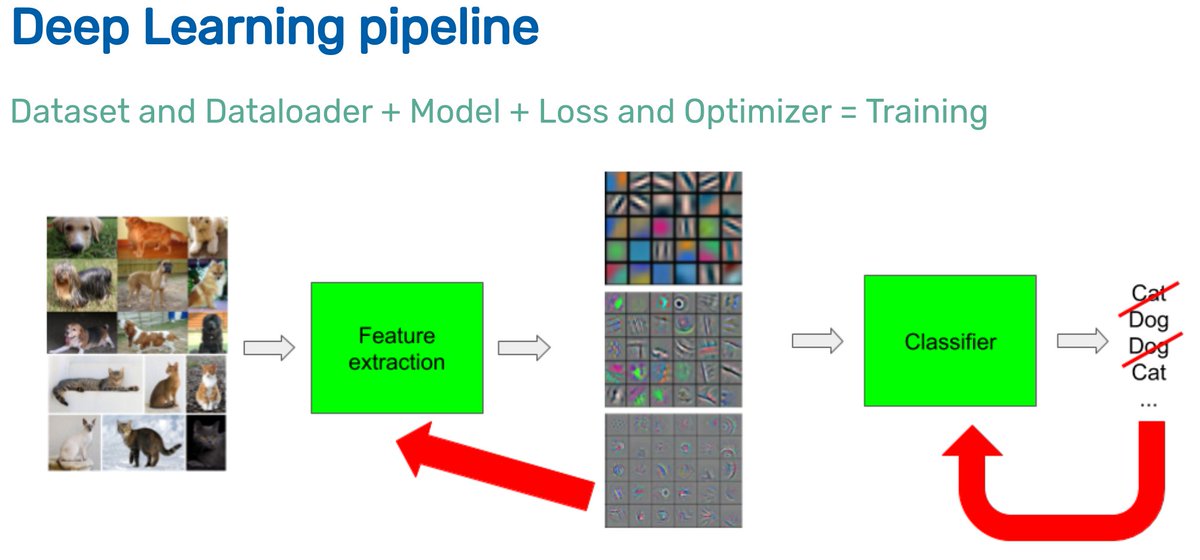
🌻 𝗦𝗲𝘀𝘀𝗶𝗼𝗻 𝟮 𝗼𝗳 𝗺𝘆 𝗽𝗿𝗮𝗰𝘁𝗶𝗰𝗮𝗹 𝗱𝗲𝗲𝗽 𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗰𝗼𝘂𝗿𝘀𝗲: 𝗣𝘆𝗧𝗼𝗿𝗰𝗵 𝘁𝗲𝗻𝘀𝗼𝗿𝘀 𝗮𝗻𝗱 𝗔𝘂𝘁𝗼𝗱𝗶𝗳𝗳
By the end of this session, you'll be able to code your own reverse mode autodiff to train a MLP
