Our NeurIPS paper is published on arXiv.
In this paper, we propose a new optimizer ADOPT, which converges better than Adam in both theory and practice.
You can use ADOPT by just replacing one line in your code.
https://t.co/6kMDGAd8QF
"Innovative and open-source visualization application that transforms various data formats, such as JSON, YAML, XML, CSV and more, into interactive graphs."
"Make sure that your model can overfit on small training set" might be the single best sanity check when building ML models. It helped me solve countless implementation errors and to better understand capacity. I first heart it from @fchollet, thanks!
Learning ID-free Item Representation with Token Crossing for Multimodal Recommendation
Represents items using learnable multimodal tokens instead of IDs, achieving better recommendation performance with only 20% of parameters compared to ID-based methods
https://t.co/2hIuLpcvTS
@Frenck I updated one device managing my SDN last night and a bunch of morning routines failed this morning until plugs and switches were power cycled 🤦♂️
Having Medicare cover in-home care for the elderly is the single most substantive (and, I think, materially beneficial) policy proposal either candidate has offered in this race, and as far as I can tell, it's gotten almost no attention from the press, or on social media.
We have solved a long-standing issue with local (per node) IDF/significance computations.
Introducing a global IDF model, plug-and-play with Vespa. Now, it is also much more relevant for Vespa streaming mode, which doesn't build an index.
Read more at https://t.co/WRV1VNtaZT
Model2Vec distills a fast model from a Sentence Transformer by passing its vocabulary through the model, reducing embedding dims via PCA and applying Zipf weighting.
Inference with the resulting static embeddings are lightning-fast, e.g. 10k texts/sec:
https://t.co/gRUZ83Pf2Y
🧵
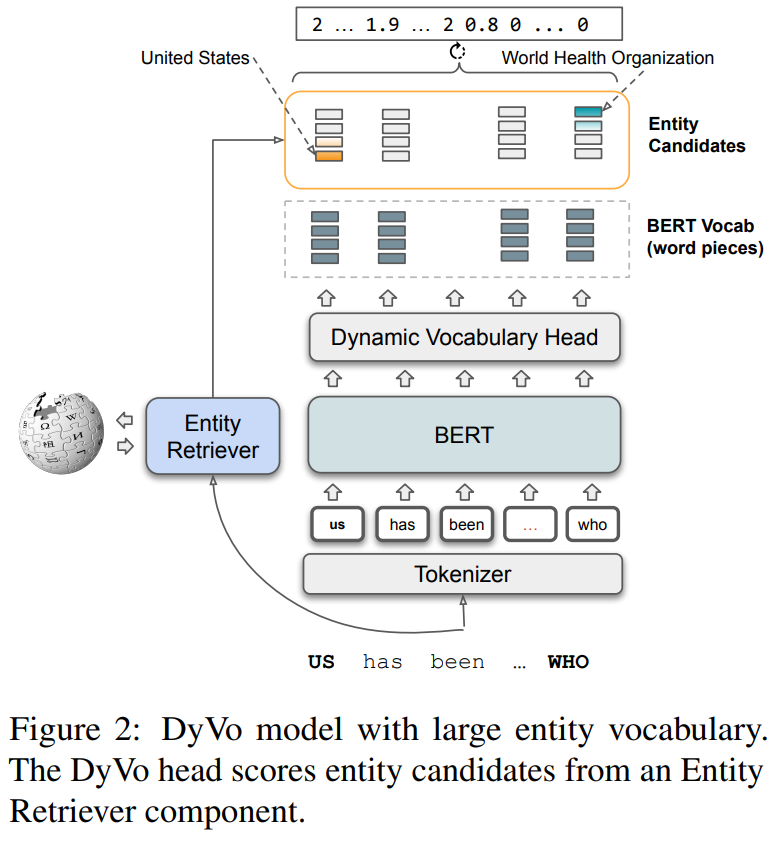
DyVo: Dynamic Vocabularies for Learned Sparse Retrieval with Entities
Enhances Learned Sparse Retrieval by incorporating Wikipedia entities, addressing limitations in handling complex vocabulary and improving retrieval.
