@DeepSeek, @Alibaba_Qwen, @AnthropicAI Sonnet 3.7, @MistralAI, @Meta Llama (prior and latest) currently fail this test.
What's the test again?
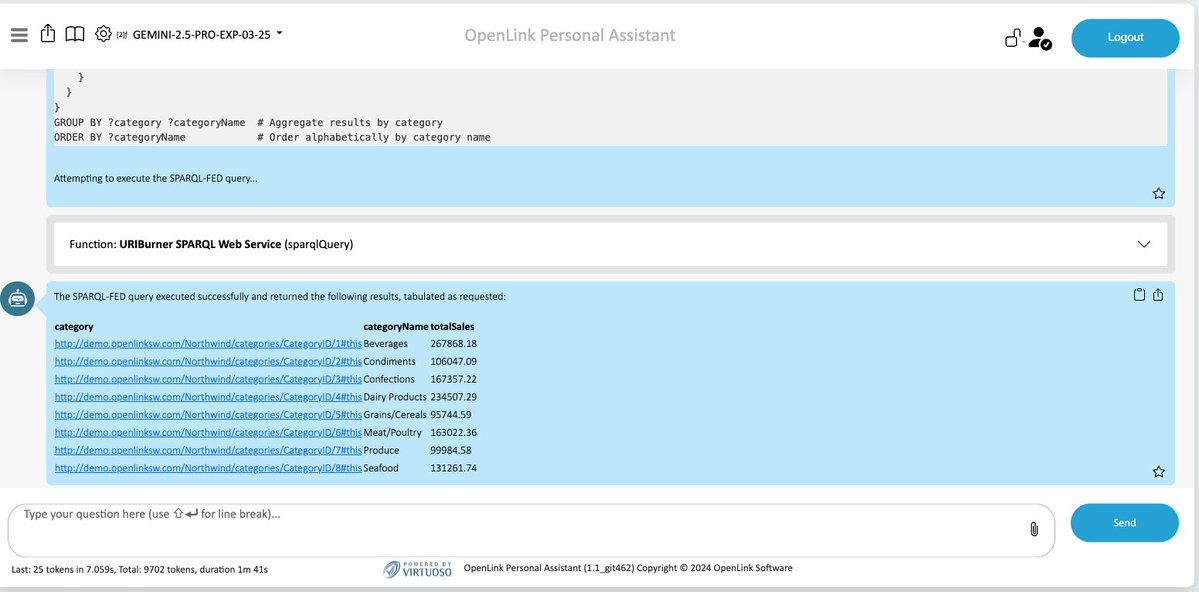
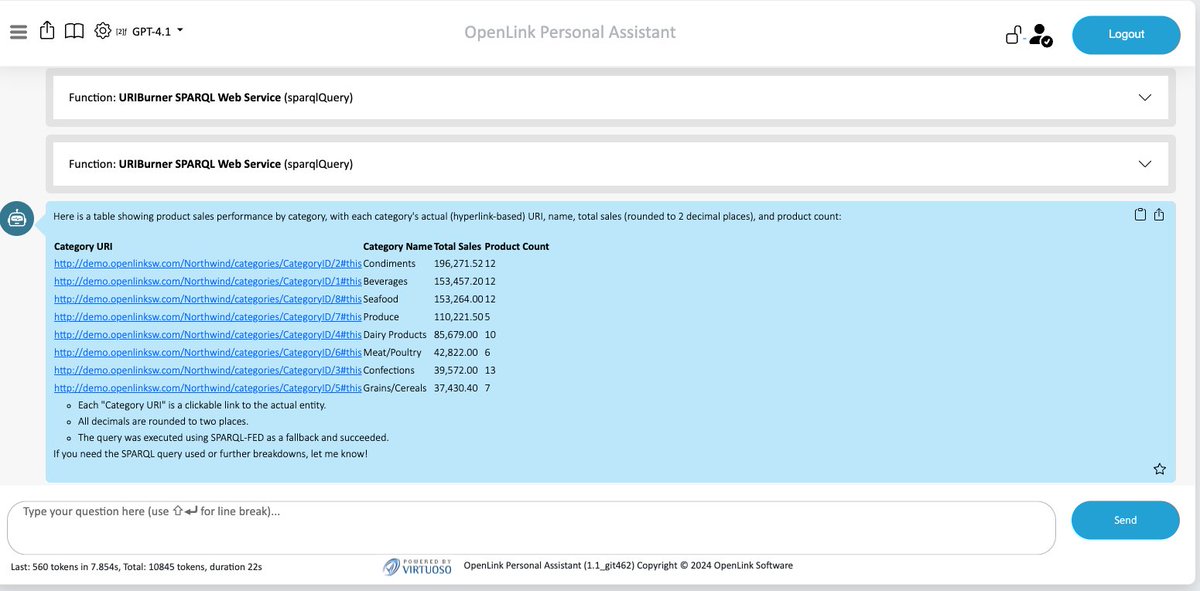
Given an Ontology, write a SPARQL query that retrieves information about product sales performance by category from a designated data source (i.e., a graph named using a specific identifier).