code 👉https://t.co/JLGiwnVDCG
🧵
Just uploaded the code for the solution of the practicals so you can check your results:
https://t.co/Yz1ofLTXoA
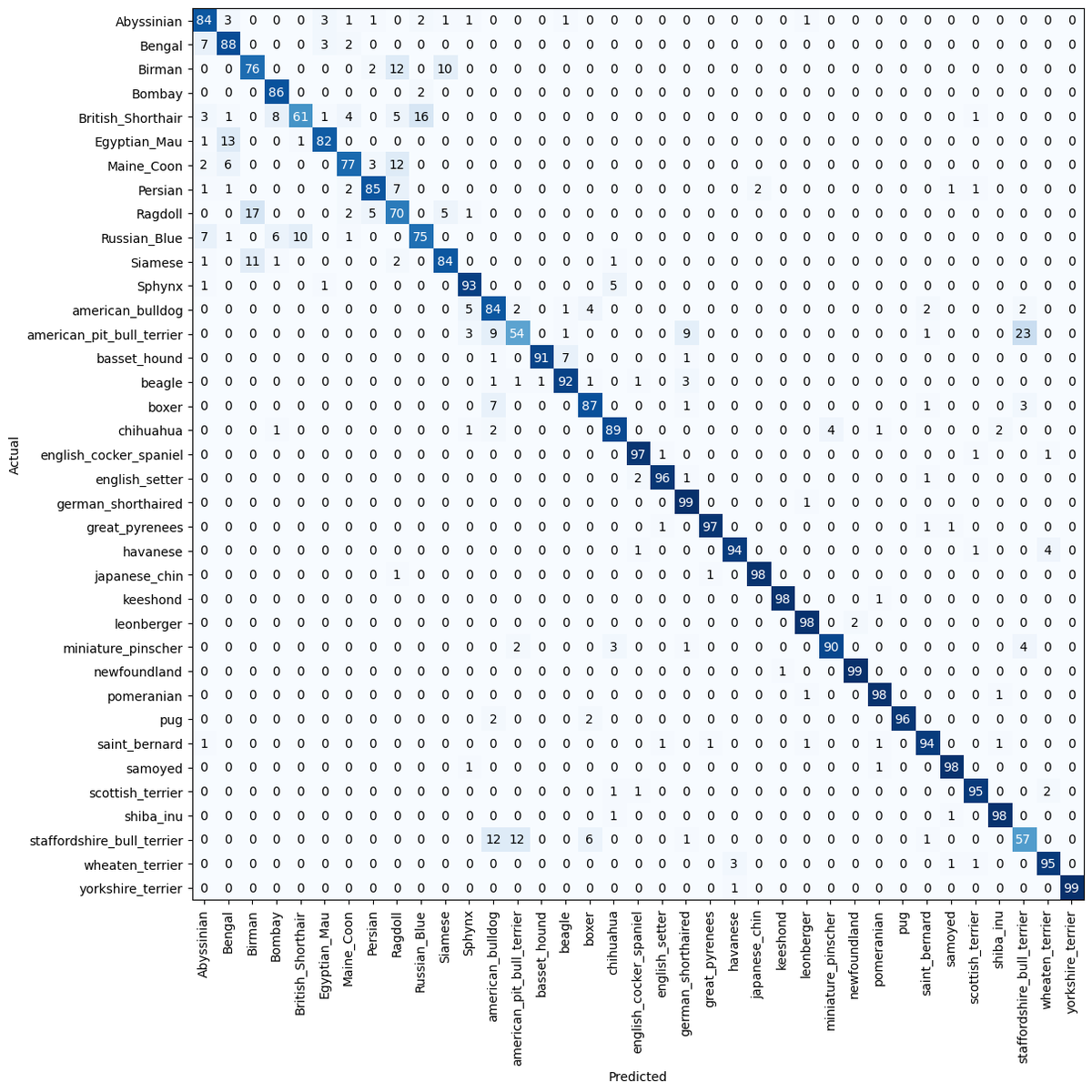
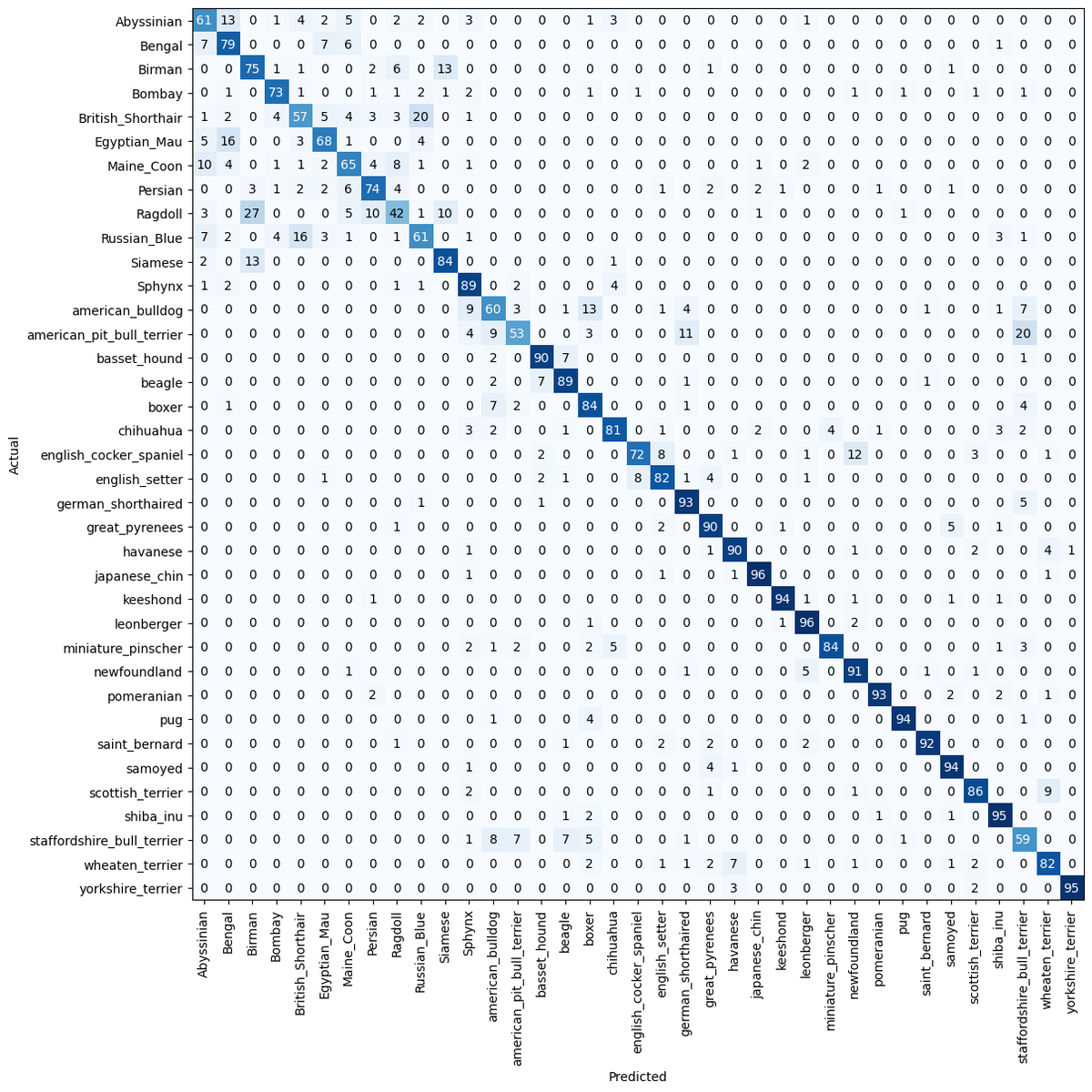
Here are my confusion matrices for vgg and resnet. What's yours?