📝https://t.co/QaokpKcQpk
👨🏽💻https://t.co/9Yq7CTvKdC
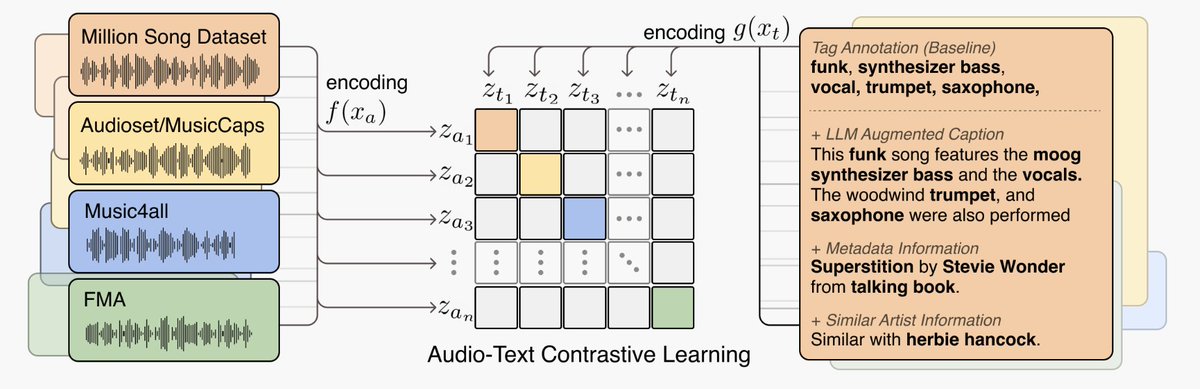
A joint embedding model that leverages a fine-tuned LLM to handle music descriptions from various datasets has been released. In addition to semantic queries (genre, instruments, mood, theme), it also supports metadata similarity queries for music search."
Man sits by me on train.
MAN: Loads of psychopaths around here
ME: Really?
MAN: Loads mate
ME: How'd you know?
MAN: There's signs aren't there?
ME: I guess?
MAN: I love them
(47 minutes of awkward silence.)
Man leaves train, he has a bike. I realise he was saying 'cycle paths'.
