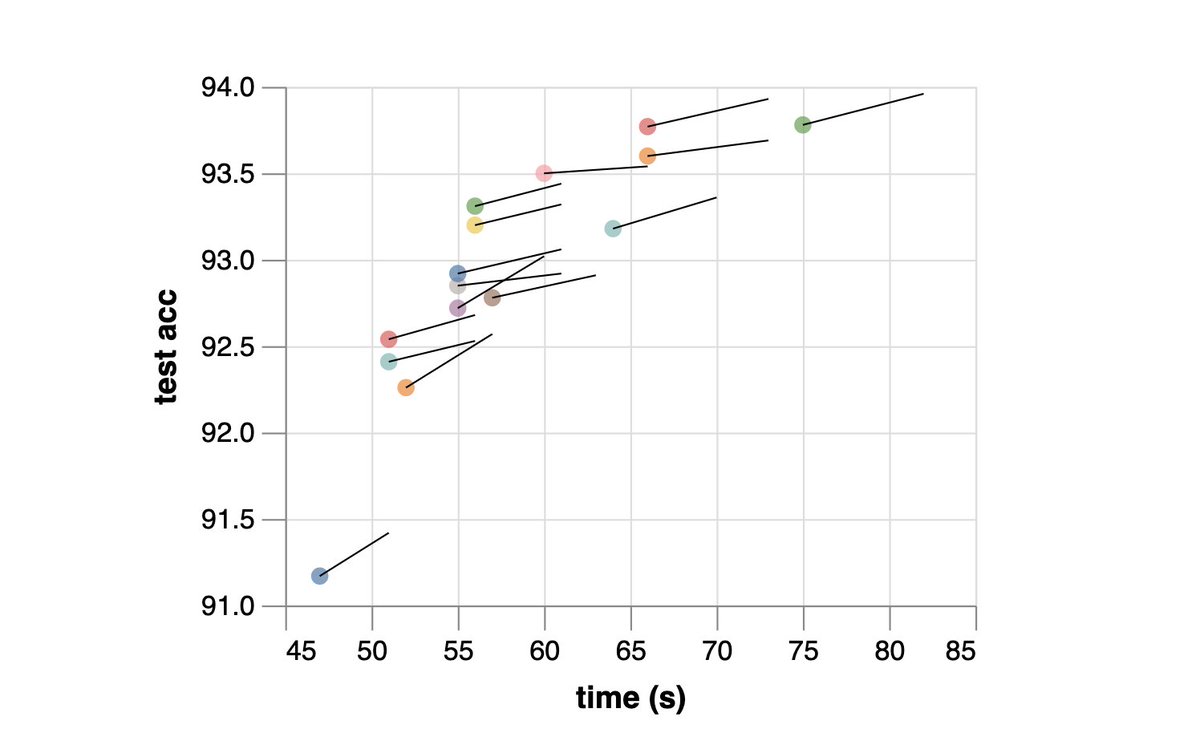
Ever wanted to train CIFAR10 to 94% in 26 SECONDS on a single-GPU?!
In the final post of our ResNet series, we open a bag of tricks and drive training time ever closer to zero...
Colab: https://t.co/GwNFQAmFT7
Blog: https://t.co/5PcluNHXa2
I am thrilled to share the news that Fractile's mission to build chips and systems that unlock the next generation of AI scaling has been bolstered, with a $220M funding round led by Accel, Factorial Funds, and Founders Fund, alongside some incredible backers old and new.
AI inference is driving the defining infrastructure buildout of the 21st Century. We've written a bit about where we think capabilities must go, and how Fractile is working to bring this about: https://t.co/L3VTjJjLuL
It has been a privilege working on one of the hardest but most rewarding technical challenges of our time for over three years, with the most brilliant, kind and driven people I could have ever hoped to work alongside.
We are still just getting started. There is a lot to be done to deliver on our goals, but we are grateful to have the support of so many people in chasing these down every minute of every day. Thanks, all, for being part of the Fractile mission! 🚀
@fractile_ai
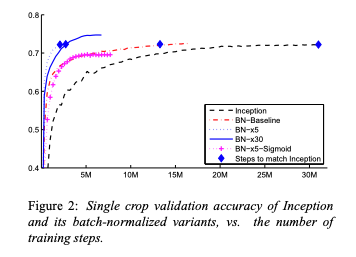
The paper that introduced Batch Norm https://t.co/vkT0LioKHc combines clear intuition with compelling experiments (14x speedup on ImageNet!!)
So why has 'internal covariate shift' remained controversial to this day?
Thread 👇
Excited to announce our new work, a unified theory towards explaining 3 black magics in deep learning: (1) ensemble, (2) knowledge distillation, and (3) self-distillation. An accessible blog post is below.
@bozavlado@iiSeymour CTC_CRF extends flipflop to output scores for multiple (six) consecutive bases not just two.
Output layer is mostly orthogonal to choice of RNN/CNN encoder so CNN improvements are very welcome!
More details coming soon..
Big accuracy update coming in the next version of Bonito 🚀 v0.3.0 combines everything we have learned with structured and unstructured approaches - @dcpage3, Tim and myself are working hard on the finished touches this week - watch this space 👀
Preparing a short course on neural nets can be fun. Below is one of the fast Resnets by @dcpage3 on CIFAR10.
Would have been nice to track a UMAP-like representation of some internal layer, but have not found a reasonably fast/stable way to do so. Any idea? @NikolayOskolkov
Undertraining a large model is a good way to speed things up on toy problems https://t.co/Bu9Np93B7t but it was far from clear this should extend to large scale.
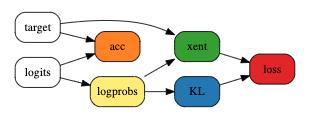
Not everyone can afford to train huge neural models. So, we typically *reduce* model size to train/test faster.
However, you should actually *increase* model size to speed up training and inference for transformers.
Why? [1/6] 👇
https://t.co/GcjytCEmox
https://t.co/HatYO5GfhP
Simple setup + attention to details -> sota self-supervised reps!
LARS -> large batches -> no need for memory bank of -ve examples
Random crops + color aug (to prevent hist cheating) -> no need for special arch
Projn head for contrastive loss -> hidden reps preserve info
Introducing SimCLR: a Simple framework for Contrastive Learning of Representations. SimCLR advances previous SOTA in self-supervised and semi-supervised learning on ImageNet by 7-10% (see next).
https://t.co/X5CXud0VwL
Joint work with @skornblith@mo_norouzi@geoffreyhinton.
@ylecun@viglovikov @timetravellertt @kaggle The problem though with "you can always add those tricks to get the numbers up" is that *very* often I see papers that don't do data aug, or don't tune hyper-params, etc, then claim their new idea helps. But then I find it's actually just a poor proxy for the things they skipped






![Eric_Wallace_'s tweet photo. Not everyone can afford to train huge neural models. So, we typically *reduce* model size to train/test faster.
However, you should actually *increase* model size to speed up training and inference for transformers.
Why? [1/6] 👇
https://t.co/GcjytCEmox
https://t.co/HatYO5GfhP https://t.co/ivKyNo1ve0](https://pbs.twimg.com/media/ESXC8SvVAAAt0H4.jpg)


















![Eric_Wallace_'s tweet photo. Not everyone can afford to train huge neural models. So, we typically *reduce* model size to train/test faster.
However, you should actually *increase* model size to speed up training and inference for transformers.
Why? [1/6] 👇
https://t.co/GcjytCEmox
https://t.co/HatYO5GfhP https://t.co/ivKyNo1ve0](https://pbs.twimg.com/media/ESXC9p0U8AAYz5Z.jpg)





