Up for another challenge, keep your notebook running. You will need your trained networks...🕵️
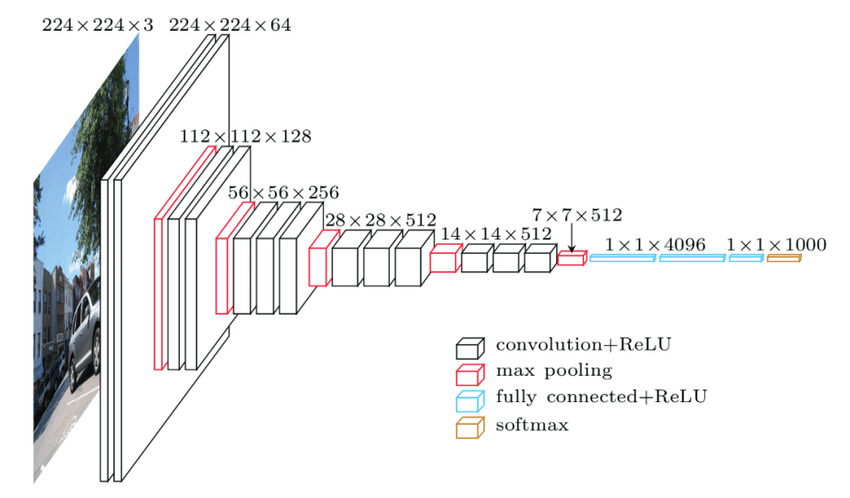
𝗩𝗚𝗚𝗡𝗲𝘁 is a convolutional neural network architecture developed by the Visual Geometry Group at the University of Oxford, proposed in 2014.