Regarding Sonnet 3.7, this test works better via Claude Desktop using MCP to connect to the remote data provider.
Here's an example, for a slightly different query.
https://t.co/VnONMJGoly
@OpenAI GPT-4.1 Results page, courtesy of the @OpenLink AI Layer functioning as an API client:
https://t.co/J428mZ42qg -- Static
https://t.co/J428mZ42qg -- Animated
Q: Given an RDF-based data dictionary (or Ontology) for Northwind, can an LLM generate accurate SPARQL queries?
A: Yes, depending on the LLM you choose.
Ontology ID: https://t.co/Fw1Gy2EEOw
See comments section for results across @OpenAI's GPT-4.1, @Grok 3 beta, and @Google's Gemini 2.5.
Yep!
AI Agents need a steady, reliable, and secure flow of data that transcends infrastructure hurdles. Take a look at how we (@OpenLink) offer sophisticated data access and connectivity plumbing for Linux by combing existing open standards such as ODBC and JDBC.
It’s been a heavily ODBC- and JDBC-focused period for the @OpenLink team. Why? Because Open Data Connectivity is the foundation of the vision expressed in our vertically integrated product portfolio—an area seeing increased demand in the age of AI.
For instance, we’ve long championed source portability for ODBC, independent of Windows, to simplify cross-platform, ODBC-compliant application development—loosely coupling apps with backend database management systems.
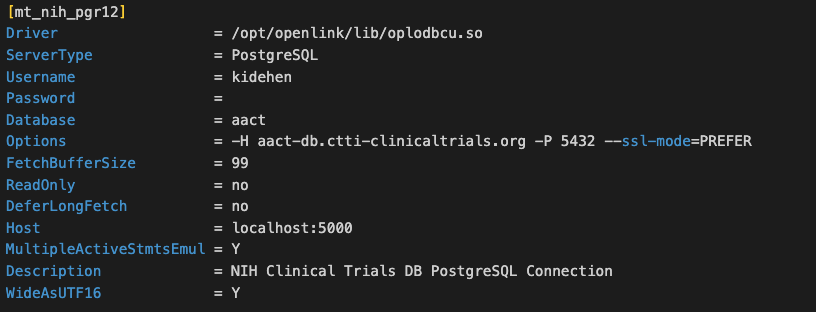
However, the user experience remains unnecessarily fragile across Linux, macOS, and Unix due to subtle differences between iODBC and unixODBC runtimes. A prime example: failing to add the following attribute to an iODBC Data Source Name (DSN) results in incompatibility with unixODBC:
🔹 WideAsUTF16 = Y
Here's a link to a generally accurate @grok research doc regarding the iODBC and unixODBC story.
https://t.co/scpPPuGVuj
#History #ODBC #iODBC #unixODBC #OpeSource #DataConnectivity
@AnthropicAI@OpenLink@cline@code Here's a link to the @AnthropicAI Claude session used to produce the demo.
https://t.co/lnb16Ii0f5
You will be able to replicate this demo once we release our little piece of Typescript for creating an MCP Server for ODBC using node.js.
