s
- Intel Lunar Lake: 136 GB/s
- Snapdragon X Elite: 135 GB/s
- Mac mini M4: 120 GB/s
- Arc Pro B60: 24GB @ ~456 GB/s
Verdict
- GPUs are still the bandwidth kings
- Apple wins: stupid amounts of memory, don’t want to shard across GPUs
- Apple loses: when raw tokens/sec & concurrency matter more
- DGX Spark: coherent memory + NVIDIA stack
- Strix Halo / Ryzen AI Max: first real x86 unified-memory contender
- Tenstorrent: fully OSS stack, excited to see this mature
Fitting ≠ serving
Even if it fits, you still pay for
- bandwidth during decode
- KV cache growth
- dequantization
- batching + concurrency
- scheduler quality
- framework overhead
The only mental model that matters:
1. What must fit?
2. What bandwidth tier do I need?
3. What software stack can actually deliver it?
In short:
- NVIDIA → fastest raw speed
- Apple Studio M3 Ultra → biggest one-box memory
- Strix Halo → first real x86 unified
- DGX Spark → coherent NVIDIA dev appliance
- AMD / Intel Arc → rising alternatives
- Tenstorrent → fully opensource stack
Do ask: “which bottleneck am I buying?”
Not: “which hardware is best?”
The next evolution of Hermes Agent is here!
Introducing Hermes Desktop: everything you love about Hermes, now native on your machine.
First demoed in Jensen's GTC keynote, it's now in public preview.
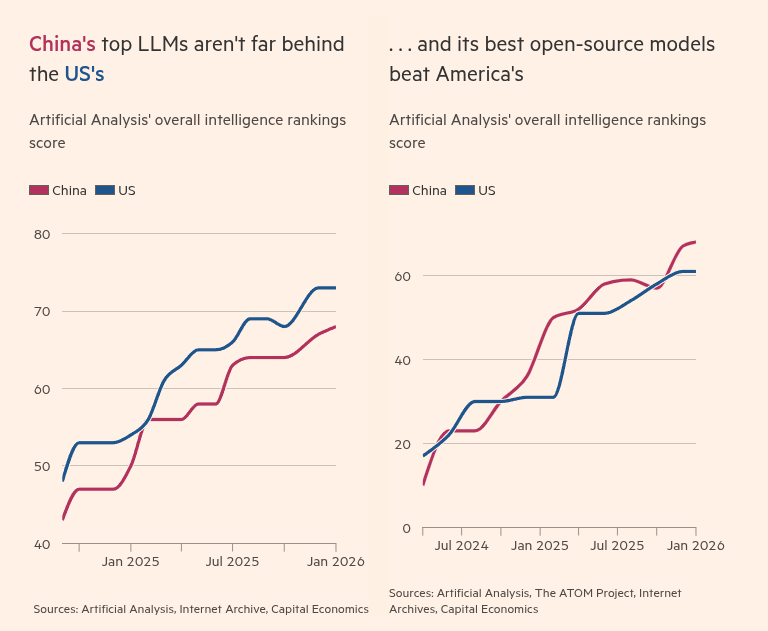
🇨🇳 China’s top models are climbing very quickly and the gap to the best US closed or top-tier models are shrinking fast.
And China’s best open-source models have already overtaken the US.
Open-source models spread through downloads, fine-tuning, and on-prem deployment, so leadership there can translate into faster global adoption even without controlling the top closed models.
Chart from FT
ft .com/content/d9af562c-1d37-41b7-9aa7-a838dce3f571
JetBrains has known for over two months about macOS 15 networking issues. They've posted a support document that's hard to find and are closing related bug reports as "not our problem."
If JetBrains can no longer support macOS, they should stop selling these products.
#jetbrains
‼️⭕️🌉 Achtung Vollsperrung!
Ab sofort Sperrung, Brücke über die Elbe #B172 in Bad #Schandau bis auf Widerruf wegen Einsturzgefahr bzw. Korrosion der Brücke!
☝️ℹ️ Sofortige Sperrung der Elbbrücke in Bad Schandau – Notwendige Maßnahme aufgrund von Längsrissen im Unterspannband
OMG, Mailgun was bought by Sinch! Now you have to re-auth your email to access, but their server is on a spam blacklist (https://t.co/ouu7gZaHRb), so nothing arrives. Support just asks for a service key you can't get without account access! #mailgun#servicehell
It looks like the latest release of TypeScript breaks any AdonisJS application using our ORM (Lucid) - and maybe more.
We recommend that you stay on version 5.4 for the moment.