This is the architecture we are fine-tuning in 🌻Session 1 of the practical deep learning course 👉
https://t.co/Ka3MAVSABj
Why? 🧵
Starting my 𝗽𝗿𝗮𝗰𝘁𝗶𝗰𝗮𝗹 𝗱𝗲𝗲𝗽 𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗰𝗼𝘂𝗿𝘀𝗲!
🌻 Session 1: Start right away and train a deep neural network on a GPU to classify 🐶 vs😺
This course will allow you to understand papers and codes available online and to adapt them to your own projects 🧵
@mishadavinci Perfect timing! Sharing the tips and tricks for training deep learning models. Course starting this week on Twitter:
https://t.co/pvFwJl25Pi
In 𝘀𝗰𝗼𝗿𝗲-𝗯𝗮𝘀𝗲𝗱 𝗴𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 𝗺𝗼𝗱𝗲𝗹𝘀, generation is done by reversing the SDE perturbing the data. 👇A simple proof explaining the appearance of the score function in the time-reversed SDE. Estimating the reverse SDE can then be done with score matching.
Get ready for a 𝗽𝗿𝗮𝗰𝘁𝗶𝗰𝗮𝗹 𝗱𝗲𝗲𝗽 𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗰𝗼𝘂𝗿𝘀𝗲:
Learn #PyTorch to build and train DL models. By the end of the course, you'll be able to understand and run top-notch DL techniques like transformers, diffusions, NERF, and more...
The good news is you can now access over 30 deep-learning notebooks for self-paced learning and for 𝗳𝗿𝗲𝗲!📚🧠
Check out our materials at👉https://t.co/GxtHvQ7A7C
Stay tuned for helpful solutions and expert tips!
🔥𝗗𝗲𝗲𝗽 𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴: releasing more than 30 𝗻𝗼𝘁𝗲𝗯𝗼𝗼𝗸𝘀 to learn #PyTorch 🌻
👉https://t.co/GxtHvQ87Xa
Starts with the basics (autodiff, convolutions) all the way to attention, transformers, diffusion models, and more to come...
Links to videos and slides included
The denoising diffusion algorithm takes as input the noise schedule and a neural network estimating the mean of the denoiser👇
Here the variance of the denoiser is kept fixed, and better performances are obtained when the variance is also modeled by another neural network.