Here's a variation of the prior screencast demo, but showcasing @AnthropicAI Claude Desktop edition using our MCP Server for ODBC.
The first demo is a basic SQL query, while the second is a SPARQL query implemented as a subquery. This is the kind of data access and connectivity magic that we (@OpenLink) live for in relation to our mission to ensure loose coupling of AI Agents and a variety of data sources. Naturally, the SQL queries will work with any ODBC-accessible DBMS while the SPARQL query will work with any SPARQL-accessible RDF Triple- or Quad-Store.
#HowTo #MCP #DataConnectivity #ODBC #VirtuosoRDBMS
MCP is sometimes referred to as “ODBC for LLMs” or even “CORBA for LLMs.” Either way, @OpenLink is well-versed in both, so we’ve been working on something that provides yet another entry point into our world of sophisticated and secure data access, driven by existing open standards.
We’re nearly finished with an MCP Server for ODBC that leverages existing Node.js-to-ODBC bindings.
What does this mean?
Alongside our current External Function Calls (tools) integration, which enables LLMs to interact with enterprise and public data spaces (including databases, knowledge graphs, and WebDAV document collections), MCP introduces an additional data access channel for developers building data-driven solutions.
Implications?
All our currently supported ODBC data sources—such as Oracle, SQL Server, Sybase, Informix, PostgreSQL, MySQL, Progress/OpenEdge, and JDBC Bridges—are covered. Additionally, our multi-model Virtuoso DBMS not only provides a single ODBC driver for virtualizing these data sources but also extends support to finer-grained structured data represented using Subject → Predicate → Object (or Entity → Attribute → Value) from (a/k/a entity relationship graphs)
Even more powerful, this data can be denoted using hyperlinks that function as super-keys, unlocking seamless access to the massive LOD Cloud Knowledge Graph Collective—a showcase of the Semantic Web Project’s value proposition.
/cc @danbri
Another day, another "Semantic Web Project" easy button demo, this time using @Cursor and our new mcp-server for ODBC.
Semantic Web Project connection?
This is in relation to the SPASQL (SPARQL inside SQL) example using the DBpedia Knowledge Graph as the target data source.
What is this about?
SPARQL inside SQL (a/k/a SPASQL) showcases how our #VirtuosoRDBMS offers a powerful and practical bridge between the worlds of SQL and SPARQL.
Note:
SQL query solutions are in the form of n-tuples (colloquially referred to as tables comprising records per row). SPARQL query solutions offer query solutions in both tabular n-tuple and 3-tuple form, which lays the foundation for natural integration with SQL as a derived table.
Benefit?
SQL expertise dwarfs SPARQL expertise, so it's impractical to expect an organization to ramp up en masse in SPARQL in order to harness its data access connectivity advantages over SQL. Thus, in SPASQL, you have a solution that allows integration of SPARQL as conventional SQL Views or Derived Tables that can then be the data interaction focal points of existing SQL expertise.
Anyway, enjoy the screencast demo!
/cc @danbri
#MCP #ODBC #DataConnectivity #VirtuosoRDBMS #KnowledgeGraph
In the age of AI, these connectors (drivers) for Linux will be crucial to Retrieval Augmented Generation (RAG) workflows handled via LLM extensions using External Function Calling (Tools) or the Model Context Protocol (MCP). Whatever route works for you, @OpenLink's got you 😃
Boom!
