Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
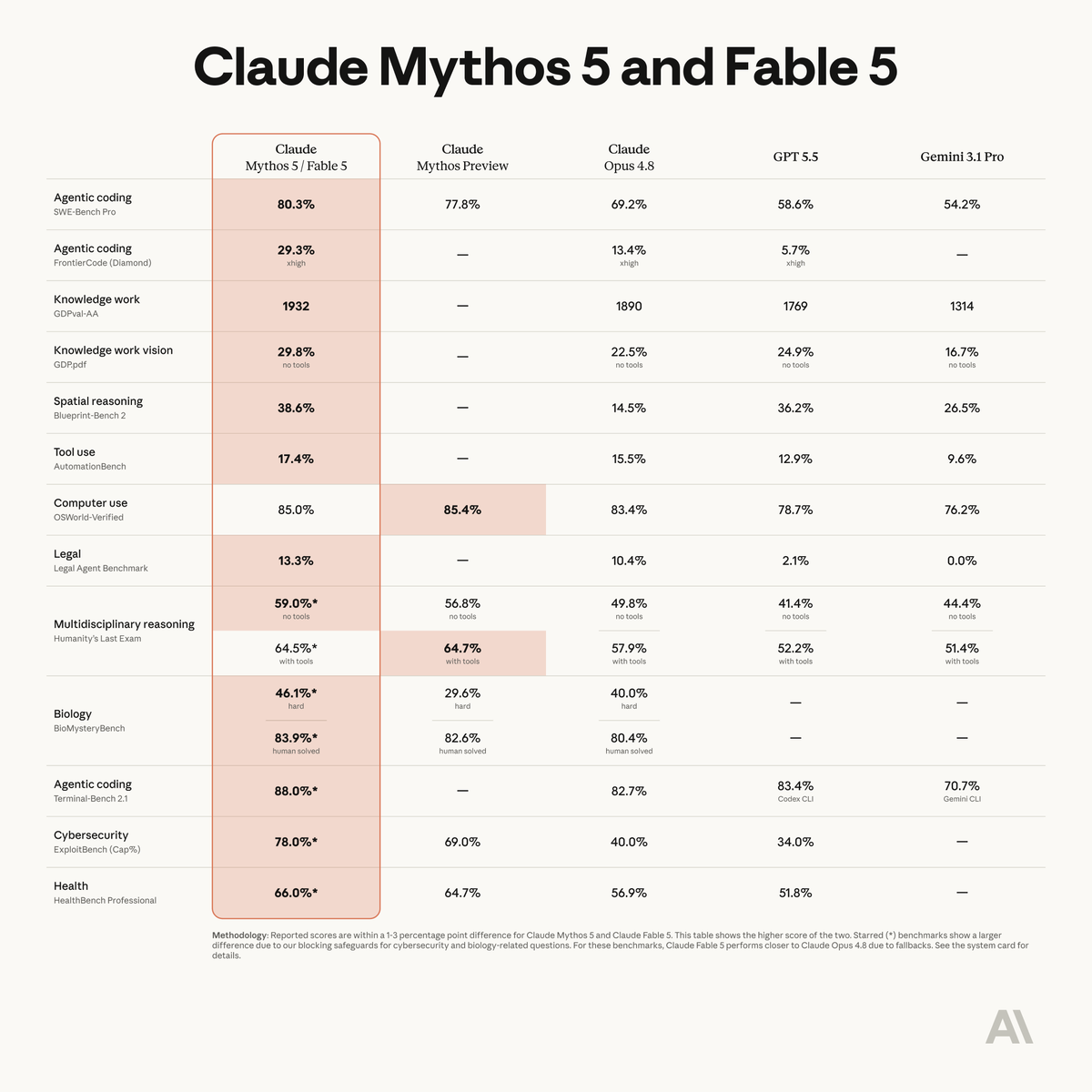
Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
Anthropic has confidentially submitted a draft S-1 registration statement to the Securities and Exchange Commission.
Pending completion of SEC review, this gives us the option to pursue an initial public offering.
Read more: https://t.co/onGZAhRLvD
Claude Opus 4.8 takes the lead on the Artificial Analysis Intelligence Index at 61.4, with Anthropic retaking the #1 spot on GDPval-AA and advancing in terminal use and scientific reasoning
To reach the leading position on the Intelligence Index, @Anthropic made large improvements in both real-world agentic work and frontier academic reasoning tasks.
Key takeaways:
➤ Claude Opus 4.8 is the new leader on the Artificial Analysis Intelligence Index. Opus 4.8 scores 61.4, up +4.1 points from Opus 4.7 and +1.2 points ahead of GPT-5.5 (xhigh), the previous Index leader
➤ The new release is slightly more efficient than its predecessor on agentic tasks, but token efficiency varied by task type. We saw Opus 4.8 use fewer turns and output tokens on GDPval-AA, but approximately the same number of output tokens for the overall Intelligence Index to achieve significantly higher performance.