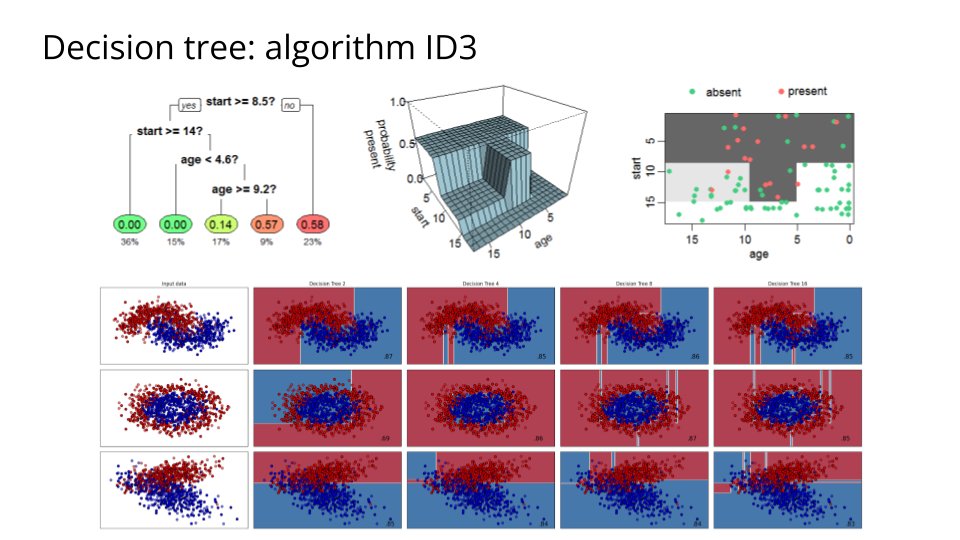
In decision tree learning, 𝗜𝗗𝟯 (𝗜𝘁𝗲𝗿𝗮𝘁𝗶𝘃𝗲 𝗗𝗶𝗰𝗵𝗼𝘁𝗼𝗺𝗶𝘀𝗲𝗿 𝟯) is an algorithm invented by Ross Quinlan (1986) that iterates through every unused attribute and selects the attribute with the largest information gain. https://t.co/FXnbEc3hJh
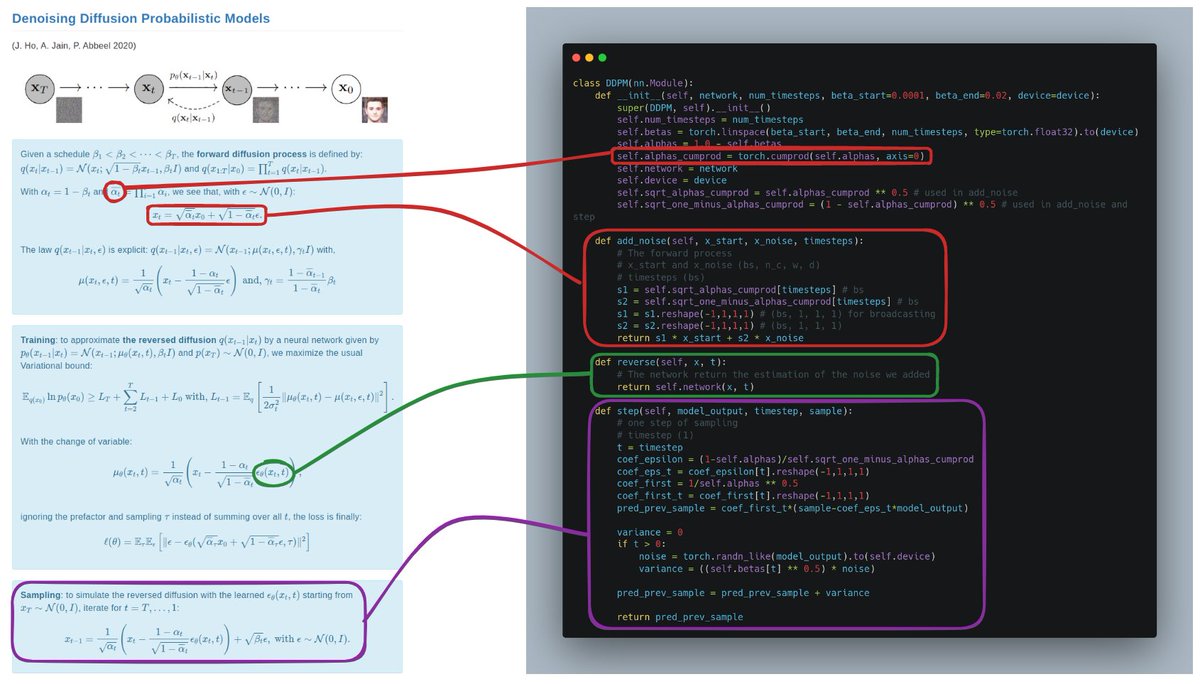
🔥𝗻𝗮𝗻𝗼-𝗱𝗶𝗳𝗳𝘂𝘀𝗶𝗼𝗻 and 𝗺𝗶𝗰𝗿𝗼-𝗱𝗶𝗳𝗳𝘂𝘀𝗶𝗼𝗻: code, train, and finetune your 𝗗𝗲𝗻𝗼𝗶𝘀𝗶𝗻𝗴 𝗗𝗶𝗳𝗳𝘂𝘀𝗶𝗼𝗻 𝗣𝗿𝗼𝗯𝗮𝗯𝗶𝗹𝗶𝘀𝘁𝗶𝗰 𝗠𝗼𝗱𝗲𝗹 from scratch on MNIST, CIFAR and more.