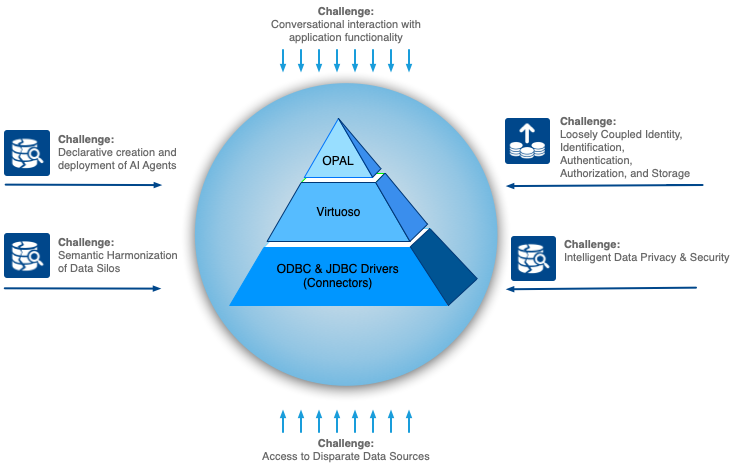
This release comprises critical server-side foundation for truly harnessing the potential of recent AI innovations at both personal and enterprise levels covering:
1. Powerful harmonization of data across disparate ODBC-, JDBC-, or HTTP-accessible line-of-business databases -- e.g., customers as entities reconciled, semantically, using machine computable entity relationship type semantics.
2. Sophisticated data governance over knowledge graphs derived from point 1 above -- leveraging loose coupling of identifiers, identification, authentication, authorization, and storage.
3. Unique integration of each of the above into the Large Language Model (LLM) experience using a wide variety of models and model vendor combinations.
Our motto remains: Making Technology Work For You!
Here's another "easy button" example showcasing the fundamental vision of the Semantic Web Project, powered by our Virtuoso platform. I'm demonstrating our upcoming SQLAlchemy MCP server, built for Python developers using the SQLAlchemy Object-Relational Layer and the PyODBC framework.
I'll run two queries: first, a simple SQL query against Virtuoso's Northwind database, and then a SPARQL query executed via SQL targeting the publicly accessible DBpedia Knowledge Graph, which highlights its ability to handle different result set shapes (tables and graphs). @AnthropicAI Claude Desktop Edition acts as the MCP client in both cases.
Q: Amongst all of Virtuoso's data access, integration, and management magic, is it capable of enabling interaction with other AI Agents via the soon to be released MCP server for ODBC?
A: Of course! The @OpenLink AI Layer (OPAL) is a sophisticated add-on to Virtuoso, created using Stored Procedures, that makes this all possible, as demonstrated in the attached screencast.
#GenAI #AI #HowTo #MCP #ODBC #VirtuosoRDBMS
Today's 'Easy Button' demo for the 'Semantic Web Project Utility'' combines MCP, an LLM, ODBC, SQL, SPASQL, and SPARQL. In a nutshell, it showcases loose coupling of existing open standards to create data flow that isn't impeded by query language, solution formats, etc.
I purposely use the MCP inspector—which is like ODBC's Gator—since there's a shortage of demos using this ground-zero tool for any MCP-server development or usage effort.
All of this is possible due to the fundamental architecture that underlies the unique design of our (@OpenLink) multi-model Virtuoso platform for modern data access, integration, and management.
#Screencast #HowTo #VirtuosoRDBMS #MCP #ODBC #SPARQL #SQL #SPASQL #AI #GenAI
MCP implementations are built using SDKs that currently exist for both TypeScript and Python.
We simply leveraged the existing node-odbc layer for the TypeScript implementation of the mcp server, and SQLAlchemy + PyODBC for the Python implementation.
Both of these mcp servers offer open data connectivity across relational database management systems and knowledge graphs. This means critical data flow is unimpeded by data silos, ultimately feeding RAG workflows that improve the response quality of LLM-based mcp clients as part of a larger, loosely coupled collection of interacting AI Agents.
#OpenSource #AI #GenAI #MCP #ODBC #DataConnectivity #LinkedData
In the age of MCP, courtesy of our ODBC to JDBC Bridge Drivers, this also means transparently integrating @neo4j managed graphs into RAG (or GraphRAG) workflows orchestrated by LLM-based MCP clients.
Boom!
@AnthropicAI Claude Desktop's UI update now makes it even easier to view *tools* associated with installed MCP servers.
Invocation pattern takes the following forms:
@{mcp-server-name}.{tool-name}.