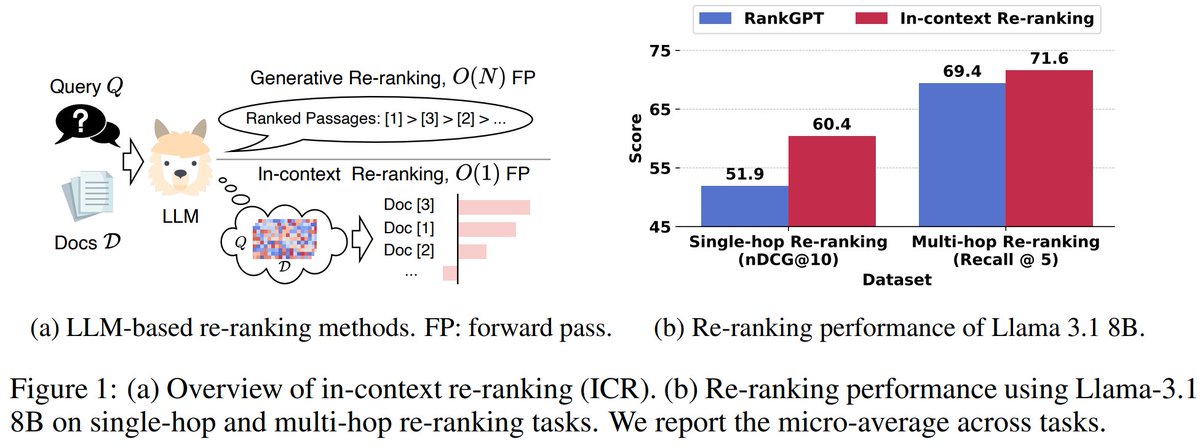
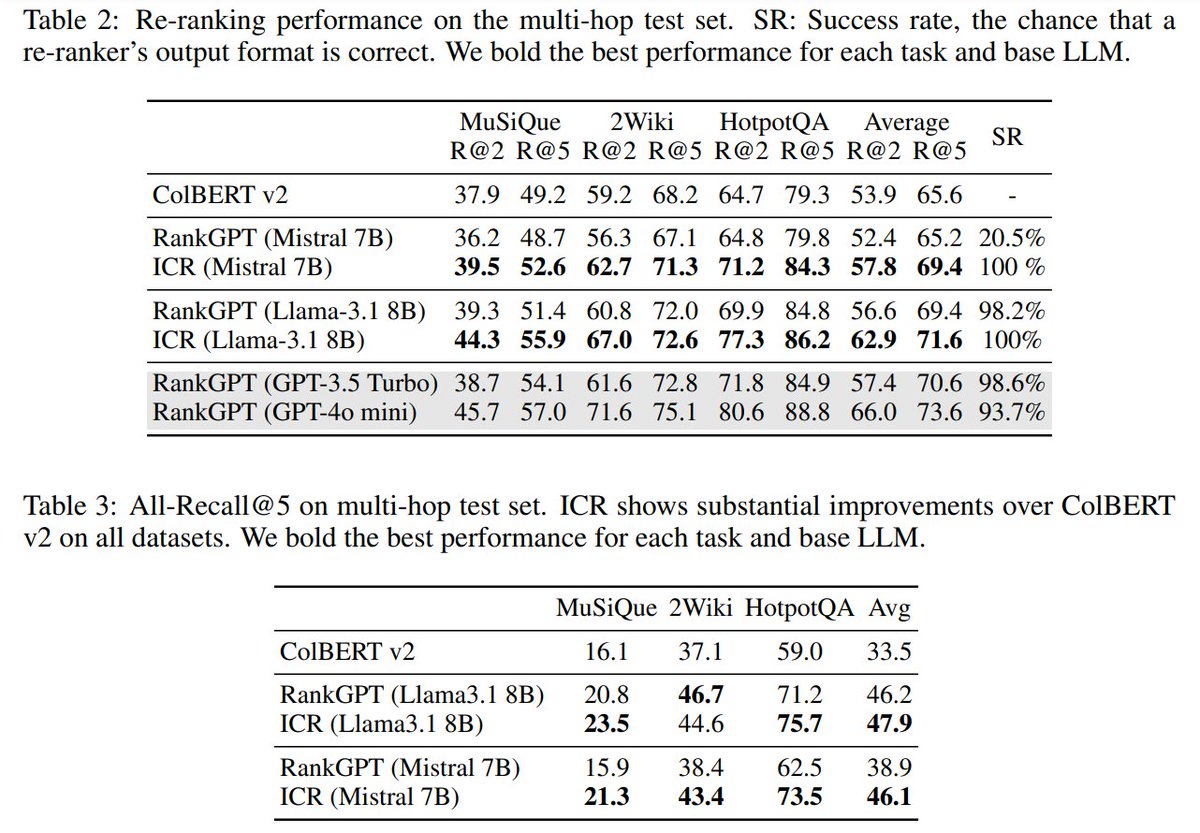
Attention in Large Language Models Yields Efficient Zero-Shot Re-Rankers
Uses LLMs' attention patterns instead of generation, outperforming existing approaches on complex retrieval tasks while significantly reducing latency.
📝https://t.co/AISKhrONNw
👨🏽💻https://t.co/aGrpfF26TU
Seriously impressive: patent troll blackmails Cloudflare claiming they are infringing on 4 BS patents in 100 use cases. Cloudflare goes to court, and proves they don't infrige on anything from the BS patent, and has ALL the patent troll's patents donated to the public!