🚢Releasing minimal implementations of denoising diffusions 🧵
𝗗𝗲𝗻𝗼𝗶𝘀𝗶𝗻𝗴 𝗗𝗶𝗳𝗳𝘂𝘀𝗶𝗼𝗻 𝗣𝗿𝗼𝗯𝗮𝗯𝗶𝗹𝗶𝘀𝘁𝗶𝗰 𝗠𝗼𝗱𝗲𝗹𝘀 introduced a new type of generative model (like VAEs, GANS, or flow-based models). Diffusion models are inspired by non-equilibrium thermodynamics, and they learn to generate by denoising.
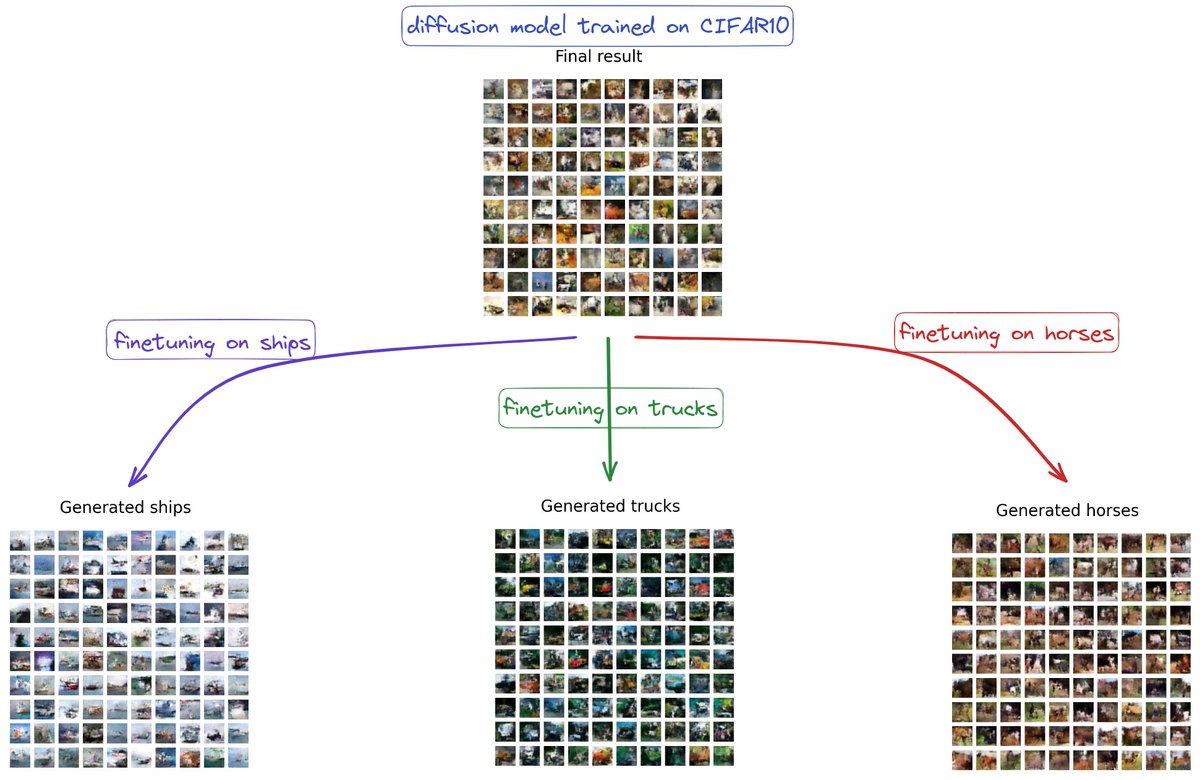
🚢🐎🚚 Ready to play with 𝗗𝗲𝗻𝗼𝗶𝘀𝗶𝗻𝗴 𝗗𝗶𝗳𝗳𝘂𝘀𝗶𝗼𝗻 𝗣𝗿𝗼𝗯𝗮𝗯𝗶𝗹𝗶𝘀𝘁𝗶𝗰 𝗠𝗼𝗱𝗲𝗹𝘀 to generate ships, horses, or trucks!