➤ Anthropic retakes the lead on GDPval-AA, our primary evaluation for agentic performance on knowledge work tasks. Opus 4.8 scored an 1,890 Elo, reflecting an implied win rate of approximately 67% against GPT-5.5
➤ Claude is now among the top models for scientific reasoning. Previous releases have trailed peers on complex academic reasoning tasks, but with Opus 4.8, Claude sits slightly ahead of OpenAI and Google as the leader on Humanity’s Last Exam. It also scores higher than Gemini 3.1 Pro on CritPt, a frontier physics benchmark, but remains behind GPT-5.4 and GPT-5.5
➤ Claude Opus 4.8 reaches #2 on AA-Omniscience, slightly ahead of Opus 4.7. Opus 4.8 scores 27.4 on the AA-Omniscience Index behind only Gemini 3.1 Pro (32.9). Accuracy ticked up slightly to 46.6% and hallucination rate held roughly flat at 35.9% - Anthropic continues to demonstrate substantially lower hallucination rates than peer models from Google and OpenAI
➤ Compared with Opus 4.7, Opus 4.8 also makes material gains on Terminal-Bench Hard (+6.8 points), τ²-Bench Telecom (+5.9 points), and IFBench (+3.6 points), with relatively flat scores across AA-LCR, GPQA, and SciCode.
Other key model details remain the same as Opus 4.7:
Context window of 1 million tokens (equivalent to Opus 4.7)
Pricing of $5/$25 per million tokens of input/output; cache pricing remains at a 25% premium for cache writes ($6.25 per million tokens) with 5-minute time to live, and 90% discount for cache hits ($0.5 per million tokens)
Effort remains the recommended way of configuring model performance and latency, with the same options as Opus 4.7 - we measured the model at its ‘max’ effort setting to test peak performance
Claude for Excel, PowerPoint, and Word are now generally available, and Claude for Outlook is in public beta.
As Claude moves between your Microsoft apps, it carries the full context of your conversation.
How do people seek guidance from Claude?
We looked at 1M conversations to understand what questions people ask, how Claude responds, and where it slips into sycophancy. We used what we found to improve how we trained Opus 4.7 and Mythos Preview.
https://t.co/6tjY58uBhk
I love how easy it’s becoming to learn on the go with podcasts in Copilot.
I turned GitHub’s latest Octoverse report into a 5-minute pod — short, smart, and snappy. Packed with info on the seismic shifts happening in how people build software. Check it out!
Been playing around with the new Mico voice assistant inside Microsoft Copilot and I found a little easter egg. I love that the people building this stuff are still finding ways to add a bit of fun and nostalgia into what they're building. Kudos to Microsoft on this one!
Meet our third @MicrosoftAI model: MAI-Image-1
#9 on LMArena, striking an impressive balance of generation speed and quality
Excited to keep refining + climbing the leaderboard from here!
We're just getting started.
https://t.co/33BiNfIjPg
Learning just leveled up: eligible college/uni students can claim extra access to Copilot Podcasts, Deep Research, and Vision w/a Microsoft 365 Personal subscription, free for 12 months.
1 year, 1 subscription, countless lightbulb moments
Claim by 10/31: https://t.co/FwKUcSbP3o
Good news @Copilot users! With Deep Research, you get 5 free research reports a month for complex, thorough analysis + deep dives. For the extra curious, you can get even more with Copilot Pro.
Free access available in all Copilot countries + languages, on mobile, web + Edge.
Today is a big step towards an AI browser: Copilot Mode in Edge, built for how your brain actually works. Voice control, no digital clutter, and multi-tab context, all grounded in privacy and security. Try it at https://t.co/YDKCpbdX86 + feel the difference of 🧵
Super excited to share our new Microsoft AI site! What we're building, who we are, our philosophy, and open roles, all in one spot. We're always looking for great new teammates, so take a scroll (and do play around with the hover on the homepage) https://t.co/cADYpgDiXu
What a breakthrough! Published in Nature today, this is "a new state of matter" to power the first topological qubits. With scalable quantum computing, we'll soon be able to solve previously impossible problems in chemistry, biology and life sciences. Truly exciting times. Congratulations @Dr_Chetan_Nayak, Zulfi Alam, Dr. @MatthiasTroyer, Dr. @krystasvore, and the @MSFTQuantum team.
Today we’ve made Think Deeper free and available for all users of Copilot.
This now gives everyone access to OpenAI’s world class o1 reasoning model in Copilot, everywhere at no cost.
I urge you to give it a try. It’s truly magical. Think Deeper helps you:
Today we announced major updates to Copilot, including new Voice, Vision, and Reasoning capabilities. 🌟 Very proud of the team's hard work getting this out to users!
Microsoft is launching a new redesigned Copilot this morning. It incorporates the new Voice and Vision interface as well as 'Think Deeper' which uses Chain of Thought. The new version is more personable, and agentic. They are promising it will ultimately 'act on your behalf'.