Happy to announce the first stable release of Wheel of Misfortune. It's a role-playing game for incident management training via simulated outage scenarios. Spin the wheel and enjoy the debugging journey.
https://t.co/SnHPRuySjW
#SiteReliabilityEngineering
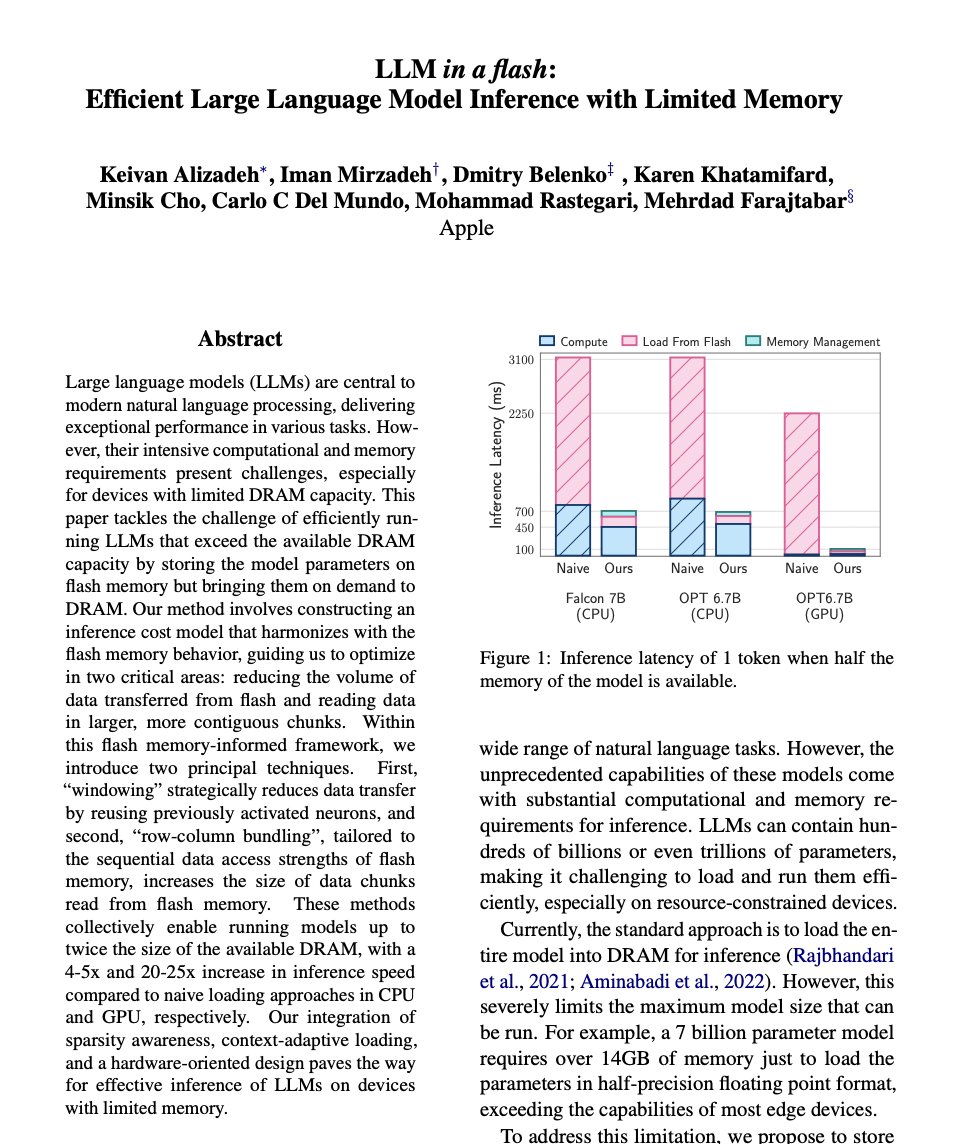
Apple announces LLM in a flash: Efficient Large Language Model Inference with Limited Memory
paper page: https://t.co/SuqHJUQPO9
Large language models (LLMs) are central to modern natural language processing, delivering exceptional performance in various tasks. However, their intensive computational and memory requirements present challenges, especially for devices with limited DRAM capacity. This paper tackles the challenge of efficiently running LLMs that exceed the available DRAM capacity by storing the model parameters on flash memory but bringing them on demand to DRAM. Our method involves constructing an inference cost model that harmonizes with the flash memory behavior, guiding us to optimize in two critical areas: reducing the volume of data transferred from flash and reading data in larger, more contiguous chunks. Within this flash memory-informed framework, we introduce two principal techniques. First, "windowing'" strategically reduces data transfer by reusing previously activated neurons, and second, "row-column bundling", tailored to the sequential data access strengths of flash memory, increases the size of data chunks read from flash memory. These methods collectively enable running models up to twice the size of the available DRAM, with a 4-5x and 20-25x increase in inference speed compared to naive loading approaches in CPU and GPU, respectively. Our integration of sparsity awareness, context-adaptive loading, and a hardware-oriented design paves the way for effective inference of LLMs on devices with limited memory.
If you're SRE or SRE-adjacent, it would be great to spend some time filling out https://t.co/Hjd085lP8u -- one of the few ways we can get cross-company readings on what's happening with the profession.
Thank you for your time in advance!
Are you an SRE looking to make a difference in your org? Use research, data, and math to slay MTTR. Find it in the 2022 VOID Report: https://t.co/DM2FmnfPm2
Just in case you’re looking, my org at Apple is hiring SREs, engineering managers, infrastructure managers, a system’s reliability tech lead, a cloud SRE manager, build engineers and much more. These aren’t full time remote roles, but im happy to provide more info in dms
I'm a big believer that great products are a result of healthy autonomy. It means less interdependencies between teams, strong API/data boundaries, mature capacity planning, the devops model where devs are operators of their services.
@micahlerner@urlichsanais . @dastergon gave a talk at #SREcon21 on the "Lessons Learned Using the Operator Pattern to Build a Kubernetes Platform,"
https://t.co/ILUNcsETPm
https://t.co/V9LFnccVq8
https://t.co/Gilq0N6xvp
USENIX's login magazine very kindly agreed to publish a slightly elaborated, text version of my keynote from last year's SRECon EMEA. Thanks to @lauralifts, @NYCDubliner and @systemician amongst many others for review + support.