🔥 Soon releasing course and code to build your own diffusion model and train it from scratch! 🤖
Stay tuned! 🤓
𝗗𝗲𝗻𝗼𝗶𝘀𝗶𝗻𝗴 𝘀𝗰𝗼𝗿𝗲 𝗺𝗮𝘁𝗰𝗵𝗶𝗻𝗴
Perturb data and train a score-based model on the noisy data. For large noise, it improves the accuracy of estimated scores (in low data density regions). With multiple noise perturbations, you get a score-based generative model.
𝗘𝘀𝘁𝗶𝗺𝗮𝘁𝗶𝗻𝗴 𝗶𝗻𝘁𝗿𝗮𝗰𝘁𝗮𝗯𝗹𝗲 𝗽𝗿𝗼𝗯𝗮𝗯𝗶𝗹𝗶𝘀𝘁𝗶𝗰 𝗺𝗼𝗱𝗲𝗹𝘀 𝘃𝗶𝗮 𝘀𝗰𝗼𝗿𝗲-𝗺𝗮𝘁𝗰𝗵𝗶𝗻𝗴
Score = gradient of the log-likelihood. Minimize the expected distance between the scores of the model and the data without knowing the data score👇
𝗔𝘂𝘁𝗼𝗺𝗮𝘁𝗶𝗰 𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝘁𝗶𝗮𝘁𝗶𝗼𝗻: 𝗩𝗝𝗣 𝗮𝗻𝗱 𝗶𝗻𝘁𝗿𝗼 𝘁𝗼 𝗝𝗔𝗫
Backpropagation computes the gradient of the loss with respect to the weights of the neural network.
New course with a numpy functional programming implementation: https://t.co/DVoCxEkQH9
𝗡𝗼𝗿𝗺𝗮𝗹𝗶𝘇𝗶𝗻𝗴 𝗙𝗹𝗼𝘄 𝗠𝗼𝗱𝗲𝗹𝘀: A flow-based 𝗴𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 𝗺𝗼𝗱𝗲𝗹 is constructed by a sequence of invertible transformations, and can learn the data distribution.
✨new course 👉 https://t.co/SxamFcVaqn
🔥 new code 👉 https://t.co/LPLb1mHHYk
A spanning tree chosen randomly among all the spanning trees with equal probability is a 𝘂𝗻𝗶𝗳𝗼𝗿𝗺 𝘀𝗽𝗮𝗻𝗻𝗶𝗻𝗴 𝘁𝗿𝗲𝗲. Graphs have exponentially many spanning trees; 𝗪𝗶𝗹𝘀𝗼𝗻'𝘀 𝗮𝗹𝗴𝗼𝗿𝗶𝘁𝗵𝗺 generates uniform spanning trees more quickly than the cover time.
𝗔* was created in 1968 by Peter Hart, Nils Nilsson, and Bertram Raphael as part of the Shakey project, which aimed to build a mobile robot that could plan its own actions.
A beautiful blog post by @redblobgames with #Python code👉
https://t.co/0MymTLxPQg